↧
How's my SSL?
↧
Fits and Starts — Ben Horowitz explained
Comments:"Fits and Starts — Ben Horowitz explained"
URL:http://fitsnstarts.tumblr.com/post/72678355503/ben-horowitz-explained
Ben Horowitz explained
This post can be annotated on Rap Genius HERE
“They tryna blackball me, don’t wanna see me win
Hit after f*%kin’ hit, like there we go again
They say I’m underrated, I’m just misunderstood
They can’t compare to me, I wish, I wish you would”
- “Blackball” by DJ Khaled (feat. Ace Hood, Future, Plies)
There are times when you must publicly speak up about what’s on your heart, and this is one of those times for me.
Perspective:
To understand Ben's importance, you must first understand how Silicon Valley is run, and that is by a very specific protocol. There are kings (notable investors), king makers/fool makers (influential media), connectors (hyper networked individuals), and actors (founders) that revolve around the deals. Silicon Valley runs on the perception of those inside those deals and those on the outside looking in. If you are not properly situated somewhere in the ecosystem, then your company will not get funded or you will not get access to a hot deal that is being funded that you would like access to as an investor.
In this instance the valley is not unlike DC. The aforementioned above run their ecosystem in almost exactly the same way, and that is by using a sort of currency to get around. This currency is measured in factual insider information, publicly misleading untruthful information, favors, and the power of name brand people. It is populated by climbers and star fuckers (sorry if that language offends), and it is all about who is hot or now. It is also populated by some of the most optimistic, interesting, and bright minds in the world. Good people. Ben Horowitz, is one of these good people, and perhaps one of the most.
You must also consider culture and its importance in shaping markets and in its ability to create social stigmas and/or social acceptance. Alpha culture dictates what success “looks like”. For so long hip hop culture has been the culture of poor people. The art of beta culture. An oddity that voices the raw emotion of the poor, and that glorifies the suboptimal traits that keeps poor people from mobilizing up the ladder in society. To outsiders, that’s all it is. But by using his voice and stage to elevate rap as a useful medium for informing business, it is creating a legitimacy in the business world for this culture and those that come from it.
Micro:
I have grown to form a tight bond of friendship with Ben. In the course of two years have grown to trust him immensely as one of my closest friends. I value his input immensely. I also respect what he is, and what he is not.
Ben invested in my company AgLocal in 2011, I did not know him previously to pitching him, I barely knew my head from my ass as an entrepreneur, I had no track record as an entrepreneur, I was not from the valley and did not attend any Ivy or MIT so I had no network, and there was nothing inherent or obviously valuable that I could offer to Ben. However, and this is important to note, Ben looked past all of that and decided to take me on as a mentee and subsequently helped me raise a seed for my company also.
He saw a guy from the midwest with an idea and immediately understood what I was trying to accomplish, and understood that my background was just as important to my startup as are the background of some folks who have backgrounds at an Ivy, Stanford, MIT. He went on to not only invest money but invest time in my learning and in helping me to build my network. This is absolutely antithesis to the way the valley works as described above.
The typical way that diversity is handled in the valley is that the most visible voices are publicly outspoken about how inclusive they are, and in my private experience around many of them, they are typically full of shit. They do not know anything about me and those like me or know anything about the culture where we come from, so how can they introduce this culture? If they were being honest, many of these folks would probably admit that they don’t really have a clue and don’t give a shit about it all in reality. In the opposite, Ben has spent the time and does the work, actually gives a shit and ironically doesn’t crow about all of this publicly. You never hear him talking publicly about his friends and his work in the ecosystem for applause. He just is who he is, and I learned that very early on.
Anecdotes:
At the height of the Series A crunch, my team and I went into Andreessen Horowitz to pitch an ‘A’ to both Ben and Jeff Jordan. We were a couple of months from being out of cash. After a tough but fair meeting, we thought we had landed a16z as a lead. I was way off. Ben had the unenviable task of calling me up and telling his friend, “no, we are not going to participate or lead an A round at this time”. You would think this was a hard thing, well it was, but it was also a time of great trust building between us. I felt more included as a real founder in that no, than I felt at the time he said yes to our seed round. I became a better CEO because of it.
One Sunday, Ben invited me to breakfast with him at his favorite place. Was it Los Altos or Palo Alto or Pac Heights? No, it was in the old neighborhood that he grew up in. In the east bay on the border of Berkeley and Oakland. A working class neighborhood, primarily black and Latino, you could even call it “the hood” if you wanted to. I did, and I did so lovingly. The place we went to was a hole in the wall breakfast place, everyone working or eating there was from the neighborhood and all of them knew Ben right away. He is still a regular. You see he never forgot where he came from. That morning we were joined by one of the most recognizable founders of one of the most high profile companies in the valley. He drove from the south bay to see Ben here, just to talk to Ben and get advice. Did Ben tell me and the other nobodies to leave while he listened to the hard management decisions this rising CEO had to make? No, he let us sit there and listen, and for me as a new CEO I learned a lot that day. I of course learned from the advice I heard given out, but I also learned that truly reaching the stars means never letting your earth go. Be who you are and project where you came from no matter what as it is the only thing that can help you and inform you on making the right decisions for you. These experiences are what inclusion looks like.
This is not charity, this is true inclusion.
Macro:
The crux of this post is this: Science and technology related fields are becoming the primary industries for global commerce and market participation (read: dominant basis of wealth generation) and secondly that as of the writing of this post today, in the present time we happen to live, I personally believe that Ben Horowitz is the single most important person acting in the interest for the entry and participation of people of color into science and technology related professions. This isn’t to say that there aren’t others doing great things that are helping, but that Ben is the most impactful person of the lot currently.
Secondly, and much more importantly, diversity isn’t just being on the payroll and isn’t just a head count, diversity means a whole host of things more than that, notwithstanding, acceptance and adoption of culture first and foremost (culture: the music, art, and philosophy of a people)
Let’s deconstruct the common misuse of the word “diversity” as thrown around. In Silicon Valley the word means “non whites”. This is an obscuring of both data and definition. Oh great lets just count the numbers of non whites in technology companies or being funded to run them, and pat ourselves on the back, yay for people! This is an old, quick and short way of quieting any voices that clamor for honesty regarding inclusion and that rail against the charge of ”pattern matching” (it happens). The fact is that we don’t have enough black and latino founders, investors, scientists, and executives participating in the commercialization and management of technology.
The isn’t only about different faces, it is about cultural adoption, because let’s face it, birds of a feather flock together. It is far more likely that if I am into the same things you are into and wear the same clothes that you wear, and come from the same college dorm that you were in, then we likely share the same humor and taste movies and hobbies. I’m far more likely to be able to connect with you quickly, and build rapport. In the valley this translates into getting funded more easily, getting my company written about more easily, and most importantly to be able to attract the best talent as employee/co-founders. This has little to do with skin color and everything to do with skin color at the same time. Why is that? Because people consume culture in groups, that is why. From that foundation is where pattern matching (we all do it) is built. If you look around silicon valley, there are not as many black or latino’s participating in tech in the valley. This is not controversial, but what is controversial is what is really helping and what isn’t. This can’t be remedied until there is cultural exchange of some sort.
Summary:
Finally and in summary, I want to explain the two things Ben is doing that are much more impactful than all of the fancy HR diversity policies, the proclamations being progressive, or participation in hipster infested SF style protests on your weekend. We don’t need more “please help a brother who is down and out” style charity. What we need is what Ben is doing. Those things are:
1. A new network.
Ben is using his power and time (and trust me he is the *only* one doing this) to build and advocating and acting on the design and construction of an authentic network that facilitates participation and adoption of the culture. I cannot stress anymore the importance of inclusion in the networks that run silicon valley. Networks equal access to jobs, funds, and deal flow, and the networks that run silicon valley are Stanford, Harvard, MIT, Google, HP, Ebay, Facebook, Apple, and PayPal. To purposefully create an intersection with these networks and a network of people of color is actual helping the situation, It is not the misguided charity so many love. It is real cultural translation and adoption. IE - opening the doors to silicon valley in earnest.
2. Cultural implanting.
The ability to implant beta culture in alpha culture and exalt beta culture as not only important but necessary. By purposefully using his influence to explain how culture described and translated in the things like music (hip hop primarily), sports and sports history, digital media, and then repurposing this culture to be seen as valuable to alpha culture in how they can and do inform good business decisions and how they create and move markets in general has taken things that were considered silly and suboptimal and even degenerative and redefined them as important culturally to the alpha culture that is running the business world, especially technology business, that as I said earlier, is where tomorrow’s dominant wealth creation is happening.
Ben's work and the work of those with him is creating authentic diversity and participation in science and technology related fields. I am not talking about filling quotas I am talking about “change”.
For that we should be all jumping into the work.
Disclaimer, I am the co-founder of a company that a16z has invested in.
↧
↧
T-Mobile CEO: “This industry blows,” biggest carriers offer “horsesh**” | Ars Technica
Comments:"T-Mobile CEO: “This industry blows,” biggest carriers offer “horsesh**” | Ars Technica"
T-Mobile CEO John Legere in July 2013.
T-Mobile Ars at CES 2014
View all…
T-Mobile US CEO John Legere has had an eventful week at the Consumer Electronics Show in Las Vegas. He was thrown out of AT&T's CES party Monday night after the company detected his presence. Today, he got on stage to announce T-Mobile's latest initiative, and he unleashed a stream of curses and insults at competitors AT&T, Verizon, and Sprint.
