↧
You Should Buy These - All Products
↧
Ad blockers: A solution or a problem?
Comments:"Ad blockers: A solution or a problem?"
URL:http://www.computerworld.com/s/article/print/9245190/Ad_blockers_A_solution_or_a_problem_
It's a cause. It's a curse. It's just business. Ad blockers take a bite out of the $20 billion digital advertising pie.
Robert L. Mitchell
January 15, 2014(Computerworld)
For Mauricio Freitas, publisher of the New Zealand Geekzone website for mobile enthusiasts, ad blocking software has been a major headache. Last year his site lost more than one quarter of its display ad impressions because of visitors running these increasingly popular -- and free -- browser add-ons that filter out advertising before users ever see it. "We serve about two million page views a month. The impact on our revenues has been significant," he says.
Viewing ads is part of the deal if users want content to be free, says Freitas. The use of ad blocking software breaks that implicit contract. What's more, he continues, the vast majority of visitors who use ad blockers aren't interested in making even a small payment in exchange for an ad-free site. Only 1,000 of Geekzone's 350,000 unique monthly visitors have been willing to pay $25 a year for an ad-free option, even when Freitas has thrown in other perks.
And some believe that today's ads aren't as obnoxious as yesterday's. "We all hate the dancing monkey and display ads that blink at us," says Mike Zaneis, senior vice president at the Interactive Advertising Bureau (IAB), a trade group that represents publishers and ad sellers. "Do you see larger ads, or sponsored ads today that take over the entire page for three seconds? Absolutely. But they're not the spammy, irrelevant messages that most of us think of from five years ago." The problem for publishers, he says, is that most ad blockers don't just block annoying or intrusive ads -- they block everything.
On the other hand, there are publishers who agree that users of ad blockers have a point about obnoxious ads. "We are all frustrated and upset when we go to a quality publication and see ads for flat belly diets or pop-under ads," says Erik Martin, general manager at Reddit, which uses a limited amount of display advertising.
He thinks that people are being pushed into wanting to use ad-blockers. "There's a whole generation that doesn't even see most of the ads on the Internet, and the industry has put its head in the sand about dealing with it."
In fact, Till Faida and other distributors of ad-blocking software see their mission as a cause. Faida, president of Adblock Plus, the best-known ad blocking software -- the business claims to have 60 million users worldwide -- says ad blockers empower users to combat a rising tide of intrusive and annoying ads. "People should have the freedom to block what they don't like," he says.
But ad blocking is more than just a cause. It's a business, a rapidly growing one that's taking a bite out of the multi-billion dollar market for online search and display advertising.
Billion-dollar blockers
The stakes for publishers (including the publisher of this site, IDG) and advertisers are high. In the first half of 2013, advertisers spent $20.1 billion on Internet advertising in the U.S., including $6.1 billion on display advertising, according to the IAB's Internet Advertising Revenue Report (PDF). Adblock Plus claims that about 6% of all Web surfers in the U.S. run its open-source software, mostly in the form of Google Chrome and Firefox browser add-ons and extensions.
Currently, publishers that cater to a technically savvy audience, such as gaming sites, seem to be getting hit the hardest. Niero Gonzalez, CEO of gaming community Destructoid, is seeing a block rate between 36% and 42%. "Ad blocking hurts the small enthusiast sites the most," he says, and adds that he's not sure the old revenue model based on display ads will ever recover.
Gonzales has conducted an ongoing dialog with his customers since discovering the problem last March, and says that, in general, visitors to his site tend to fall into one of three camps: "One says advertising is evil, another says I don't want to do [ad blocking] so give me an option, and the others just don't care." When he presented an option for an ad-free experience, less than 1% of his 4 million unique monthly visitors signed up for the $2.99/month subscription.
And as the number of ad-blocking software downloads continues to climb, even sites that serve a less technical audience are starting to feel the effects. Most publishers don't want to speak on the record for fear of alienating their customers, but a recently departed executive with one publisher in Alexa Internet Inc.'s ranking of the top 100 listing of global websites says that between 4% and 8% of the business' traffic -- its sites generate over one billion page views per month -- is being blocked. "It's a ton of money," with lost revenues in the millions of dollars, he says.
