#!/usr/bin/env bash
# -*- mode: sh; sh-basic-offset: 2 -*-
usage(){
echo"$0 [OPTION] FILE..."
echo
echo"Options:"
echo" -e|--eval STR Evaluate STR"
echo" -l|--load FILE Load and evaluate FILE"
echo" -r|--repl Start a REPL"
exit 2
}
if[[ -z "$BASH_VERSION"]]||((${BASH_VERSINFO[0]}< 4));then
echo"bash >= 4.0 required">&2
exit 1
fi
DEFAULT_IFS="$IFS"
# function return and error slots ##############################################
r=""
e=""
error(){
[[ -z "$e"]]&&e="$1"||e="$1\n$e"
r=$NIL
return 1
}
# pushback reader ##############################################################
pb_max=100
pb_newline="$(printf '\034')"
pb_star="$(printf '\035')"
pb_get="^$"
pb_unget="^$"
history_flag=1
readline(){
local IFS=$'\n\b'prompt="> " line
set -f
read -e -r -p "$prompt" line ||exit 0
pb_get="${pb_get:0:$((${#pb_get}-1))}${line}${pb_newline}$"
set +f
unset IFS
if[["$line"=~ ^[[:space:]]*- ]];then
echo"warning: lines starting with - aren't stored in history">&2
elif[[ -n "$history_flag"]];then
history -s "$line"
fi
}
getc(){
local ch
if((${#pb_get}== 2));then
readline
getc
else
ch="${pb_get:1:1}"
pb_get="^${pb_get:2}"
if((pb_max > 0));then
pb_unget="${pb_unget:0:$((${#pb_unget}-1))}"
pb_unget="^${ch}${pb_unget:1:$((pb_max-1))}$"
else
pb_unget="^${ch}${pb_unget:1}"
fi
r="$ch"
fi
}
ungetc(){
if[["$pb_unget"=="^$"]];then
echo"ungetc: nothing more to unget, \$pb_max=$pb_max">&2 &&return 1
else
pb_get="^${pb_unget:1:1}${pb_get:1}"
pb_unget="^${pb_unget:2}"
fi
}
has_shebangP(){[["$(head -1 $1)"=~ ^#! ]];}
strmap_file(){
local f="$1" contents
if has_shebangP "$f";then
contents="$(tail -n+2 "$f" | sed -e 's/^[ \t]*//' | tr -s '\n' $pb_newline)"
else
contents="$(cat "$f" | sed -e 's/^[ \t]*//' | tr -s '\n' $pb_newline)"
fi
mapped_file="(do $contents nil)"
mapped_file_ptr=0
}
strmap_getc(){
r="${mapped_file:$((mapped_file_ptr++)):1}"
}
strmap_ungetc(){
let --mapped_file_ptr
}
_getc=getc
_ungetc=ungetc
# memory layout & gc ###########################################################
cons_ptr=0
symbol_ptr=0
protected_ptr=0
gensym_counter=0
array_cntr=0
declare -A interned_strings
declare -A car
declare -A cdr
declare -A environments
declare -A recur_frames
declare -A recur_fns
declare -A marks
declare -A global_bindings
declare -a symbols
declare -a protected
declare -a mark_acc
heap_increment=1500
cons_limit=$heap_increment
symbol_limit=$heap_increment
tag_marker="$(printf '\036')"
atag="${tag_marker}003"
declare -A type_tags=([000]=integer
[001]=symbol
[002]=cons
[003]=vector
[004]=keyword)
type(){
if[["${1:0:1}"=="$tag_marker"]];then
r="${type_tags[${1:1:3}]}"
else
r=string
fi
}
strip_tag(){r="${1:4}";}
typeP(){
local obj="$1"tag="$2"
type"$obj"&&[[$r=="$tag"]]
}
make_integer(){r="${tag_marker}000${1}";}
make_keyword(){r="${tag_marker}004${1:1}";}
intern_symbol(){
if[[ -n "${interned_strings[$1]}"]];then
r="${interned_strings[$1]}"
else
symbol_ptr="$((symbol_ptr + 1))"
interned_strings["$1"]="${tag_marker}001${symbol_ptr}"
symbols["$symbol_ptr"]="$1"
r="${tag_marker}001${symbol_ptr}"
fi
}
defprim(){
intern_symbol "$1"&&sym_ptr="$r"
intern_symbol "$(printf '#<primitive:%s>' "$1")"&&prim_ptr="$r"
global_bindings["$sym_ptr"]=$prim_ptr
r="$prim_ptr"
}
cons(){
local the_car="$1"the_cdr="$2"
mark "$the_car"
mark "$the_cdr"
while[[ -n "${marks[${tag_marker}002${cons_ptr}]}"]];do
unset marks["${tag_marker}002$((cons_ptr++))"]
done
if[[$cons_ptr==$cons_limit]];then
gc
fi
unset environments["${tag_marker}002${cons_ptr}"]
unset recur_frames["${tag_marker}002${cons_ptr}"]