Family plans are "total horseshit… nothing more than a contract on super steroids with staggered dates—a complete life sentence," Legere said. "Sprint is a pile of spectrum waiting to be turned into a capability. Right now, their network is completely horrible."
AT&T, meanwhile, is a "total source of amusement for me," he said, blasting the company's plan to charge content providers for the right to bypass data caps that hinder customers instead of just offering unlimited data like T-Mobile does.
Legere, wearing a T-Mobile T-shirt and holding a can of Red Bull, even said he plans to send a cease and desist letter to AT&T "to stop their advertising that say they're the fastest." Cellular companies often claim to be the fastest or biggest network—naturally, T-Mobile today said the latest numbers show it's the fastest.
"This industry blows. It's just broken. It needs change," Legere said.
His speech today wasn't all bluster, though. T-Mobile said it would pay off early termination fees (ETF) for customers who switch from AT&T, Sprint, or Verizon. "With an eligible phone trade-in, the total value of the offer to switch to T-Mobile could be as high as $650 per line," the company's announcement said. "ETFs can cost as much as $350 per line. Multiply that two, three, or four times for a family, and switching becomes an extremely expensive proposition."
T-Mobile argued that family plans lock people into their carriers for much longer than two years because "with staggered expiration dates and early termination fees, they’re really locking you in forever."
T-Mobile said its offer to pay off early termination fees is good even for families. Details are as follows:
Starting tomorrow, customers from the three major national carriers who hand in their eligible devices at any participating T-Mobile location and switch to a postpaid Simple Choice Plan can receive an instant credit, based on the value of their phone, of up to $300. They then purchase any eligible device, including T-Mobile’s most popular smartphones, now priced at $0 down (plus 24 monthly device payments for well-qualified customers). After customers get the final bill from their old carrier (showing their early termination fees), they either mail it to T-Mobile or upload it to www.switch2tmobile.com. T-Mobile then sends an additional payment equal to those fees, up to $350 per line. Trade-in of their old phone, purchase of a new T-Mobile phone and porting of their phone number to T-Mobile are required to qualify.Family plans at T-Mobile "start with one line at $50 per month for unlimited talk, text, and Web with up to 500MB of 4G LTE data," the company said. "They can add a second phone line for $30 per month, and each additional line is just $10 per month."
While T-Mobile lets users pay for handsets on a 24-month installment plan, the company noted that it has eliminated annual service contracts, saying customers should be able to switch whenever they'd like.
AT&T last week announced that it would give T-Mobile customers up to $450 in incentives to switch, in a move widely seen as an attempt to preempt T-Mobile's announcement.
Legere said T-Mobile has turned the ship around in customer numbers. While T-Mobile lost 2.1 million customers overall in 2012, in 2013 it added 4.4 million net new customers, Legere said. That includes 1.645 million new customers in the fourth quarter, about half postpaid and half prepaid.
T-Mobile is also hoping to ride high on its pending acquisition of more than $3 billion worth of 700MHz A-Block spectrum licenses from Verizon Wireless. Verizon had to sell off spectrum in order to gain approval for a separate spectrum purchase. T-Mobile CTO Neville Ray said in his 14 years at the company, "I have never had a weapon like this in my arsenal. We are going to frighten the crap out of AT&T and Verizon with that spectrum."
Sprint and Dish are reportedly considering bids to purchase T-Mobile. Without naming them, Legere said the rumored buyers are just "spectrum with no legs." He said he believes US government officials want T-Mobile to remain a real alternative to the biggest carriers. Even if T-Mobile is acquired, the brand and its attitude should live on, he said.
"What we're doing, in any scenario, will prevail," he said.
↧
Legal Data « Web Policy
Comments:" Legal Data « Web Policy"
URL:http://webpolicy.org/category/empirical-law/legal-data/
Modern quantitative analysis has upended the social sciences and, in recent years, made exciting inroads with law. How complex are the nation’s statutes?1 Did a shift in Supreme Court voting dodge President Roosevelt’s court-packing plan?2 How do courts apply fair use doctrine in copyright cases?3 What factors determine the outcome of intellectual property litigation?4 Researchers have begun to answer these and many more questions through the use of empirical methodologies.
Academics have vaulted numerous hurdles to advance this far, including deep institutional siloing and specialization. But barriers do still exist, and one of the greatest remaining is, quite simply, data. There is no easy-to-get, easy-to-process compilation of America’s primary legal materials. In the status quo, researchers are compelled to spend far too much of their time foraging for datasets instead of conducting valuable analysis. Consequences include diminished scholarly productivity, scant uniformity among published works, and—most frustratingly—deterrence for prospective researchers.
My hope is to facilitate empirical legal scholarship by providing machine-readable primary legal materials. In this first release of data, I have prepared XML versions of the U.S. Code and opinions of the Supreme Court of the United States, through approximately early 2012. Subsequent releases may include additional primary legal materials. I would greatly appreciate feedback from the academic community, particularly with regards to the XML schema, text formatting, and prioritizing materials for release.
United States Code: ZIP (110 MB)
Supreme Court of the United States Opinions: ZIP (348 MB)
Please note, this is a personal project. It is not related to my coursework or research at Stanford University.
1. Michael J. Bommarito II & Daniel M. Katz, A Mathematical Approach to the Study of the United States Code, 389 Physica A 4195 (2010), available athttp://www.sciencedirect.com/science/article/pii/S0378437110004875.
2. Daniel E. Ho & Kevin M. Quinn, Did a Switch in Time Save Nine?, 2 J. Legal Analysis 69 (2010), available athttp://jla.oxfordjournals.org/content/2/1/69.full.pdf.
3. Matthew Sag, Predicting Fair Use, 73 Ohio St. L.J. 47 (2012), available athttp://moritzlaw.osu.edu/students/groups/oslj/files/2012/05/73.1.Sag_.pdf.
4. Mihai Surdeanu et al., Risk Analysis for Intellectual Property Litigation, Proc. 13th Int’l Conf. on Artificial Intelligence & L. 116 (2011), available athttp://dl.acm.org/citation.cfm?id=2018375.
↧
Datomic: Datomic 2013 Recap
↧
↧
At least eight security experts boycott prominent security conference over NSA ties
Comments:"At least eight security experts boycott prominent security conference over NSA ties"

The National Security Agency campus in Fort Meade, Md., in June 2013. (Patrick Semansky/AP)
At least six eight computer security researchers have withdrawn from a major security conference in a protest against the conference's sponsor, computer security firm RSA. That company has been accused of taking money from the National Security Agency to incorporate a flawed encryption algorithm into one of its security products.
Reuters reported last month on a secret $10 million contract between RSA and the NSA. Allegedly, RSA, an encryption pioneer that is now a division of EMC, took a $10 million payment for making a specific NSA-developed algorithm the default method for generating random numbers in one of their security products.
Documents leaked by former NSA contractor Edward Snowden suggest that the NSA included a flaw in the formula that effectively gave the NSA a "backdoor" for content encrypted using the algorithm, known as Dual Elliptic Curve. The National Institutes of Standards and Technology (NIST) later approved the standard, but RSA started using it even before NIST's blessing. But researchers had long speculated about the security of the protocol. After the Snowden revelation, RSA warned customers to stop using it.
In a statement posted days after the Reuters report about the NSA contract, RSA stated that it had never hidden the fact that it had a relationship with the NSA. The company also asserted that it had not intended to weaken the cryptographic capabilities of its software products. But it didn't directly deny Reuters's central charge: that it had accepted $10 million to use the NSA's algorithm.
The revelations, and the evasive response from RSA, triggered outrage among some security professionals. Within days of the story, the first rumblings of a boycott of the RSA Conference scheduled for February started to appear. The RSA Conference is a major cybersecurity industry event that attracted over 24,000 attendees in 2013. Hugh Thompson, the program committee chairman, calls speaking slots at the conference "highly competitive," with more than 2,000 submissions battling for 300 to 400 sessions.
Yet, Josh Thomas of Atredis Partners announced Dec. 22 that he was pulling his talk due to a "moral imperative." Then Mikko Hypponen, chief research officer at Finnish cybersecurity company F-Secure, announced that he would be cancelling his talk (appropriately titled "Governments as Malware Authors") via an open letter Dec. 23.
Chris Palmer, a software security engineer at Google, also joined in the chorus of cancelled talks in December, according to a tweet from his personal account. In the New Year, the boycott continued to pick up recruits, including Jeffrey Carr, founder and CEO of cyberesecurity company Taia Global, who announced that he would cancel his talk at the conference.
On Tuesday, Christopher Soghoian, principal technologist with the ACLU's Speech, Privacy and Technology Project, tweeted that he had withdrawn from his panel. So, too, did another Googler, Adam Langley.
I've given up waiting for RSA to fess up to the truth re: the NSA and Dual_EC. I've just withdrawn from my panel at the RSA conference. — Christopher Soghoian (@csoghoian) January 7, 2014Thompson said he was "disappointed" by their cancellations, but argued that their ire was misplaced because the conference has "long been a neutral event." However, he did concede that "RSA, the company, owns RSA Conference." Thompson expects to fill the now-vacant slots with alternate speakers from the selection process and believes that the conference is all the more important because of the NSA revelations of the previous year.
"Security has risen in the agenda of almost every company and every government in a way that we've never seen before," he said."I think that the security dialogue is more intense than it has ever been."
Update: The original version of this story reported that six experts were boycotting, but during the writing and editing process two further experts announced they had withdrawn from the conference -- Marcia Hofmann and Alex Fowler.