The business of blocking
Ad blocking has become a business opportunity, and the publishers and advertising networks publishers aren't happy about it. "You have a third party disrupting a business transaction. They are throwing a monkey wrench into the economic engine that's driving the growth of the Internet," the IAB's Zaneis says.
Ad blocker vendors are pursuing a range of different business models, some of which have attracted money from angel investors and venture capital firms that hope to profit as the adoption of the tools continues to expand.
The most controversial business model, put forward by Adblock Plus, offers to help publishers recapture ad impressions lost to its product by signing on to its Acceptable Ads program. To qualify, a publisher's ads must meet Adblock Plus' conditions for non-intrusiveness and pass a review by the open-source community before being approved. Adblock Plus then adds the site to its whitelist. Ads on whitelisted sites pass through Adblock Plus's filters by default (although users can still change the settings to ignore the whitelist).
The catch? Adblock Plus charges large publishers an undisclosed fee to restore their blocked ads.
Faida declined to disclose how his firm determines who pays or the fee structure, other than to say that it varies with the company's size and the work required to include the publisher's ads in its whitelists. Tim Schumacher, the founder of domain marketplace Sedo and Adblock Plus' biggest investor, says some companies have been asked to pay flat fees, while other contracts have been "performance-based" -- that is, linked to the volume of recaptured ad impressions and associated advertising revenue. Currently, 148 publishers participate in the Acceptable Ads program; 90% of participants in the program aren't charged at all, Schumacher says.
And getting into the Acceptable Ads program isn't easy. According to Adblock Plus, it rejected 50% of 777 whitelist applicants because of unacceptable ads; the overall acceptance rate stands at just 9.5%.
[[To find out more about Adblock Plus, check out our interview with Tim Schumacher.]]
Adblock Plus has stuck a deal with at least one marquee customer -- Google signed on as a paying customer in June 2013. The deal covers its search ads as well as sponsored search results on Google and its AdSense for Search partner sites.
Since those search ads are mostly text-based, qualifying for the program was less difficult than for publishers that rely on display advertising. The deal ensures that Google's search ads will appear on affiliate sites even when other ad content is blocked. A Google spokesperson declined to discuss the terms of the deal or whether it was "performance-based," but the potential upside for Google may have made the deal a no-brainer. Last year the company earned $31 billion just on ads published on its own websites. If Google were to recapture even 1% of that amount from ads blocked by Adblock Plus, the deal would deliver a huge return on investment, according to Ido Yablonka, CEO of ClarityRay, a company that helps publishers deal with ad blockers.
(Google appears to be less comfortable with the encroachment of ad blockers in the mobile space, where ad revenues are skyrocketing, according to the IAB. Last March Google removed Adblock Plus from its Google Play store.)
"It would almost be malfeasance for them not to sign onto this," says Zaneis. "But what about the businesses that don't make billions of dollars a year?" Small publishers may lack the technology to know whether or not their ads are being blocked or to put up countermeasures, he says. Schumacher concedes that Adblock Plus needs to do a better job making publishers aware of the problem, as well as its solution.
Reddit, which (as previously mentioned) uses only a small amount of display advertising, was one of the first publishers approached by Adblock Plus and became an early participant in the Acceptable Ads program. "We never paid them, and we wouldn't do that if they did ask us," says Martin.
On the other hand, the former executive at the Alexa top-ranking site said an Adblock Plus representative told him he had to pay even though Adblock Plus agreed that the publisher's ads were acceptable and should not be blocked. "If we didn't pay they would continue to block us. To me it seems like extortion," he says.
Faida says Adblock Plus needs money from big publishers to support the program. "Larger organizations that want to participate must support us financially to make sure that the initiative is sustainable," he says. "The idea is, despite the growing rate of ad blocking, for websites to still have a way to monetize ads."
Finding a middle ground
If Faida feels any sense of irony that his business model seeks remuneration from publishers that have suffered financial damage inflicted by a product his business distributes, he doesn't show it. Rather, he frames the argument in terms of moving away from the current "black and white approach," where all ads are blocked, to "finding a middle ground."
But where is the middle? What constitutes an annoying ad is subjective, but Faida says Adblock Plus has worked with the open-source community to develop and publish its acceptable ad guidelines. "Ads must be static -- no animations or blinking banners, they must be separated from content and clearly marked as ads," he says.