unset recur_fns["${tag_marker}002${cons_ptr}"]
car["${tag_marker}002${cons_ptr}"]="$the_car"
cdr["${tag_marker}002${cons_ptr}"]="$the_cdr"
r="${tag_marker}002${cons_ptr}"
cons_ptr="$((cons_ptr + 1))"
}
gensym(){
gensym_counter=$((gensym_counter +1))
intern_symbol "G__${gensym_counter}"
}
new_array(){
r="arr$((array_cntr++))"
declare -a $r
r="${atag}${r}"
}
vset(){
strip_tag "$1"
eval"${r}[${2}]=\"${3}\""
r="$1"
}
vget(){
strip_tag "$1"
eval"r=\${${r}[${2}]}"
}
count_array(){
strip_tag "$1"
eval"r=\${#${r}[@]}"
}
append(){
local i
strip_tag "$1"
eval"i=\${#${r}[@]}"
eval"${r}[${i}]=\"${2}\""
r="$1"
}
append_all(){
strip_tag "$1"
local a1="$r"
strip_tag "$2"
local a2="$r"
local len1 len2
eval"len1=\${#${a1}[@]}"
eval"len2=\${#${a2}[@]}"
local i=0
while((i < len2));do
eval"${a1}[((${i} + ${len1}))]=\"\${${a2}[${i}]}\""
((i++))
done
r="$1"
}
prepend(){
local i len
strip_tag "$2"
eval"len=\${#${r}[@]}"
while((len > 0));do
eval"${r}[${len}]=\"\${${r}[((len - 1))]}\""
((len--))
done
eval"${r}[0]=\"$1\""
r="$2"
}
dup(){
new_array
local aptr="$r"
strip_tag "$aptr"
local narr="$r"
strip_tag "$1"
local len
eval"len=\${#${r}[@]}"
local i=0
while((i < len));do
eval"${narr}[${i}]=\"\${${r}[${i}]}\""
((i++))
done
r="$aptr"
}
concat(){
dup "$1"
append_all "$r""$2"
}
vector(){
local v="$2"
if[["$EMPTY"=="$v"|| -z "$v"||"$NIL"=="$v"]];then
new_array
v="$r"
fi
prepend $1$v
}
protect(){
protected_ptr="$((protected_ptr + 1))"
protected["$protected_ptr"]="$1"
}
unprotect(){protected_ptr="$((protected_ptr - 1))";}
acc_count=0
mark_seq(){
local object="$1"
while typeP "$object" cons &&[[ -z "${marks[$object]}"]];do
marks["$object"]=1
mark_acc[acc_count++]="${car[$object]}"
object="${cdr[$object]}"
done
if typeP "$object" vector ;then
count_array "$object"
local i sz="$r"
for((i=0; i<sz; i++));do
vget "$object"$i
mark_acc[acc_count++]="$r"
done
fi
}
mark(){
acc_count=0
mark_seq "$1"
local i
for((i=0; i<${#mark_acc[@]}; i++));do
mark_seq "${mark_acc[$i]}"
done
mark_acc=()
}
gc(){
echo"GC...">&2
IFS="$DEFAULT_IFS"
mark "$current_env"
for k in "${!environments[@]}";do mark "${environments[$k]}";done
for k in "${!protected[@]}";do mark "${protected[$k]}";done
for k in "${!stack[@]}";do mark "${stack[$k]}";done
for k in "${!global_bindings[@]}";do mark "${global_bindings[$k]}";done
cons_ptr=0
while[[ -n "${marks[${tag_marker}002${cons_ptr}]}"]];do
unset marks["${tag_marker}002$((cons_ptr++))"]
done
if[[$cons_ptr==$cons_limit]];then
echo"expanding heap...">&2
cons_limit=$((cons_limit + heap_increment))
fi
}
# reader #######################################################################
interpret_token(){
[["$1"=~ ^-?[[:digit:]]+$ ]]\
&&r=integer &&return
[["$1"=~ ^:([[:graph:]]|$pb_star)+$ ]]\
&&r=keyword &&return
[["$1"=~ ^([[:graph:]]|$pb_star)+$ ]]\
&&r=symbol &&return
return 1
}
read_token(){
local token=""
while$_getc;do
if[["$r"=~ ('('|')'|'['|']'|[[:space:]]|$pb_newline|,)]];then
$_ungetc&&break
else
token="${token}${r}"
fi
done
[ -z "$token"]&&return 1
if interpret_token "$token";then
case"$r" in
symbol) intern_symbol "$token"&&return;;
integer) make_integer "$token"&&return;;
keyword) make_keyword "$token"&&return;;
*) error "unknown token type: '$r'"
esac
else
error "unknown token: '${token}'"
fi
}
skip_blanks(){
$_getc
while[["$r"=~ ([[:space:]]|$pb_newline|,)]];do$_getc;done
$_ungetc
}
skip_comment(){
$_getc
while[["$r" !="$pb_newline"]];do$_getc;done
}
read_list(){
local ch read1 read2
if lisp_read;then
read1="$r"
else
$_getc
r="$NIL"
return
fi
$_getc&&ch="$r"
case"$ch" in
".")