↧
BBC News - CES 2014: BMW shows off 'drifting' self-drive cars
Comments:"BBC News - CES 2014: BMW shows off 'drifting' self-drive cars"
URL:http://www.bbc.co.uk/news/technology-25653253
8 January 2014Last updated at 07:56 ET
Please turn on JavaScript. Media requires JavaScript to play.
BMW's promotional video of its latest autonomous driving technology
BMW has shown off self-driving cars that can "drift" around bends and slalom between cones.
The modified 2-Series Coupe and 6-Series Gran Coupe are able to hurtle round a racetrack and control a power slide without any driver intervention.
Using 360-degree radar, ultrasonic sensors and cameras, the cars sense and adapt to their surroundings.
BMW demonstrated its latest autonomous driving technology at the Consumer Electronics Show (CES) in Las Vegas.
It is just one of several car manufacturers experimenting with the technology - Japan's Toyota has also been demonstrating its autonomous car at CES.
And Bosch, better known for its white goods and power tools, showed off its smartphone-controlled self-parking technology at the show.
Accident-proneWith about 50,000 road fatalities in the US each year, carmakers are hoping sensor- and software-controlled cars could prove less accident-prone than cars driven by humans.
One 2013 study by the Eno Center for Transportation suggested that if 10% of cars on US roads were autonomous this could reduce fatalities by about 1,000.
A number of driver assistance technologies are already being incorporated into the latest cars, from lane-drifting warnings to self-parking.
Currently California, Florida and Nevada have licensed autonomous vehicles to be tested on their public roads, and Google's fleet of 24 robot Lexus SUVs (sports utility vehicles) have clocked up about 500,000 miles of unassisted driving so far without any reported mishaps.
Autonomous vehicles are not yet allowed on European roads and we are still a long way from seeing driverless cars frequenting our streets and motorways.
But as the number of successful demonstrations grows, the cultural hurdles are probably greater than the technological ones.
↧
Google Online Security Blog: FFmpeg and a thousand fixes
Comments:"Google Online Security Blog: FFmpeg and a thousand fixes"
URL:http://googleonlinesecurity.blogspot.com/2014/01/ffmpeg-and-thousand-fixes.html
Posted by Mateusz Jurczyk and Gynvael Coldwind, Information Security Engineers
At Google, security is a top priority - not only for our own products, but across the entire Internet. That’s why members of the Google Security Team and other Googlers frequently perform audits of software and report the resulting findings to the respective vendors or maintainers, as shown in the official “Vulnerabilities - Application Security” list. We also try to employ the extensive computing power of our data centers in order to solve some of the security challenges by performing large-scale automated testing, commonly known as fuzzing.
One internal fuzzing effort we have been running continuously for the past two years is the testing process of FFmpeg, a large cross-platform solution to record, convert and stream audio and video written in C. It is used in multiple applications and software libraries such as Google Chrome, MPlayer, VLC or xine. We started relatively small by making use of trivial mutation algorithms, some 500 cores and input media samples gathered from readily available sources such as the samples.mplayerhq.hu sample base and FFmpeg FATE regression testing suite. Later on, we grew to more complex and effective mutation methods, 2000 cores and an input corpus supported by sample files improving the overall code coverage.
Following more than two years of work, we are happy to announce that the FFmpeg project has incorporated more than a thousand fixes to bugs (including some security issues) that we have discovered in the project so far:
$ git log | grep Jurczyk | grep -c Coldwind
1120
This event clearly marks an important milestone in our ongoing fuzzing effort.
FFmpeg robustness and security has clearly improved over time. When we started the fuzzing process and had initial results, we contacted the project maintainer - Michael Niedermayer - who submitted the first fix on the 24th of January, 2012 (see commit c77be3a35a0160d6af88056b0899f120f2eef38e). Since then, we have carried out several dozen fuzzing iterations (each typically resulting in less crashes than the previous ones) over the last two years, identifying bugs of a number of different classes:
- NULL pointer dereferences,
- Invalid pointer arithmetic leading to SIGSEGV due to unmapped memory access,
- Out-of-bounds reads and writes to stack, heap and static-based arrays,
- Invalid free() calls,
- Double free() calls over the same pointer,
- Division errors,
- Assertion failures,
- Use of uninitialized memory.
We are continuously improving our corpus and fuzzing methods and will continue to work with both FFmpeg and Libav to ensure the highest quality of the software as used by millions of users behind multiple media players. Until we can declare both projects "fuzz clean" we recommend that people refrain from using either of the two projects to process untrusted media files. You can also use privilege separation on your PC or production environment when absolutely required.
Of course, we would not be able to do this without the hard work of all the developers involved in the fixing process. If you are interested in the effort, please keep an eye on the master branches for commits marked as "Found by Mateusz "j00ru" Jurczyk and Gynvael Coldwind" and watch out for new stable versions of the software packages.
For more details, see the “FFmpeg and a thousand fixes” posts at the authors’ personal blogs here or here.
↧
Comparing Filesystem Performance in Virtual Machines
Comments:"Comparing Filesystem Performance in Virtual Machines"
URL:http://mitchellh.com/comparing-filesystem-performance-in-virtual-machines
For years, the primary bottleneck for virtual machine based development environments with Vagrant has been filesystem performance. CPU differences are minimal and barely noticeable, and RAM only becomes an issue when many virtual machines are active[1]. I spent the better part of yesterday benchmarking and analyzing common filesystem mechanisms, and now share those results here with you.
I’ll begin with an analysis of the results, because that is what is most interesting to most people. The exact method of testing, the software used, and the raw data from my results can be found below this analysis.
In every chart shown below, we test reading or writing a file in some way. The total size of the file being written is fixed for each graph. The Y axis is the throughput in KB/s. The X axis is “record size” or the size of the chunks of data that are being read/written at one time, in KB.
The different test environments are native, VirtualBox native, VMware native, VirtualBox shared folders (vboxsf), VMware shared folders (vmhgfs), and NFS. The “native” environments refer to using the filesystem on its own in that environment. “native” is on the host machine, “VirtualBox native” is on the root device within the VirtualBox virtual machine, etc. NFS was only tested on VirtualBox because the performance characteristics should be similar in both VirtualBox and VMware.
For every chart, higher throughput (Y axis) is better.
Small File Sequential Read
First up is a sequential read of a 64 KB file, tested over various read record sizes. A real world application of a small sequential read would be loading the source files of an application to run, compile, or test.
The first thing you can’t help but notice is that the read performance of NFS is incredible for small record sizes. NFS is likely doing some heavy read-ahead operations and caching to get this kind of performance. I don’t have a good theory on how NFS outperforms the native virtual filesystems.
VMware shared folders just crush VirtualBox shared folders here. VirtualBox shared folder read performance is just abysmal. If you look at the raw data, you’ll see the throughput actually never goes above 100 MB/s, while VMware never goes below 500 MB/s, and peaks at over 900 MB/s.
It is interesting that sometimes the native filesystem within the virtual machine outperforms the native filesystem on the host machine. This test uses raw read system calls with zero user-space buffering. It is very likely that the hypervisors do buffering for reads from their virtual machines, so they’re seeing better performance from not context switching to the native kernel as much. This theory is further supported by looking at the raw result data for fread benchmarks. In those tests, the native filesystem beats the virtual filesystems every time.
Large File Random Read
This tested the throughput of randomly reading various parts of a 64 MB file, again tested with various read record sizes. This file is 1000x larger than in our previous test. This sort of behavior might be seen when dealing with database reads that hit the filesystem.
The gap between VMware and VirtualBox is widened considerably compared to small sequential reads. VirtualBox performs so badly you can barely see it. Again, VirtualBox throughput never peaks above 100 MB/s. VMware, on the other hand, is peaking at 7 GB/s. Because the deviation of the VirtualBox throughput is so small across various test cases, I theorize that there is a single hot path of code in the VirtualBox shared folder system limiting this. They’re clearly doing something wrong.
NFS is less dominating, most likely because the read-ahead benefits are not seen in this test case. Still, NFS performs very well versus other options.
And, just as with the small sequential read, we’re still seeing better performance within the virtual machine versus outside. Again, this can be attributed to the hypervisor doing clever buffering, whereas the raw syscalls to the host machine don’t allow this to happen.
Small File Sequential Write
Let’s look at the performance of sequential writes of small files. This most accurately describes storing session state, temporary files, or writing new source files.
The first noticeable thing is that NFS performance is terrible for these kinds of writes. There is no real caching that NFS can do here, so you must pay the full penalty for network overhead, then writing to disk on the host side, and finally waiting for an ack again the VM that the write succeeded. Ouch.
The various “native” filesystems perform very well. Again, the virtual machines outperform the host. And again, this can be attributed to buffering in the hypervisors.
The shared filesystems are close, but VirtualBox clearly outperforms VMware in this test case.
Large File Random Write
The final chart we’ll look at are the results of testing random writes to a large (64 MB) file. Just like our large random read test, this is a good test for how a database would perform.
There really isn’t much of a difference here versus small sequential writes. Because it is a large file, the gaps between the different test environments is larger, but other than that, the results are mostly the same.
NFS continues to be terrible at writes. VirtualBox continues to outperform VMware on writes, and the hypervisors outperform the host machine.
Hypervisors outperforming the host machine is the most interesting to me. The results of this test clearly show that the hypervisors must be lying about synced writes for performance. This corroborates what I’ve seen with Packer as well, where if the virtual machine is not cleanly shut down, committed writes are lost. fsync() in a virtual machine does not mean that the data was written on the host, only that is is committed within the hypervisor.