That's not viable, says Rob Beeler, vice president of content and media at AdMonsters LLC, a research and consulting firm that serves advertising professionals. "It's technically possible to adhere to their guidelines, but the CPMs [cost per impression] I would be able to get would be so low that it probably isn't worth it to most publishers."
In fact, he doubts that most publishers can afford to take "such extreme measures" as abiding by the conditions of Adblock Plus' program, especially when the digital advertising market has been moving toward high production quality ads with rich text and digital video.
And signing a deal with Adblock Plus won't make the problem go away entirely. The Acceptable Ads program has been controversial within the Adblock open-source community as well.
Some people took issue with the concept of opting Adblock Plus users into the whitelist by default, says Schumacher. The controversy split the community after the program was announced in December 2011 and led to the development of Adblock Edge, a version of Adblock that does not support acceptable ads -- or even offer an option for users to opt into such a program.
Other ad-blocker strategies
There are other ad blockers out there that don't monetize using this type of approach.
Some offer pay-what-you-want and/or "freemium" services. For example, the similarly named AdBlock, a competitor to Adblock Plus operated by former Google engineer Michael Gundlach, accepts donations and has no external investors.
Another service called Disconnect offers an add-on by the same name whose primary objective is to block tracking scripts -- but in so doing, it also blocks website ads relayed from third-party advertising networks. Disconnect's co-CEO Casey Oppenheim says his pay-what-you-want business model has taken off, with 3% of users contributing and 20% of new paying users choosing to subscribe annually. (There's also the chance that Disconnect will offer premium for-pay features in the future.) "Online privacy is a mass-market opportunity for the first time," he says. Which may explain why the company has drawn more than $4 million from venture capitalists.
(Faida at Adblock Plus declined to say how much money its investors have put up, but Schumacher, the biggest investor, says it's less than what Disconnect has raised so far.)
Ghostery, owned by marketing firm Evidon, doesn't block ads by default, but lets users block ads selectively after presenting information about the ads and companies behind them. Evidon's "data donation" business model asks users to opt into its GhostRank panel, which allows Evidon to collect anonymized data on the tracking elements and the webpages that Ghostery users visit.
Countermeasures
There is no historical model publishers can look to in dealing with these issues, says Harold Furchtgott-Roth, a former FCC commissioner who is now a senior fellow and director at the Center for the Economics of the Internet at the Hudson Institute. "In the traditional media markets, the publishers deal with a finite number of content providers. On the Internet you have essentially an infinite number of places to go," he says. If publishers push users with ad blockers too hard, those users -- and their friends -- will just go somewhere else. And with so many choices, he says, users don't care if a publisher goes out of business.
That said, there are in fact companies that say they can help publishers with ad blocking issues.
For example, PageFair offers a free JavaScript program that, when inserted into a Web page, monitors ad blocking activity. CEO Sean Blanchfield says he developed the monitoring tool after he noticed a problem on his own multiplayer gaming site. PageFair collects statistics on ad blocking activity, identifies which users are blocking ads and can display an appeal to users to add the publisher's website to their ad-blocking tool's personal whitelist. But Blanchfield acknowledges that the user appeal approach hasn't been very effective.
ClarityRay takes a more active role. Like PageFair, it provides a tool that lets publishers monitor blocking activity to show them that they have a problem -- and then sells them a remedy. ClarityRay offers a service that CEO Ido Yablonka says fools ad blockers into allowing ads through. "Ad blockers try to make a distinction between content elements and advertorial elements. We make that distinction impossible," he says.
His customers declined to be identified on the record, but sites given to Computerworld to try did continue to display ads with AdBlock or Adblock Plus running, and a former executive at one publisher -- the Alexa top 100 firm -- says the business has used the service to recapture about $2.5 million in blocked ad impressions annually.
But that doesn't work for all publishers. Destructoid.com's Gonzalez isn't comfortable using a service such as ClarityRay that's designed to defeat ad blocking. "Fighting the people who want to block us is a quick way to lose those readers," he says. "So a product like ClarityRay, for us, would be a last resort."
As one would expect, Yablonka is a vocal advocate for the publishers who are his potential customers. "Content owners should have final control over the page," he says. But while he sees his service as helping recapture revenues, he acknowledges that his business model, which takes a cut of recaptured ad revenues, benefits from the "malfeasance" of ad blockers. So, he says, ClarityRay is moving away from fixed CPM (cost per impression) model "so we don't have a vested interest in seeing the problem become bigger."