lisp_read &&read2="$r"
skip_blanks
$_getc
cons "$read1""$read2"
;;
")") cons "$read1"$NIL;;
*)
$_ungetc
read_list
cons "$read1""$r"
esac
}
read_vector(){
local ch read1
if lisp_read;then
read1="$r"
else
getc
r="$EMPTY"
return
fi
skip_blanks
getc
if[["$r"=="]"]];then
vector "$read1""$EMPTY"
else
ungetc
skip_blanks
read_vector
vector "$read1""$r"
fi
}
read_string(){
local s=""
while true;do
$_getc
if[["$r"=="\\"]];then
$_getc
if[["$r"=="\""]];then
s="${s}${r}"
else
s="${s}\\${r}"
fi
elif[["$r"=="\""]];then
break
else
s="${s}${r}"
fi
done
r="$(echo "$s" | tr "$pb_star" '*')"
}
lisp_read(){
local ch read1 read2 read3 read4
skip_blanks;$_getc;ch="$r"
case"$ch" in
"\"")
read_string
;;
"(")
read_list
;;
"[")
read_vector
;;
"'")
lisp_read &&read1="$r"
cons "$read1"$NIL&&read2="$r"
cons $QUOTE"$read2"
;;
";")
skip_comment
lisp_read
;;
*)
$_ungetc
read_token
esac
}
string_list(){
local c="$1" ret
shift
if[["$1"==""]];then
cons $c$NIL&&ret="$r"
else
string_list $*
cons $c$r&&ret="$r"
fi
r="$ret"
}
# printer ######################################################################
printing=
escape_str(){
local i c
r=""
for((i=0; i < ${#1}; i++));do
c="${1:$i:1}"
case"$c" in
\")r="${r}\\\"";;
\\)r="${r}\\\\";;
*)r="${r}${c}"
esac
done
}
str_arr(){
local ret="["
count_array "$1"
local len=$r
if(( 0 != len ));then
vget $1 0
str "$r"
ret="${ret}${r}"
for((i=1 ; i < $len; i++));do
vget $1$i
str "$r"
ret="${ret} ${r}"
done
fi
r="${ret}]"
}
str_list(){
local lst="$1"
local ret
if[["${car[$lst]}"==$FN]];then
strip_tag "$lst"&&printf -v r '#<function:%s>'"$r"
else
ret="("
str "${car[$lst]}"
ret="${ret}${r}"
lst="${cdr[$lst]}"
while typeP "$lst" cons ;do
str "${car[$lst]}"
ret="${ret} ${r}"
lst="${cdr[$lst]}"
done
if[["$lst" !=$NIL]];then
str "$lst"
ret="${ret} . ${r}"
fi
r="${ret})"
fi
}
str(){
type"$1"
case"$r" in
integer) strip_tag "$1"&&printf -v r '%d'"$r";;
cons) str_list "$1";;
vector) str_arr "$1";;
symbol) strip_tag "$1"&&printf -v r '%s'"$(echo "${symbols[$r]}" | tr $pb_star "*")";;
keyword) strip_tag "$1"&&printf -v r ':%s'"$r";;
*)
if[[ -n $printing]];then
escape_str "$1"
printf -v r '"%s"'"$r"
else
printf -v r '%s'"$1"
fi
;;
esac
}
prn(){
printing=1
str "$1"
printing=
printf'%s'"$r"&&echo
}
# environment & control ########################################################
frame_ptr=0
stack_ptr=0
declare -a stack
intern_symbol '&'&&="$r"
intern_symbol 'nil'&&NIL="$r"
intern_symbol 't'&&T="$r"
global_bindings[$NIL]="$NIL"
global_bindings[$T]="$T"
car[$NIL]="$NIL"
cdr[$NIL]="$NIL"
new_array &&EMPTY="$r"
current_env="$NIL"
intern_symbol 'quote'&"E=$r
intern_symbol 'fn'&&FN=$r
intern_symbol 'if'&&IF=$r
intern_symbol 'set!'&&SET_BANG=$r
intern_symbol 'def'&&DEF=$r
intern_symbol 'do'&&DO=$r
intern_symbol 'recur'&&RECUR=$r
intern_symbol 'binding'&&BINDING=$r
declare -A specials
specials[$QUOTE]=1