Overall Analysis
With regards to shared filesystems, VMware has the behavior you want. Loading web pages, running test suites, and compiling software are all very read heavy. VMware read performance demolishes VirtualBox, while the write performance of VirtualBox is only marginally better than VMware.
If you have the option to use NFS, use it. Again, the read performance is far more valuable than the write performance.
Hypervisor read/write performance is fantastic (because they cheat). Thanks to this data, I’m definitely going to be focusing more on new synced folder implementations in Vagrant that use only the native filesystems (such as rsync, or using the host machine as an NFS client instead of a server).
More immediately applicable, however: if you use virtual machines for development, move database files out of the shared filesystems, if possible. You’ll likely see huge performance benefits.
Finally, I don’t think there are any huge surprises in these results. Vagrant has supported NFS synced folders since 2010 because we realized early on that performance in the shared folders was bad. But having some hard data to show different behaviors is nice to have, and provides some interesting insight into what each system might be doing.
The host machine is a 2012 Retina MacBook Pro with a 256 GB SSD running Mac OS X 10.9.1. Tests here were labelled native.
VirtualBox is version 4.3.4 running a virtual machine with Ubuntu 12.04 with the VirtualBox guest additions installed and enabled. The root device under test in VirtualBox is formatted with an ext3 filesystem. Tests on the root device were labelled VirtualBox native while tests on the shared folder system (vboxsf) were labelled VirtualBox shared folders (vboxsf).
VMware Fusion is version 6.0.2 running a virtual machine with Ubuntu 12.04 with VMware Tools 5.0 installed and enabled. The root device under test in VMware is formatted with an ext3 filesystem. Tests on the root device were labelled VMware native while tests on the shared folder system (vmhgfs) were labelled VMware shared folders (vmhgfs).
The NFS server used is the one built and shipped with OS X 10.9.1. The NFS client is what comes with the nfs-common package in Ubuntu 12.04. NFS protocol 3 was used over UDP. Tests using NFS were labelled NFS in VirtualBox.
The benchmarking software used was the Iozone Filesystem Benchmark compiled from source for 64-bit Linux. The same binary was used in every instance except for the native test, which used a 32-bit OS X binary of Iozone compiled from source. The flags passed to Iozone were -Racb.
Unless otherwise noted, the remaining settings not mentioned here were defaults or not touched.
The raw data for the tests can be found in this Excel workbook. There are also more graphs for this data in this imgur album.
Footnotes:
[1]: This is in the case of a standard web development environment. They are typically neither CPU bound nor RAM-intensive.
185 Kudos 185 Kudos↧
↧
FOBO Launches In San Francisco To Become The Fastest, Easiest Way To Sell Your Consumer Electronics | TechCrunch
URL:http://techcrunch.com/2014/01/10/fobo/

By now you probably know that Craigslist sucks as a way to sell stuff. You have to contend with spam emails, buyers who promise to purchase your goods but flake, and people who show up then try to haggle down the price after the fact. But somehow, no one has figured out a way to make it better or provide a real alternative.
Well, there’s a new app out called FOBO that aims to solve all those problems, providing users with a local marketplace for selling consumer electronics.
FOBO launches in San Francisco today, offering its users a new way to sell goods via mobile app. It gets rid of all the hassle that is usually associated with local marketplaces and makes it ultra-simple and ultra-fast to do so. The app guarantees sellers will get a certain price for their devices and will be paid upfront, and ensures that their product is sold fast — within 97 minutes.
When you list an item on FOBO, the app instantly prices your item, usually based on the average sales price on eBay. It then starts up an auction that lasts a little more than an hour and a half, during which time other FOBO users can bid on your goods.
But if by some bit of bad luck your item doesn’t sell to another user, FOBO will buy it for the guaranteed starting price and do the hard work of reselling it. So there’s really only upside to listing your item.
FOBO doesn’t want to be a Gazelle-like reseller — it’s mainly just guaranteeing sales prices to seed the marketplace with good stuff. Getting the supply side of a marketplace rolling is the hard part, after all. And it seems to be working: FOBO sold 92 percent of items listed in its 1,000-person beta run over the past few months.
There are other advantages to listing with FOBO, other than just getting a guaranteed amount for a consumer electronics device in 97 minutes. Buyers pay for the good in-app, which means there’s no haggling once they show up to pick up the device. And they agree to meet at a time that works on the seller’s schedule.
On the buyer side, FOBO also makes things easy. When you first sign up, you’re prompted to subscribe to certain types of electronics. And then you get notifications when they go on sale.
The team had raised $1.6 million in funding from Index Ventures, Greylock, Kevin Rose, Chris Sacca, Y Combinator, and a few others.
↧
Foursquare constantly tracking users' locations | Thiago Valverde
Comments:"Foursquare constantly tracking users' locations | Thiago Valverde"
URL:http://blog.valverde.me/2014/01/07/foursquare-constantly-tracking-users-locations/
(and how to audit your phone's application traffic yourself) ![]()
![]()
![]()
![]()
![]()
![]()
It might sound weird to accuse Foursquare of collecting location data since that is the whole point of the service, but Foursquare is overstepping its bounds by constantly keeping track of their users' every move (and more) — even if they never open the app.
The Foursquare app contacts the service every ten minutes, providing a list of minute-by-minute locations (including timestamp and accuracy data), battery level, charging status, internet connectivity status and nearby wireless access points (complete with timestamp, MAC address and signal strength).
This is hardly news, though. Foursquare has proudlyannounced this new feature as the unnamed successor to Foursquare Radar. One important change is that the feature became opt-out (as opposed to Foursquare Radar, which was opt-in). The collected data enables them to provide users with push notifications of “tips, friends and interesting things etc. near you”, as outlined in their privacy policy:
Also, Foursquare uses your mobile device’s ‘background location’ (formerly known as ‘Radar’) to provide the service, including to send you notifications of tips/friends/ interesting things etc. near you. If you have ‘background location’ turned on, the Foursquare app will, from time to time, tell us about your device’s location even if you are not directly interacting with the application. FoursquarePrivacy PolicyThey even addressed the concern that this might impact battery life on their users' phone using the data they collected, as reported by TechCrunch:
The new and improved push recommendation feature purportedly only increases battery drain by about 0.7 percent per hour — or, “the equivalent of about a 20-minute game of Angry Birds” over the course of a day. TechCrunchNo Check In RequiredHowever, the amount of data collected in this manner is, at the very least, unnecessary. Here's a sample update, lightly modified for legibility and privacy. All coordinates, access point names and MAC addresses were replaced with fictional values. I also transformed the request from x-www-form-urlencoded to json and split a couple of semicolon-separated strings into arrays, for legibility.
Besides giving us some insights on how their tracking works (triggers object in the response) and how it detects whether the user is on the move (stopDetect), this updates shows just how much data is being shared with Foursquare behind the scenes.
Most of the data is self-explaining, but here's what I could gather by watching a few of these updates:
batteryStatus— one ofunplugged,chargingorfullbatteryStrength— amount of battery charge left (between 0 and 1)coarseLL,coarseLLAcc,coarseLLTimestamp— current (coarse?) location, accuracy and timestamphistory— set of semicolon-delimited location data points, consisting of timestamp, accuracy and coordinatesll,llAcc— matchedcoarseLL,coarseLLAccin all requests I logged. Probably contains finer (GPS) data when availablewifiScan— set of semicolon-delimited spotted access point data, consisting of timestamp, SSID (network name), BSSID (MAC address) and signal strength
One might wonder if there‘s a better, less invasive way to deliver the same kind of notifications. Here’s a suggestion: have the app download all of the nearby location-specific notifications, then decide locally when to show them. Less creepy and more battery efficient. Win-win.
For now, there is a way to disable this behavior, buried three menus deep under Settings > Account Settings > Privacy:

Of course, Foursquare is probably not the only app doing this, which is why you might be motivated to audit your own phone's traffic.
Observing HTTP traffic from a smartphone is simple enough — fire up your proxy of choice, set it up as a transparent proxy or on the device and watch the logs. That's all there is to it. On the other hand, most interesting traffic occurs over HTTPS for many reasons, including privacy and security. The Foursquare requests described in this article, for example, occur over HTTPS and are not easily intercepted with a common proxy server or packet sniffer.
This section aims to illustrate how to capture HTTP and (most) HTTPS traffic originated by your device, which can be quite useful while auditing third party applications or debugging your own.
Note that not all traffic can be intercepted this way. Fiddler only supports only HTTP, HTTPS and SPDY, which means an application could communicate without showing up in Fiddler by using a different protocol (e.g. a raw or TLS socket). Some applications using certificate pinning might refuse to communicate with this interception in place (e.g. Dropbox and GMail).
The toolset
Fiddler— an excellent HTTP debugger by Eric Lawrence / Telerik.
Certificate Maker— a Fiddler add-on that generates interception certificates compatible with iOS and Android devices. This is only required if you care about HTTPS traffic.
These tools are Windows-only, but there are alternatives for other platforms such as Burp Suite, Charles Proxy and mitmproxy (thanks chubot).
Setting up Fiddler
After installing Fiddler and Certificate Maker, you should be greeted by Fiddler's main window:
HTTPS decryption is off by default in Fiddler. Here are the appropriate settings for this guide (under Tools > Fiddler Options):
You might need to restart Fiddler after changing these settings. After restarting, click the Capturing icon on the status bar in order to ignore local traffic.
Setting up your device
This guide shows the steps for Android 4.4, but most devices have similar procedures (including iOS devices).