Going forward, he says, ClarityRay will charge a percentage of CPM cost over the publisher's entire ad inventory, rather than taking a cut of the value of recovered ad impressions.
Watching the consumer
Alan Chapell, president of consumer privacy law firm Chapell & Associates, says the rise of ad blockers has created a tug-of-war between publishers and ad blocking product developers, with users in the middle. "There's confusion around who owns the user," he says.
With publishers so far unable to successfully implement paywalls or other alternative revenue strategies at scale, growth in the use of ad blockers poses an existential threat to the economics of the Internet, says Furchgott-Roth. "If the ad blocking groups prevail, it will substantially erode the business model for providing online content for free. You'll see a lot of websites disappear." But, he adds, "Other business models will take their place."
Everything turns on what consumers do next.
Existing users of ad blocking software may be a lost cause. Once consumers decide to block ads and experience the cleaner Web pages and faster load times that ad blocking delivers as it filters out bandwidth-hungry animations, video and other advertising content, they're less likely to want to give it up.
But will mainstream consumers in the U.S. turn to ad blockers in a big way? "The numbers have not reached the point where publishers are panicked," says Chapell. "But if those products were on 80% of computers, we'd be having a very different conversation."
Schmacher says adoption rates in Europe could be a harbinger of what's ahead for the U.S. In Germany, for example, about 15% of users run ad blockers -- three times the rate in U.S. But Europe is also very different from the U.S. in two key respects, he says: Europeans are more vigilant when it comes to privacy and ad tracking issues, and as part of its antitrust case against Microsoft, EU regulators insisted that consumers be given a choice of browsers on computers they purchased. Many chose Firefox, he says, where ad blocker add-ons have made the biggest gains.
With billions in ad revenue at stake, there's a big incentive for advertisers and publishers to figure out a way to preserve the current business model. And in the arena of countermeasures, ClarityRay's approach may be just the first volley. While Schumacher admits that the "URL-swapping" mechanism used by ClarityRay works, he says Adblock can easily make modifications to defeat it if more sites start using that service. But, he admits, ClarifyRay and others will probably move on to other methods to fool ad blockers, and that could be the start of an arms race between the big publishers and ad blockers.
Furchgott-Roth thinks that's a battle that the ad blockers would have a hard time winning. "The economic model between sites and advertisers is so powerful that they will figure out some way to allow this to continue." And it won't be just the small startups like ClarityRay and PageFair, each with about $500,000 in backing, that the ad blocking vendors will need to worry about. Ultimately, he says, "Google has more money to invest in this than do the ad blocking companies."
For some smaller publishers catering to more tech-savvy audiences, dealing with the effects of ad blocking is fast becoming a matter of survival. Since appeals to users haven't worked at Geekzone, Freitas is trying to deal with the declining ad revenue problem by coming up with other ways to generate income. For example, he has developed a sponsored tech blog where community members receive early releases of new mobile phones in exchange for writing about their experiences in a blog. "They can write anything they want, and Telecom New Zealand pays for that," he says.
With display ad revenues declining and paid contributions a tiny fraction of revenues, such models are the key to recovery. "The big takeaway for publishers is that you have to have a diversified income stream to survive," he says.
This article, Ad blockers: A solution or a problem?, was originally published at Computerworld.com.
Robert L. Mitchell is a national correspondent for Computerworld. Follow him on Twitter at ![]() twitter.com/rmitch, or e-mail him at rmitchell@computerworld.com.
twitter.com/rmitch, or e-mail him at rmitchell@computerworld.com.
↧
↧
Chrome Is The New C Runtime | MobileSpan
Comments:"Chrome Is The New C Runtime | MobileSpan"
URL:https://www.mobilespan.com/content/chrome-is-the-new-c-runtime
Cross-platform app development is more important than ever. 10 years ago, you just whipped out your Visual Studio when you needed a client application, but not anymore. With “app-ification” going mainstream on Android, iOS, Windows, and Mac, what is a developer to do?
Web apps are a good solution some of the time (except for that little detail called IE!).
But what about when you need the features and performance of native code, across platforms? And you’re a startup with a small team and impossible deadlines?