specials[$FN]=1
specials[$IF]=1
specials[$SET_BANG]=1
specials[$DEF]=1
specials[$DO]=1
specials[$RECUR]=1
specials[$BINDING]=1
defprim 'eq?'&&EQ=$r
defprim 'nil?'&&NILP=$r
defprim 'car'&&CAR=$r
defprim 'cdr'&&CDR=$r
defprim 'cons'&&CONS=$r
defprim 'list'&&LIST=$r
defprim 'vector'&&VECTOR=$r
defprim 'keyword'&&KEYWORD=$r
defprim 'eval'&&EVAL=$r
defprim 'apply'&&APPLY=$r
defprim 'read'&&READ=$r
defprim '+'&&ADD=$r
defprim '-'&&SUB=$r
defprim "$pb_star"&&MUL=$r
defprim '/'&&DIV=$r
defprim 'mod'&&MOD=$r
defprim '<'&<=$r
defprim '>'&>=$r
defprim 'cons?'&&CONSP=$r
defprim 'symbol?'&&SYMBOLP=$r
defprim 'number?'&&NUMBERP=$r
defprim 'string?'&&STRINGP=$r
defprim 'fn?'&&FNP=$r
defprim 'gensym'&&GENSYM=$r
defprim 'random'&&RAND=$r
defprim 'exit'&&EXIT=$r
defprim 'println'&&PRINTLN=$r
defprim 'sh'&&SH=$r
defprim 'sh!'&&SH_BANG=$r
defprim 'load-file'&&LOAD_FILE=$r
defprim 'gc'&&GC=$r
defprim 'error'&&ERROR=$r
defprim 'type'&&TYPE=$r
defprim 'str'&&STR=$r
defprim 'split'&&SPLIT=$r
defprim 'getenv'&&GETENV=$r
eval_args(){
local args="$1"
type"$args"
if[["$r"== cons ]];then
while[["$args" !=$NIL]];do
lisp_eval "${car[$args]}"
stack[$((stack_ptr++))]="$r"
args="${cdr[$args]}"
done
elif[["$r"== vector ]];then
count_array "$args"
local i len="$r"
for((i=0; i<len; i++));do
vget "$args""$i"
lisp_eval "$r"
stack[$((stack_ptr++))]="$r"
done
elif[["$1" !="$NIL"]];then
str "$args"
error "Unknown argument type: $r"
fi
}
listify_args(){
local p=$((stack_ptr -1))ret=$NIL stop
[[ -z "$1"]]&&stop=$frame_ptr||stop="$1"
while((stop <= p));do
cons "${stack[$p]}""$ret"&&ret="$r"
p=$((p -1))
done
r="$ret"
}
vectify_args(){
local stop=$((stack_ptr -1)) ret
new_array
ret="$r"
[[ -z "$1"]]&&p=$frame_ptr||p="$1"
while((p <= stop));do
append "$ret""${stack[$((p++))]}"
done
r="$ret"
}
acons(){
local key="$1"datum="$2"a_list="$3"
cons "$key""$datum"&& cons "$r""$a_list"
}
aget(){
local key="$1"a_list="$2"
while[["$a_list" !=$NIL]];do
if[["${car[${car[$a_list]}]}"=="$key"]];then
r="${cdr[${car[$a_list]}]}"&&return 0
fi
a_list="${cdr[$a_list]}"
done
r=$NIL&&return 1
}
analyze(){
local fn="$1"body="$2"env="$3"
while[["$body" !="$NIL"]];do
type"${car[$body]}"
if[["$r"== cons ]];then
case"${car[${car[$body]}]}" in
$FN) environments["${car[$body]}"]="$env";;
$RECUR)
recur_fns["${car[$body]}"]="$fn"
recur_frames["${car[$body]}"]="$frame_ptr"
;;
*) analyze "$fn""${car[$body]}""$env";;
esac
fi
body="${cdr[$body]}"
done
}
copy_list(){
local lst="$1"copy="$NIL"prev="$NIL"curr="$NIL"
while[["$lst" !="$NIL"]];do
cons "${car[$lst]}""$NIL"&&curr="$r"
if[["$copy"=="$NIL"]];then
copy="$curr"
else
cdr["$prev"]="$curr"
fi
prev="$curr"
lst="${cdr[$lst]}"
done
r="$copy"
}
apply_user(){
local fn="$1"
local body="${cdr[${cdr[$fn]}]}"
local params="${car[${cdr[$fn]}]}"
local p="$frame_ptr"
local ret="$NIL"
local old_env