First, open a browser and navigate to your Fiddler instance. The default port for Fiddler is 8888.

Click the FiddlerRoot certificate link, name your certificate and save the changes. This allows Fiddler to behave as a certification authority, generating certificates for intercepted websites on the fly.

Android 4.4 now (rightfully) warns the user when a custom root certificate is installed with a persistent notification. Kudos to Google for that. Since we are the bad guys Google is warning us about, there is no need to be concerned.

Finally, change your proxy settings to have your traffic go through Fiddler.

Capturing traffic
That's it! You should now be able to see requests originated by your phone on Fiddler. Here's an example session:
Try Snapchat if you want to learn how their API works, or any “free flashlight” app if you're feeling brave. Remember to remove all custom settings after exploring.
↧
The Day We Fight Back - February 11th 2014
Comments:"The Day We Fight Back - February 11th 2014"
URL:https://thedaywefightback.org
DEAR USERS OF THE INTERNET,

In January 2012 we defeated the SOPA and PIPA censorship legislation with the largest Internet protest in history. A year ago this month one of that movement's leaders, Aaron Swartz, tragically passed away.
Today we face a different threat, one that undermines the Internet, and the notion that any of us live in a genuinely free society: mass surveillance.
If Aaron were alive, he'd be on the front lines, fighting against a world in which governments observe, collect, and analyze our every digital action.
Now, on the eve of the anniversary of Aaron's passing, and in celebration of the win against SOPA and PIPA that he helped make possible, we are announcing a day of protest against mass surveillance, to take place this February 11th.
↧
Cloact: Minimalistic React for ClojureScript
Comments:"Cloact: Minimalistic React for ClojureScript"
URL:http://holmsand.github.io/cloact/
Introduction to Cloact
Cloact provides a minimalistic interface between ClojureScript and React. It allows you to define efficient React components using nothing but plain ClojureScript functions and data, that describe your UI using a Hiccup-like syntax.
The goal of Cloact is to make it possible to define arbitrarily complex UIs using just a couple of basic concepts, and to be fast enough by default that you rarely have to care about performance.
A very basic Cloact component may look something like this:
Source
(defnsimple-component[][:div[:p"I am a component!"][:p.someclass"I have "[:strong"bold"][:span{:style{:color"red"}}" and red "]"text."]])
You can build new components using other components as building blocks. Like this:
Source
(defnsimple-parent[][:div[:p"I include simple-component."][simple-component]])
Data is passed to child components using plain old Clojure
maps. For example, here is a component that shows items in a seq:
hide
Example
Source
(defnlister[props][:ul(for[item(:itemsprops)][:li{:keyitem}"Item "item])])(defnlister-user[][:div"Here is a list:"[lister{:items(range3)}]])
Note: The {:key item} part of the :li
isn’t really necessary in this simple example, but passing a
unique key for every item in a dynamically generated list of
components is good practice, and helps React to improve
performance for large lists.
Managing state in Cloact
The easiest way to manage state in Cloact is to use Cloact’s
own version of atom. It works exactly like the one in
clojure.core, except that it keeps track of every time it is
deref’ed. Any component that uses an atom is automagically
re-rendered when its value changes.
Let’s demonstrate that with a simple example:
Sometimes you may want to maintain state locally in a
component. That is easy to do with an atom as well.
Here is an example of that, where we call setTimeout every time the component is rendered to
update a counter:
hide
Example
Source
(defntimer-component[](let[seconds-elapsed(atom0)](fn[](js/setTimeout#(swap!seconds-elapsedinc)1000)[:div"Seconds Elapsed: "@seconds-elapsed])))
The previous example also uses another feature of Cloact: a component function can return another function, that is used to do the actual rendering. This allows you to perform some setup of newly created components, without resorting to React’s lifecycle events.
By simply passing atoms around you can share state management between components, like this:
Note: Component functions (including the ones returned by other component functions) are called with three arguments:
props: a map passed from a parentchildren: a vector of the children passed to the componentthis: the actual React component
Essential API
Cloact supports most of React’s API, but there is really only
one entry-point that is necessary for most applications: cloact.core/render-component.
It takes too arguments: a component, and a DOM node. For example, splashing the very first example all over the page would look like this:
Source
(nsexample(:require[cloact.core:ascloact:refer[atom]]))(defnsimple-component[][:div[:p"I am a component!"][:p.someclass"I have "[:strong"bold"][:span{:style{:color"red"}}" and red "]"text."]])(defnrender-simple[](cloact/render-component[simple-component](.-bodyjs/document)))
Performance
React itself is very fast, and so is Cloact. In fact, Cloact will be even faster than plain React a lot of the time, thanks to optimizations made possible by ClojureScript.
Mounted components are only re-rendered when their parameters
have changed. The change could come from a deref’ed atom, the arguments passed to the component (i.e the”props” map and children) or component state.
All of these are checked for changes with a simple identical? which is basically only a pointer
comparison, so the overhead is very low (even if the components of
the props map are compared separately, and :style attributes are handled specially). Even the
built-in React components are handled the same way.
All this means that you (hopefully) simply won’t have to care about performance most of the time. Just define your UI however you like – it will be fast enough.
There are a couple of situations that you might have to care
about, though. If you give Cloact big seqs of
components to render, you might have to supply all of them with a
unique :key attribute to speed up rendering. Also note
that anonymous functions are not, in general, equal to each other
even if they represent the same code and closure.
But again, in general you should just trust that React and Cloact will be fast enough. This very page is composed of a single Cloact component with thousands of child components (every single parenthesis etc in the code examples is a separate component), and yet the page can be updated many times every second without taxing the browser the slightest.
Incidentally, this page also uses another React trick: the
entire page is pre-rendered using Node, and cloact/render-component-to-string. When it is loaded
into the browser, React automatically attaches event-handlers to
the already present DOM tree.
Complete demo
Cloact comes with a couple of complete examples, with Leiningen project files and everything. Here’s one of them in action:
↧
↧
Money and wealth - swombat.com on startups
Comments:"Money and wealth - swombat.com on startups"
URL:http://swombat.com/2014/1/10/money-and-wealth
First, a disclaimer: I am not an economist. However, most people misunderstand money and its purposes and uses so badly that I feel compelled to write out my understanding of it. Perhaps because I am not an economist, this might help some.
My context: I am running a successful, profitable company that I started with my wife. I spent a number of years broke, but I have never been poor. I've always had the safety net of a middle class family and a top education (provided and paid for by my parents) to fall back on. I've lived in not-so-great accommodations, but it always seemed temporary in my life. Now for the first time I have enough money that I don't need to worry about it. I can afford the things I want (though I typically don't buy them, because once I can afford them, they no longer seem so desirable, just wasteful). Perhaps this is temporary, but at this point in my life I have enough money.
Thirdly, I am in this article discussing material wealth. There are many other potential variations for the meaning of wealth in other contexts. I'm not talking about these. Just the good old fashioned material wealth that society keeps telling us to chase.
With all that in mind, let us begin…
Money is a medium of exchange
The first and perhaps most important mistake people make is to confuse money for wealth. This is not too surprising when the dictionary itself proposes this misleading definition of "wealth":
1 . a great quantity or store of money, valuable possessions, property, or other riches: the wealth of a city.It's worth including the "Economic" definition on that page though, it does change things somewhat:
3 . Economics: a. all things that have a monetary or exchange value. b. anything that has utility and is capable of being appropriated or exchanged.You'll notice the Economists don't define wealth directly as money, but as the ownership of things that are worth exchanging for other things of value or for money.
The more I earn, the more I realise that wealth is not money, but the ability to generate money (and other things of value). This is akin to the difference between saying "I am a dancer" (i.e. I have the ability to dance) and "I was a dancer" (i.e. I once had it but I no longer have it). Being wealthy is equivalent to the first statement, while having money is equivalent to the second.
Having money does not make you wealthy, but having the ability to make money, through net income generating assets such as businesses, investments, or even just your own skills, that makes you wealthy. This is perhaps why those with a solid education are never really poor, but merely broke: they have the potential to make money, even if they don't have money right now.
But surely, having a lot of money, say a billion dollars, is the same as being wealthy? In theory, perhaps. In practice, it seems people who know how to maintain wealth would never keep a large sum in cash around, but quickly turn it into net income generating assets, and those who do not (e.g. lottery winners) often quickly find that the seemingly infinite pile of cash has evaporated into nothing.
Having a lot of money is at best a very temporary form of wealth.
Wealth is measured in net income generating assets, in things that allow you to generate money: skills, stock investments (if they generate profits), profitable businesses you own, cash-flow positive lands and properties, etc.
Money is not a net income generating asset. Money is not wealth. Money is a medium of exchange. By reading about rich people, you'll notice they generally try to avoid having a load of cash lying around, because money is not a place to store wealth. It is and has always been, historically, a very, very poor store of wealth. Currency, since its invention, has been a fantastic tool to facilitate exchanges of things of wealth. That is what it is, nothing more, nothing less. Our economy could not function without money, but its value is not in the money. The relationship between value and money is like that between a community and a message board, or a bicycle and its tires. The first can exist without the other, but the second without the first is mostly useless.
Some people will perk up at this and say "aha, this is because of the evils of inflation, and a return to the gold standard or a switch to Bitcoin would solve that".
To which the only valid answer is: bullshit.
Those who think money used to be stable need to read the book Money: whence it came, where it went (if you can't find a copy, send me an email). It is very instructive to look at the history of money and realise just how unreliable it is as a store of wealth. Historically, every few decades, money used to lose all its value in some kind of disastrous bubble that affected currency itself. Any wealth that was stored in money simply evaporated into nothing at all. Even gold suffered enormous ups and downs - for example, the importation of large amounts of pillaged south-american gold into Portugal destroyed its economy through hyper-inflation; the difficulty of moving gold between central banks during the gold standard era caused massive deflation in some parts and massive inflation in others.
The deep irony is that all those people calling for an end to inflation (and usually a return to a gold-like standard) because of the evil erosion of money, have lived their entire lives in a period of unprecedented monetary stability. Money is so stable nowadays that it sort of looks like a store of wealth, enough so that people get incensed that the state would dare allow inflation to affect it. The reality is that the current system has resulted (in some parts of the world, by far not all) in fairly steady and predictable inflation for almost a century.
Given the perils of deflation, a small, steady, controlled inflation is really the ideal situation for a medium of exchange. Not only that, but a moderate rate of inflation is generally considered a very good property for a medium of exchange for wealth, since it encourages people not to treat money as wealth, and to instead look to store their wealth in things that actually have value (ideally investments that enable the economy to work better, putting the accumulated wealth to use as capital).
But enough about misguided gold-standard bitcoin purists. How does this affect you, dear reader?
To get wealthy, build net income generating assets, don't accumulate money
Robert Kiyosaki, author of Rich Dad, Poor Dad (worth reading along with itssequels), proposes that rich people get rich by building their net income generating assets column (i.e. things that generate positive cash flow each month, not "buy and pray" investments like most stocks or houses), and that middle class people fail to get rich because instead of buying or building net income generating assets, they buy loss-making assets (e.g. by buying a bigger house with larger mortgage payments, or a new car with monthly payments) that drag them down.
I won't try and summarise Robert's entire philosophy in a blog post, but a common misconception (and my misconception, earlier) about "getting rich" is that it involves accumulating money.
As I hope I've made the case, having piles of money may occasionally happen on the way to getting rich, but it's not the goal, nor a desirable thing.
To get rich, what you want is net income generating assets, including the skills to generate those net income generating assets. Learning how to turn business opportunities into functioning businesses is an invaluable net income generating asset: I believe you can exploit that net income generating asset in almost any economic context, even war. But, as a more generic category, the fundamental pillars of wealth seem to me to be health (including youth, energy, endurance), education (including work ethic, general knowledge, wisdom, self-knowledge), intelligence and relationships (connections to useful people, trust, reputation, power). If you have those (at least the first three), and you truly desire wealth, it is yours for the taking, in this world at least (so long as you don't let your own beliefs hold you back).
The key takeaway should be that instead on focusing on how to accumulate money, you should instead focus on how to turn money (or other things) into things that create more money. A wealthy person doesn't set a goal of saving up a million dollars, and if they find themselves with a million dollars in cash, they quickly set to work finding a better format to store that wealth into.
Instead, figure out how much income you want and create things that will generate that income for you.
Savings
In that context, saving large amounts of money seems very ill-advised. Of course, at age 33, my perspective on this is limited, and perhaps I'm getting it all wrong, but it seems to me that the idea that the best preparation for retirement is to save up a load of money is a horribly noxious lie that has likely led to the bitter disappointment of hundreds of millions if not billions of people.
In the distant past, people "saved up" for their retirement by creating net income generating assets - out of their loins. Grown children can create wealth to sustain you when you can no longer do so yourself. A similar approach seems sensible today: instead of saving piles of cash that can depreciate rapidly or even be lost when the stock market turns sour and the bank or government turns around and slashes your retirement fund, create net income generating assets that will generate the wealth you will need to live on.
Saving for your retirement instead of creating net income generating assets seems like piling up potatoes in your cellar instead of keeping the potato farm running. The potatoes will go bad over time, you'll almost certainly miscalculate the amount of potatoes required, and if you run out, you're really properly screwed, because you don't have a farm to grow new potatoes anymore.
Pensions changed this somewhat - they were equivalent of handing the potato farm over to the state in exchange for a steady supply of potatoes until your death. In theory, this was a great idea. Unfortunately, history is showing that the state is a stingy, cruel, unfair and generally grossly incompetent manager of potato farms. Any people my age who, today, trust that the government will provide for them in their old age through pension schemes, are, in my opinion, delusional. Perhaps something else might change this situation, but who knows when such revolutionary ideas will actually take hold. In the meantime, Caveat Emptor.
The best kind of net income generating asset would be one that can adapt to changing circumstances, that has the lasting power to survive through dramatic world events (which no one can guarantee the future to be free of). The net income generating assets need not be imperishable: they merely need to have a very good chance of surviving you. Strangely enough, from this perspective, well educated, healthy, intelligent and loving children are probably still the best retirement net income generating asset you can possibly create, as they have been for thousands of years.
The purpose of wealth
Some people reading the above may think to make wealth their fundamental goal in life. I believe that's very misguided. As Paras Chopra said recently, the real use of money (or rather, wealth) is to buy freedom.
As Bob Dylan put it:
A man is a success if he gets up in the morning and goes to bed at night and in between does what he wants to do.Wealth can help with that, depending on what you want to do. Lack of wealth can definitely hurt that goal. I took some acting courses, and one acting teacher once declared that a "successful actor" earned about £5,000 a year from acting. The rest of their living costs came from odd jobs like being a waiter or working in a supermarket. I politely kept silent, but my thought was, this is not a successful actor, it is a successful minimum-wage worker with an acting hobby.
Wealth, to me, serves as a platform to enable you to do what you want without so many distractions. Fooling oneself into pursuing wealth as a fundamental objective is as limiting as failing to consider wealth at all.
Importantly, in this context, wealth is highly relative to the person. You are wealthy not if you exceed some social threshold, like being a millionaire or a billionaire, but simply if you have enough wealth to meet all your needs. This points to an obvious way to increase your wealth: reduce your needs. Some take this to the extreme. Some take this to even further extremes. The fact is, if you believe you need a castle and a ferrari to be happy, your bar for wealth will be much higher than if you are happy wherever you are and don't particularly care for owning cars.
Unfortunately, if you work surrounded by people who make lots of money, chances are they spend lots of money too, and by spending so much time with them you will learn to need to spend a lot to be satisfied too. This is why high-paying jobs seem, in practice, to fairly rarely result in creation of actual wealth. Instead, we end up reading stories in the New York Times of couples who earn $500k a year and feel poor. Those stories are usually made fun of as disconnected from reality - but there is no contradiction between earning money and being poor. Money is not wealth. Poverty in your mind cannot be cured with pay raises.
A final summary about money
If you want to avoid falling into some of the most devious traps that wrong-thinking about money can lead you into, keep the following principles in mind:
- Money is a medium of exchange for wealth, it is not a store of wealth.
- Money is transient and unreliable, and expecting it to display permanence will only lead to disappointment.
- Wealth is not an accumulation of money, but the ability to generate it when you need it.
- The fundamental building blocks of wealth are health, education and intelligence. Money is a side-effect of combining these building blocks with a wilful effort to create wealth.
- Any aggregation of lots of money is a risk. Turn it into net income generating assets as soon as possible to reduce that risk.
- Any aggregation of assets also is a risk! It can have maintenance costs, if they're not net income generating assets. Sometimes those costs outweigh the value of the assets in which case the assets are a net negative. Be careful what assets you invest in.
If you read this far, you should follow my RSS feed here.
↧
Learn Code The Hard Way -- Books And Courses To Learn To Code
↧
Simple Git workflow is simple - Atlassian Blogs
Comments:"Simple Git workflow is simple - Atlassian Blogs"
URL:http://blogs.atlassian.com/2014/01/simple-git-workflow-simple/
Many teams have already migrated to git and many more are transitioning to it now. Apart from training single developers and appointing Champions to help with the adoption it is imperative to pick a nice and simple code collaboration practice that does not complicate things too much. With git one can definitely conjure very complicated workflows, I’ve seen them first hand.
A manual on workflows does not come pre-installed with git, but maybe it should seeing how many people have questions on the topic. The good news is that we’re working hard to write material that helps.
Recent webinars and guides on workflows
If you prefer reading and pretty pictures, one of the most popular sections of our git tutorial site is the workflows section:
But before you leave for those destinations please read on, because I have something really cool for you.
I want to detail a terse but complete description of a simple workflow for continuous delivery. The prerequisite is that you and your team are at least a little bit acquainted with git, and have good knowledge of the rebase command in the two forms (interactive and not).
A basic basic branching workflow for continuous delivery
The simple workflow I want to describe has two guiding principles:
- master is always production-like and deployable.
- rebase during feature development, explicit (non fast-forward) merge when done.
Pulling change-sets using rebase rewrites the history of the branch you’re working on and keeps your changes on top.
The rebase you want in this workflow is the one in the second picture.
Armed with these guiding principles let’s breakdown the seven steps:
1. Start by pulling down the latest changes from master
This is done easily with the common git commands:
123git checkout master git fetch origin git merge master
I like to be more explicit and use fetch/merge but the two commands are equivalent to: git pull origin master.
2. Branch off to isolate the feature or bug-fix work in a branch
Now create a branch for the feature or bug-fix:
1git checkout -b PRJ-123-awesome-feature
The branch name structure I show here is just the one we use, but you can pick any convention you feel comfortable with.
3. Now you can work on the feature
Work on the feature as long as needed. Make sure your commits are meaningful and do not cluster separate changes together.