[[ -z "${environments[$fn]}"]]&&local env=$NIL||local env="${environments[$fn]}"
type"$params"
local ptype="$r"
if[["$ptype"=="cons"]];then
while[["$params" !=$NIL&&"${car[$params]}" !=$AMP]];do
acons "${car[$params]}""${stack[$((p++))]}""$env"&&env="$r"
params="${cdr[$params]}"
done
if[["${car[$params]}"==$AMP]];then
listify_args "$p"&&local more="$r"
acons "${car[${cdr[$params]}]}""$more""$env"&&env="$r"
fi
elif[["$ptype"=="vector"]];then
local i=1 len
count_array "$params"
len="$r"
vget $params 0
while((i <= len))&&[["$r" !=$AMP]];do
acons "$r""${stack[$((p++))]}""$env"&&env="$r"
vget $params$((i++))
done
if[["$r"=="$AMP"]];then
listify_args "$p"&&local more="$r"
vget $params$i
acons "$r""$more""$env"&&env="$r"
fi
elif[["$params" !=$NIL]];then
error "Illegal type (${ptype}) for params in function"
return 1
fi
analyze "$fn""$body""$env"
old_env="$current_env"
current_env="$env"
do_ "$body"&&ret="$r"
current_env="$old_env"
r="$ret"
}
eval_file(){
strmap_file "$1"
_getc=strmap_getc
_ungetc=strmap_ungetc
lisp_read
_getc=getc
_ungetc=ungetc
protect "$r"
lisp_eval "$r"
unprotect
}
check_numbers(){
while[[ -n "$1"]];do
if ! typeP "$1" integer ;then
str "$1"
error "'$r' is not a number"
return 1
fi
shift
done
}
rev_str(){
local i rev=""
for((i=0; i < ${#1}; i++));do
rev="${1:$i:1}${rev}"
done
r="$rev"
}
apply_primitive(){
local primitive="$1"
local arg0="${stack[$frame_ptr]}"
local arg1="${stack[$((frame_ptr+1))]}"
local arg2="${stack[$((frame_ptr+2))]}"
r=$NIL
case$primitive in
$EQ)[["$arg0"=="$arg1"]]&&r="$T";;
$NILP)[["$arg0"==$NIL]]&&r="$T";;
$CAR)r="${car[$arg0]}";;
$CDR)r="${cdr[$arg0]}";;
$CONS) cons "$arg0""$arg1";;
$LIST) listify_args ;;
$VECTOR) vectify_args ;;
$KEYWORD)
type"$arg0"
case$r in
string) make_keyword "$arg0";;
keyword)r="$arg0";;
*)
strip_tag "$arg0"
error "Unable to make keyword from: $r"
r="$NIL"
esac
;;
$STR)
listify_args &&strs="$r"
local ret=""
while[["$strs" !="$NIL"]];do
str "${car[$strs]}"
ret="${ret}$r"
strs="${cdr[$strs]}"
done
r="$ret"
;;
$SPLIT)
local i ret="$NIL"last=0
rev_str "$arg1"&&local rev="$r"
for((i=0; i < ${#rev}; i++));do
if[["${rev:$i:1}"=="$arg0"]];then
rev_str "${rev:$last:$((i - last))}"
cons "$r""$ret"&&ret="$r"
last="$((i + 1))"
fi
done
if((last != 0));then
rev_str "${rev:$last:$((${#rev} - last))}"
cons "$r""$ret"&&ret="$r"
fi
r="$ret"
;;
$GETENV)
[[ -n "$arg0"]]&&eval"r=\$${arg0}"
[[ -z "$r"]]&&r=$NIL
;;
$EVAL) lisp_eval "$arg0";;
$READ) lisp_read ;;
$MOD)
if check_numbers "$arg0""$arg1";then
strip_tag "$arg0"&&local x="$r"
strip_tag "$arg1"&&local y="$r"
make_integer $((x % y))
fi
;;
$LT)
if check_numbers "$arg0""$arg1";then
strip_tag "$arg0"&&local x="$r"
strip_tag "$arg1"&&local y="$r"
((x < y))&&r=$T||r=$NIL
fi
;;
$GT)
if check_numbers "$arg0""$arg1";then
strip_tag "$arg0"&&local x="$r"
strip_tag "$arg1"&&local y="$r"
((x > y))&&r=$T||r=$NIL