4. To keep your feature branch fresh and up to date with the latest changes in master, use rebase
Every once in a while during the development update the feature branch with the latest changes in master. You can do this with:
12git fetch origin git rebase origin/master
In the (somewhat less common) case where other people are also working on the same shared remote feature branch, also rebase changes coming from it:
1git rebase origin/PRJ-123-awesome-feature
At this point solve any conflicts that come out of the rebase.
Resolving conflicts during the rebase allows you to have always clean merges at the end of the feature development. It also keeps your feature branch history clean and focused without spurious noise.
5. When ready for feedback push your branch remotely and create a pull request
When it’s time to share your work and solicit feedback you can push your branch remotely with:
123git push -u origin PRJ-123-awesome-feature (if the branch is already set as 'upstream' and your remote is called 'origin', 'git push' is enough)
Now you can create a pull request on your favorite git server (for example Stash or Bitbucket).
After the initial push you can keep pushing updates to the remote branch multiple times throughout. This can happen in response to feedback, or because you’re not done with the development of the feature.
6. Perform a final rebase cleanup after the pull request has been approved
After the review is done, it’s good to perform a final cleanup and scrub of the feature branch commit history to remove spurious commits that are not providing relevant information. In some cases – if your team is experienced and they can handle it – you can rebase also during development, but I strongly advise against it.:
1git rebase -i origin/master
(At this point if you have rewritten the history of a published branch and provided that no one else will commit to it or use it, you might need to push your changes using the –force flag).
7. When development is complete record an explicit merge
When finished with the development of the feature branch and reviewers have reviewed your work, merge using the flag –no-ff. This will preserve the context of the work and will make it easy to revert the whole feature if needed. Here are the commands:
1234git checkout master git pull origin mastergit merge --no-ff PRJ-123-awesome-feature
If you followed the advice above and you have used rebase to keep your feature branch up to date, the actual merge commit will not include any changes; this is cool! The merge commit becomes just a marker that stores the context about the feature branch.
For more information have a look at my recent article on the pros and cons of enforcing a merge vs rebase workflow.
Useful .gitconfig option to toggle:
You can instruct git so that any pull uses rebase instead than merge and it preserves while doing so:
12git config --global branch.autosetuprebase always git config --global pull.rebase preserve #(this is a very recent and useful addition that appeared in git 1.8.5)
Not everyone likes to change the default behavior of core commands so you should only incorporate the above if you understand its implications. See Stack Overflow for details on preserve merges.
Conclusions
This should give you plenty of material to get acquainted with workflows, branching models and code collaboration possibilities. For more git rocking follow me @durdn and the awesome @AtlDevtools team. Credits: Inspiration for this post comes partially from this concise and well made gist.
↧
Ford Exec: 'We Know Everyone Who Breaks the Law' Thanks To Our GPS In Your Car - Slashdot
↧
↧
Using deep learning to listen for whales — Daniel Nouri's Blog
Comments:"Using deep learning to listen for whales — Daniel Nouri's Blog"
URL:http://danielnouri.org/notes/2014/01/10/using-deep-learning-to-listen-for-whales/
Since recent breakthroughs in the field of speech recognition and computer vision, neural networks have gotten a lot of attention again. Particularly impressive were Krizhevsky et al.'s seminal results at the ILSVRC 2012 workshop, which showed that neural nets are able to outperform conventional image recognition systems by a large margin; results that shook up the entire field.
Krizhevsky's winning model is aconvolutional neural network (convnet), which is a type of neural net that exploits spatial correlations in 2-d input. Convnets can have hundreds of thousands of neurons (activation units) and millions of connections between them, many more than could be learned effectively previously. This is possible because convnets share weights between connections, and thus vastly reduce the number of parameters that need to be learned; they essentially learn a number of layers of convolution matrices that they apply to their input in order to find high-level, discriminative features.

Figure 1: Example predictions of ILSVRC 2012 winner; eight images with their true label and the net's top five predictions below. (source)
Many papers have since followed up on Krizhevsky's work and some were able to improve upon the original results. But while most attention went into the problem of using convnets to do image recognition, in this article I will describe how I was able to successfully apply convnets to a rather different domain, namely that of underwater bioacoustics, where sounds of different animal species are detected and classified.
My work on this topic began with last year's Kaggle Whale Detection Challenge, which asked competitors to classify two-second audio recordings, some of which had a certain call of a specific whale on them, and others didn't. The whale in question was the North Atlantic Right Whale (NARW), which is a whale species that's sadly nearly extinct, with less than 400 individuals estimated to still exist. Believing that this could be a very interesting and meaningful way to test my freshly acquired knowledge around convolutional neural networks, I entered the challenge early, and was able to reach a pretty remarkable Area Under Curve (AUC) score of 97% after only three days into the competition.
The trick to my early success was that I framed the problem of finding the whale sound patterns as an image reconition problem, by turning the two-second sound clips each into spectrograms. Spectrograms are essentially 2-d arrays with amplitude as a function of time and frequency. This allowed me to use standard convnet architectures quite similar to those Krizhevsky had used when working with the CIFAR-10 image dataset. With one of few differences in architecture stemming from the fact that CIFAR-10 uses RGB images as input, while my spectrograms have one real number value per pixel, not unlike gray-scale images.
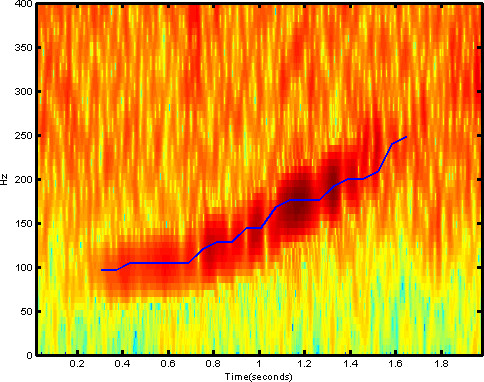
Figure 2: Spectrogram containing a right whale up-call.
Spurred by my success, I registered for the International Workshop on Detection, Classification, Localization, and Density Estimation (DCLDE) of Marine Mammals using Passive Acoustics, in St Andrews. A world-wide community of scientists meets every two years at this workshop to discuss the latest developments in using passive acoustics (listening for sounds) to detect and track marine mammals.
That there was such a breadth of research around this topic was entirely new to me, and it was fascinating to learn about it. Another thing that I've since learned is that this breadth is sadly dwarfed by the amounts of massive underwater noise that humans produce today, through shipping, oil exploration, and military sonar. And this noise severely affects the lives of animals for which "listening is as important as seeing is for humans – they communicate, locate food, and navigate using sound."
The talk that I gave at the DCLDE 2013 workshop was well received. In it, I elaborated how my method relied on little to no problem-specific human engineering, and therefore could be easily adapted to detect and classify all sorts of marine mammal sounds, not just right whale up-calls.
At DCLDE, the execution speed of detection algorithms was frequently quoted as being x times faster than real-time, with x often being a fairly low number around 1 to 10. My GPU-powered implementation turned out to be on the faster side here: on my workstation, it detects and classifies sounds 700x faster than real-time, which means it runs detections on one year of audio recordings in roughly twelve hours, using only a single NVIDIA GTX 580 graphics card.
In terms of accuracy, it was somewhat hard to get an idea of which of the algorithms presented really worked better than others. This had two reasons: the inconsistent use of reliable metrics such as AUC and use of cross-validation, and a lack of standard datasets that everyone could test their algorithms against.
However, it should be mentioned that good datasets are a bit tricky to come by in this field. The nature of hydrophone recordings is that the signal you're listening for could be generated a few meters away, or many kilometers, and therefore be very faint. Plus, recordings often contain a lot of ambient noise coming from cargo ships, offshore drilling, hydrophone cable flutter, and the like. With the effect that often it's hard even for a human expert to tell if the particular sound they're listening to is a vocalization of the mammal they're looking for, or just noise. Thus, analysts will often label segments as unsure, and two analysts will sometimes even give conflicting labels to the same sound.
This leads to a situation where people tend to ignore noisy sounds altogether, since if you consider them, predictions become difficult to verify manually, and good training examples harder to collect. But more importantly, when you ignore sounds with a bad signal-to-noise ratio (SNR), your algorithms will have an easier time learning the right patterns, too, and they will make fewer mistakes. As it turns out, noise is often more of a problem for algorithms than it is for human specialists.
The approach of ignoring sounds with a bad SNR seems fine until you're in a situation where you've put a lot of effort into collecting recordings, and then they turn out to be unusually noisy, and trying to adjust your model's detection threshold yields either way too many false positives detections, or too many calls are missed.
One of the very nice people I met at DCLDE was Holger Klinck from Oregon State University. He wanted to try out my convnet with one of his lab's "very messy" recordings. Some material that his group at OSU had collected at five sites near Iceland and Greenland in 2007 and 2008 had unusually high levels of noise in them, and their detection algorithms had maybe worked less than optimal there.
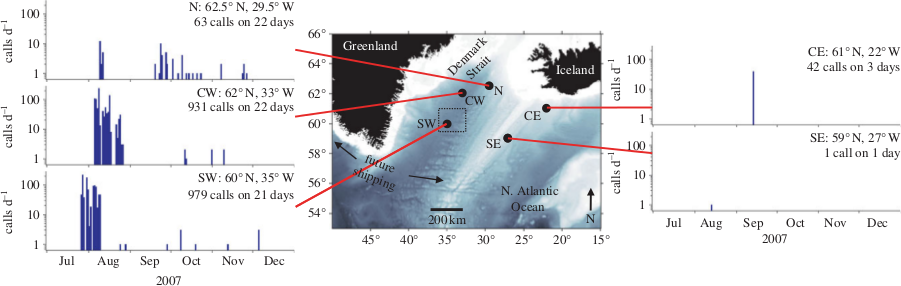
Figure 3: "Locations of passive acoustic moorings near Iceland and southern Greenland (black spots), and the number of right whale upcalls detected per day in late 2007 at the five sites." Taken from . Note the very low number of calls detected at the CE and SE sites.