fi
;;
$CONSP) typeP "$arg0" cons &&r=$T;;
$SYMBOLP) typeP "$arg0" symbol &&r=$T||r=$NIL;;
$NUMBERP) typeP "$arg0" integer &&r=$T||r=$NIL;;
$STRINGP) typeP "$arg0" string &&r=$T||r=$NIL;;
$FNP) typeP "$arg0" cons &&[["${car[$arg0]}"==$FN]]&&r=$T;;
$GC) gc &&r=$NIL;;
$GENSYM) gensym ;;
$ADD)
if check_numbers "$arg0""$arg1";then
strip_tag "$arg0"&&local x="$r"
strip_tag "$arg1"&&local y="$r"
make_integer $((x + y))
fi
;;
$SUB)
if check_numbers "$arg0""$arg1";then
strip_tag "$arg0"&&local x="$r"
strip_tag "$arg1"&&local y="$r"
make_integer $((x - y))
fi
;;
$APPLY)
local old_frame_ptr=$frame_ptr
frame_ptr=$stack_ptr
type"$arg1"
case$r in
cons)
while typeP "$arg1" cons;do
stack[$((stack_ptr++))]="${car[$arg1]}"
arg1="${cdr[$arg1]}"
done
[[$arg1 !=$NIL]]&& error "Bad argument to apply: not a proper list"
;;
vector)
count_array "$arg1"
local len="$r"
for((i=0; i<len; i++));do
vget "$arg1""$i"
stack[$((stack_ptr++))]="$r"
done
;;
*) error "Bad argument to apply: not a list"
esac
if[[ -z "$e"]];then
apply "$arg0"
fi
stack_ptr=$frame_ptr
frame_ptr=$old_frame_ptr
;;
$ERROR)
printf'lisp error: '>&2
prn "$arg0">&2
;;
$TYPE)
if[["$arg0"==$NIL]];then
r=$NIL
else
type"$arg0"
if[["$r"== cons ]]&&[["${car[$arg0]}"==$FN]];then
intern_symbol "function"
else
intern_symbol "$r"
fi
fi
;;
$MUL)
if check_numbers "$arg0""$arg1";then
strip_tag "$arg0"&&local x="$r"
strip_tag "$arg1"&&local y="$r"
make_integer $((x * y))
fi
;;
$DIV)
local x y
if check_numbers "$arg0""$arg1";then
strip_tag $arg0&&x=$r
strip_tag $arg1&&y=$r
make_integer $((x / y))
fi
;;
$RAND)
if check_numbers "$arg0";then
strip_tag $arg0
make_integer "$((RANDOM % r))"
fi
;;
$PRINTLN)
listify_args &&local to_print="$r"
while[["$to_print" !="$NIL"]];do
type"${car[$to_print]}"
case"$r" in
string)
echo -e "${car[$to_print]}"
;;
*) prn "${car[$to_print]}"
;;
esac
to_print="${cdr[$to_print]}"
done
r="$NIL"
;;
$SH)
local ret
eval"ret=\$(${arg0})"
IFS=$'\n'
string_list $(for i in $ret;do echo"$i";done)
IFS="$DEFAULT_IFS"
;;
$SH_BANG)
eval"${arg0}"
[[$?== 0 ]]&&r=$T||r=$NIL
;;
$LOAD_FILE)
local f
if[[ -r ${arg0}]];then
f="${arg0}"
elif[[ -r "${arg0}.gk"]];then
f="${arg0}.gk"
fi
if[["$f" !=""]];then
eval_file "$f"
else
echo"File not found: ${arg0}">&2
r="$NIL"
fi
;;
$EXIT)
strip_tag $arg0
exit"$r"
;;
*) strip_tag "$1"&& error "unknown primitive function type: ${symbols[$r]}"
return 1
esac
}
apply(){
if[["${car[$1]}"=="$FN"]];then
apply_user "$1"
else
apply_primitive "$1"
fi
}
add_bindings(){
type"$1"
if[[$r== cons ]];then
local pairs="$1" val
while[["$pairs" !=$NIL&&"${cdr[$pairs]}" !=$NIL]];do
lisp_eval "${car[${cdr[$pairs]}]}"&&val="$r"
if[[ -n "$e"]];then return 1;fi
acons "${car[$pairs]}""$val""$current_env"&¤t_env="$r"
pairs="${cdr[${cdr[$pairs]}]}"
done
if[["$pairs" !=$NIL]];then
error "Bad bindings. Must be an even number of binding forms."
return 1
fi
elif[["$r"== vector ]];then
count_array "$1"
local i v len="$r"
if(( len % 2== 0 ));then
for((i=0; i<len;));do
vget "$1"$((i++))
v="$r"
vget "$1"$((i++))
lisp_eval "$r"
if[[ -n "$e"]];then return 1;fi
acons "$v""$r""$current_env"&¤t_env="$r"
done
else
error "Bad bindings. Must be an even number of binding forms."
fi
else
error "bindings not available."
fi
}
do_(){
local body="$1"result="$NIL"
while[["$body" !=$NIL]];do
lisp_eval "${car[$body]}"&&result="$r"
body="${cdr[$body]}"
done
if typeP "$result" cons &&[["${car[$result]}"=="$FN"]];then
copy_list "$result"
environments["$r"]="$current_env"
else
r="$result"
fi
}
eval_special(){
local special="$1"
local op="${car[$1]}"
local args="${cdr[$1]}"
local arg0="${car[$args]}"
local arg1="${car[${cdr[$args]}]}"
local arg2="${car[${cdr[${cdr[$args]}]}]}"
case$op in
$QUOTE)r="$arg0";;
$DO) do_ $args;;
$FN)r=$special;;
$IF)
lisp_eval "$arg0"
[["$r" !="$NIL"]]&& lisp_eval "$arg1"|| lisp_eval "$arg2"
;;
$SET_BANG)
if[[ -n "${global_bindings[$arg0]}"]];then
lisp_eval "$arg1"&& global_bindings[$arg0]="$r"
else
strip_tag "$arg0"&& error "unbound variable: ${symbols[$r]}"
fi
;;
$RECUR)
frame_ptr="${recur_frames[$1]}"
stack_ptr=$frame_ptr
while[["$args" !=$NIL]];do
lisp_eval "${car[$args]}"
stack[$((stack_ptr++))]="$r"
args="${cdr[$args]}"
done
current_env="${environments[$1]}"
apply_user "${recur_fns[$1]}"
;;
$DEF)
lisp_eval "$arg1"&& global_bindings["$arg0"]=$r
r="$arg0"
;;
$BINDING)
local binding_body="${cdr[$args]}"
local old_env="$current_env"
add_bindings $arg0
if[[ -z "$e"]];then
do_ $binding_body
fi
current_env="$old_env"
;;
*)
strip_tag $op
error "eval_special: unknown form: ${symbols[$r]}"
esac
}
eval_function(){
local op="${car[$1]}" eval_op
local args="${cdr[$1]}"
local old_frame_ptr=$frame_ptr
frame_ptr=$stack_ptr
lisp_eval "$op"&&eval_op="$r"
if[[ -z "$e"]];then
protect "$eval_op"
eval_args "$args"
if[[ -z "$e"]];then
apply "$eval_op"
fi
unprotect
fi
stack_ptr=$frame_ptr
frame_ptr=$old_frame_ptr
}
lisp_eval(){
type$1
case$r in
symbol)
[["$1"=="$NIL"]]&&r="$NIL"&&return
[["$1"=="$T"]]&&r="$T"&&return
aget "$1""$current_env"&&return
if[[ -n "${global_bindings[$1]}"]];then
r="${global_bindings[$1]}"
else
strip_tag "$1"&& error "unable to resolve ${symbols[$r]}"
fi
;;
cons)
if[[ -n "${specials[${car[$1]}]}"]];then
eval_special "$1"
else
eval_function "$1"
fi
;;
vector)
local old_frame_ptr=$frame_ptr
local old_stack_ptr=$stack_ptr
frame_ptr=$stack_ptr
eval_args "$1"
if[[ -z "$e"]];then
vectify_args
fi
stack_ptr=$old_stack_ptr
frame_ptr=$old_frame_ptr
;;
integer)r=$1;;
string)r="$1";;
keyword)r="$1";;
*)
error "lisp_eval: unrecognized type"
return 1
;;
esac
}
# repl #########################################################################
init_history(){