I was rather amazed when a few weeks later I had a hard disk from OSU in my hands containing in total many years of hydrophone recordings from two sites near Iceland and four locations on the Scotian Shelf. I dusted off the model that I had used for the Kaggle Whale Detection Challenge and quite confidently started running detections on the recordings. Which is when I was in for a surprise: the predictions my shiny 97% model made were all really lousy! Very many obvious non-whale noises were detected wrongly. How was it possible?
To solve this puzzle, I had to understand that the Kaggle Whale Detection Challenge's train and test datasets had a strong selection bias in them. The tens of thousands of examples that I had used to train my model for the challenge were unrepresentative of all whale, and particularly, a lot of similar-sounding non-whale sounds out there. That's because the Kaggle challenge's examples were collected by use of a two-stage pipeline, where an automated detector would first pick out likely candidates from the recording, only after which a human analyst would label them with true or false. I realized that what we were building in the Kaggle challenge was a classifier that worked well only if it had a certain detector running in front of it that would take care of the initial pass of detection. My neural net had thus never seen during training anything like the sounds that it mistook for whale calls now.
If I wanted my convnet to be usable by itself, on continuous audio recordings, and independently of this other detector, I would have to train it with a more balanced training set. And so I ditched most of the training examples I had, and started out with only a few hundred, and trained a new model with them. As was expected, training with only few examples left me with a pretty weak model that would overfit and make lots of obvious mistakes. But this allowed me to pick up the worst mistakes, label them correctly, and feed them back into the system as training examples. And then repeat that. (A process that Olivier Grisel later told me amounts to active learning.)
Many (quite enjoyable) hours of listening to underwater sounds later, I had collected some 2000 training examples this way, some of which were already pretty tricky to verify. And luckily, the newly trained model started to make pretty good predictions. When I sent my results back to Holger, he said that, yes, the patterns I'd found were very similar to those that his group had found for the Scotian Shelf sites!
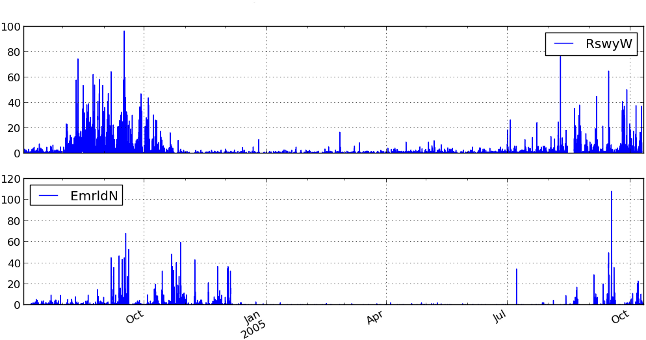
Figure 4: Number of right whale up-call detections per hour at two sites on the Scotian Shelf, detected by the convnet. The numbers and seasonal pattern match with what Mellinger et al. reported in .
The OSU team had used a three-stage detection process to produce their numbers. Humans verified in phases two (broadly) and three (in more detail) the detections that the algorithm came up with in phase one. Whereas my detection results came straight out of the algorithm.
A case-by-case comparison still needs to happen, but the similarities of the overall call patterns suggests that the convnet reaches comparable performance, but without the need for human analysts to be part of the detection pipeline, making it potentially much more time-efficient to use in practice.
What's even more exciting is that the neural net was able to find right whale up-calls at the problematic SE site near Iceland, where previously no up-calls could be detected due to high noise levels.
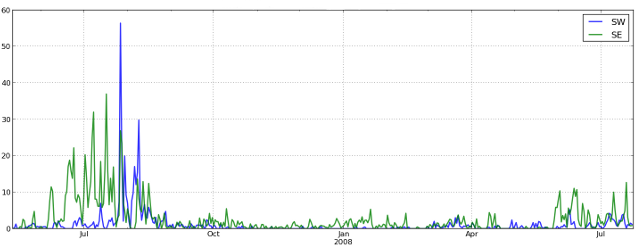
Figure 5: NRW up-call detections per day at sites SW and SE near Iceland, detected by the convnet. The patterns at the SW site match roughly with what was reported in , while no calls could be identified previously at the SE site (cf. Figure 3).
Another thing we're currently looking into is wheter or not the relatively small but constant number of calls that the convnet detected during Winter season are real, or if they're false positives. Right whales are not known to hang around so high up North during that time of the year, so proving that would constitute significant news for people studying the migration routes of these whales.
(Comments also on Hacker News.)
↧
language agnostic - What is your best programmer joke? - Stack Overflow
Comments:"language agnostic - What is your best programmer joke? - Stack Overflow"
URL:http://stackoverflow.com/questions/234075/what-is-your-best-programmer-joke
A Geologist and an engineer are sitting next to each other on a long flight from LA to NY. The Geologist leans over to the Engineer and asks if he would like to play a fun game. The Engineer just wants to take a nap, so he politely declines and rolls over to the window to catch a few winks. The Geologist persists and explains that the game is real easy and a lotta fun. He explains, "I ask you a question, and if you don't know the answer, you pay me $5. Then you ask me a question, and if I don't know the answer, I'll pay you $5." Again, the Engineer politely declines and tries to get to sleep. The Geologist now somewhat agitated, says, "OK, if you don't know the answer you pay me $5, and if I don't know the answer, I'll pay you $50!"
This catches the Engineer's attention, and he sees no end to this torment unless he plays, so he agrees to the game. The Geologist asks the first question. "What's the distance from the Earth to the moon?"
The Engineer doesn't say a word, but reaches into his wallet, pulls out a five dollar bill and hands it to the Geologist.
Now, it's the Engineer's turn. He asks the Geologist, "What goes up a hill with three legs, and comes down on four?" The Geologist looks up at him with a puzzled look. He takes out his laptop computer and searches all of his references. He taps into the Airphone with his modem and searches the net and the Library of Congress. Frustrated, he sends e-mail to his co-workers -- all to no avail.
After about an hour, he wakes the Engineer and hands him $50. The Engineer politely takes the $50 and turns away to try to get back to sleep.
The Geologist is more than a little miffed, shakes the Engineer and asks, "Well, so what's the answer?"
Without a word, the Engineer reaches into his wallet, hands the Geologist $5, and turns away to get back to sleep.
↧
We stopped advertising on Facebook
Comments:"We stopped advertising on Facebook"
URL:http://vpj.svbtle.com/we-stopped-advertising-on-facebook
Or, How to get Facebook “likes”?We (nearby.lk) stopped advertising on Facebook to get Facebook “likes”, because we felt that it was a giant fruitless scheme of making Facebook rich. Most of the “likes” on Facebook are useless, they are basically random clicks, which adds no value to anybody, and you need to pay Facebook for that. By the way, this may not be the case with advertising for Clicks to Website, Website Conversions, etc. - I don’t have experience with those.
We got on Facebook when one of our employees created a fan page for the company, which we later made our official page. Facebook advertising was important for us to get awareness and to build reputation - so that our clients know we are popular because a lot of people like us on Facebook.
It didn’t take us long to realize that the first goal is never met because we got almost no traffic to nearby.lk from Facebook; it was way lower than the number of likes we were getting. What we expected was the other way around - lots people visiting the site and a few “liking” us. “Like” never meant like, it meant click. People who “liked” probably didn’t even know what they clicked, so it didn’t do any marketing for us. Also, more “likes” didn’t mean that there was a large set of users who would see our updates, since most of these people have liked hundreds of pages.
Our second goal, building a reputation, a public available figure to show we are popular, was met. And it still works, because most people don’t know how Facebook “likes” work. They believe we have a lot of likes because we have a great product and people like it. But there’s absolutely no correlation between the two.
This are articles about State Departmentspending $630,000 on Facebook “likes”.
“Many in the bureau criticize the advertising campaigns as ‘buying fans' who may have once clicked on an ad or ‘liked' a photo but have no real interest in the topic and have never engaged further,” reads the Inspector General report.At least they got their “likes” from homeland.
When we launched a prototype in with attractions in India (we didn’t focus on it after launch, it still running our old system), we advertised on Facebook targeting India. With a bit of research while doing that, we realized how most companies in Sri Lanka, which has almost nothing to do with foreign countries, get Facebook likes from countries other than Sri Lanka. They simply advertise targeting other countries, especially developing countries with large populations. And it is cheaper.
For instance the page FYI - Sri Lanka Mobile Directory probably, as its name implies, has nothing to do with Turkey.
Not all companies are stupid enough to let others see their likes are useless. They spread it among a number of countries, while putting a little extra advertising in homeland, so that the most popular country remains to be homeland. To see how they do it you need to go create an ad yourself. I’m not sure how accurate the figures provided by Facebook are, but I’m guessing it should be at least approximately correct.
So it’s all about a race to get more likes, not creating a product that people like. And since these are not genuine likes, number of likes in Facebook becomes just a figure of how much money you can waste on Facebook; that is exchanging your money for Facebook “likes” which has no meaning.
570 Kudos 570 Kudos↧