intern_symbol "${pb_star}1"&&hist1="$r"
intern_symbol "${pb_star}2"&&hist2="$r"
intern_symbol "${pb_star}3"&&hist3="$r"
global_bindings["$hist1"]="$NIL"
global_bindings["$hist2"]="$NIL"
global_bindings["$hist3"]="$NIL"
}
update_history(){
global_bindings["$hist3"]="${global_bindings[$hist2]}"
global_bindings["$hist2"]="${global_bindings[$hist1]}"
global_bindings["$hist1"]="$r"
}
repl(){
init_history
while true;do
e=# clear existing error state
lisp_read
[[ -n "$e"]]&&printf"read error: $e\n">&2
protect "$r"
lisp_eval "$r"
update_history
[[ -n "$e"]]&&printf"eval error: $e\n">&2
prn "$r"
[[ -n "$e"]]&&printf"print error: $e\n">&2
unprotect
done
}
# start ########################################################################
eval_string(){
local str="$1"
lisp_read <<<"(do $str)"
protect "$r"
lisp_eval "$r"
unprotect
}
# Start REPL if no arguments
[ -z "$*"]&& repl
# Process parameters
while["$*"];do
param=$1;shift;OPTARG=$1
case$param in
-e|--eval) eval_string "$OPTARG";shift
[[$r !=$NIL]]&& prn $r
;;
-l|--load) eval_file "$OPTARG";shift
[[$r !=$NIL]]&& prn $r
;;
-t|--test);;
-r|--repl) repl ;;
-*) usage ;;
*) eval_file "$param"
[[$r !=$NIL]]&& prn $r
;;
esac
done










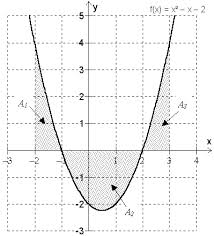 In the context of our sine-wave, I’m pretty sure I could make a good reference to calculus, because this concept has a lot to do with the area under the curve, but I’ll get it wrong, and I won’t hear the end of it in the comments.
In the context of our sine-wave, I’m pretty sure I could make a good reference to calculus, because this concept has a lot to do with the area under the curve, but I’ll get it wrong, and I won’t hear the end of it in the comments.
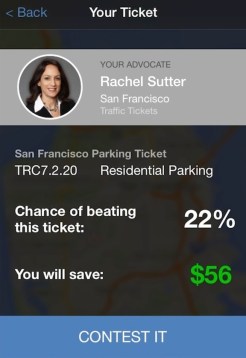 Sure, you could say he should have been more careful/not parked like an idiot. But in many cities, and especially San Francisco, parking rules are very complicated. Even if you manage to follow them all, the police and meter maids screw up sometimes too and wrongly give you a ticket.
Sure, you could say he should have been more careful/not parked like an idiot. But in many cities, and especially San Francisco, parking rules are very complicated. Even if you manage to follow them all, the police and meter maids screw up sometimes too and wrongly give you a ticket.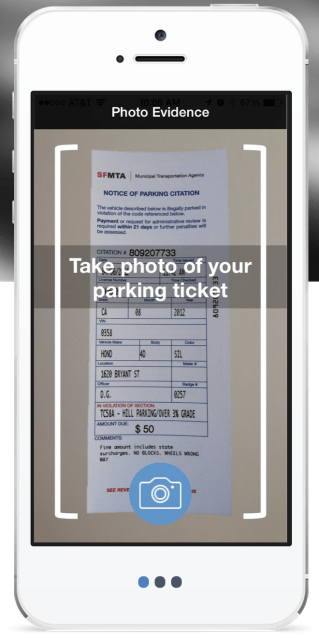 The idea was so popular that Fixed filled up its early beta group in SF almost as soon as it launched its site, but you can sign up for the waiting list now.
The idea was so popular that Fixed filled up its early beta group in SF almost as soon as it launched its site, but you can sign up for the waiting list now.