Well, at MobileSpan we’ve been living in this world for the past 2 years, and we want to share our approach.
We chose to build our application by integrating with the source code of Chromium.
Chromium is the open-source base of Google Chrome. My co-founder and I are Xooglers from the Chrome team, so we were very familiar with it and it was an easy choice for us. But you don't have to spend 4 years at Google to take advantage of Chrome's rich code base.
But... I'm not building a browser!
So, why would Chrome source be useful to me for cross-platform app development? I'm not building a browser...
In reality, Chrome is much more than just a browser. Chrome code is highly tuned for performance, reliability, and cross-platform compatibility across PCs and iOS + Android devices.
Out of necessity, the Chrome team has created cross-platform abstractions for many low-level platform features. We use this source as the core API on which we build our business logic, and it's made the bulk of our app cross-platform with little effort.
Most importantly -- Chrome code has been battle-tested like almost nothing else, with an installed base in the hundreds of millions. That makes all the difference when you want to spend your days working on your company’s business logic instead of debugging platform issues.
Basically, you can structure your code like the diagram below, where you only write your application logic, and let Chromium do the heavy lifting.
So what's in Chrome that's so great?
Well, consider the parts of a modern browser. Chrome contains high-performance, cross-platform implementations of:
- Concurrency handling
- Compression
- Encryption
- Certificate handling
- Low-level socket interfaces
- High-level protocol implementations like HTTP, HTTPS, FTP)
- DNS resolution
- Proxy handling
- Complex disk caching
- Cookie handling
What it lets you do is build a single, cross-platform application layer, on top of all this goodness.
Chrome code also has other unexpected, higher-level goodies like:
- Chrome Remote Desktop,
- a full P2P (TURN, STUN, etc) stack (used by the Chrome Remote Desktop code),
- an XMPP client (used by Chrome Sync as well as Chrome Remote Desktop)
Where Do I Start?
First Things First: The right tools to generate your project
The first step in starting your project is to create the appropriate project file for your platform (Visual Studio, XCode etc). Chromium uses GYP to declaratively specify files and project settings in a platform independent manner. I strongly recommend starting your project as a GYP file. GYP generates project files for each platform (Visual Studio solution and project files, XCode project files and Android .mk files). In addition, powerful dependency options in GYP allow compiler and linker settings needed by the various Chromium project files to automatically flow into the projects that depend on them. This drastically reduces your own build headaches, as well as problems when you update your checkout of Chrome sources.
A basketful of helpers prevent your project from becoming a basket-case.
Once you get to the meat of your app, you will find yourself needing all sorts of helper libraries for everything ranging from string manipulation, concurrency handling, synchronization, thread pools, message loops, logging, file manipulation, timers, shared memory management, and more.
If you find yourself starting to write a generic helper class or library, search the Chromium sources first. Chances are very high that you will find just the class you want, with very good unit-test coverage to boot.
The base library in the Chromium sources (found in src/base) provides a vast array of cross-platform tools that cover all the areas mentioned above and a lot more. There are also helpers for platform-specific areas such as the Windows registry or the iOS keychain.
It has become quite the game for developers at MobileSpan to search the Chromium sources for helpers they need.
Network stack, anyone?
Unless you are building your app for Windows 3.1, chances are that you want to talk to a server of some kind. This might involve simple HTTP or HTTPS API calls or low-level socket calls or anything in between.
The net library in Chromium (src/net) is your friend here. You’ll find a full cross-platform HTTP and HTTPS stack, code for cookie handling, caching, TCP and UDP sockets and socket pools, SSL certificate handling, DNS resolution, proxy server resolution ..., well, you get the idea, pretty much anything network related.
Encryption
Need to handle public/private keys, encrypt data store secrets? The crypto library (src/crypto) is another excellent cross-platform library that is almost sure to have the encryption or key management routine you are looking for. By now, you get the picture of how the sources are organized.
XMPP, P2P, Protocol Buffers etc.
These aren’t things you would normally expect to find in a web browser but Chromium includes an extensive XMPP and P2P client library built on top of libjingle (look at src/jingle and src/remoting). If you use protocol buffers in your code, GYP has support for .proto files. Just add the .proto files to your GYP file and it will do the right thing of building the protoc compiler and generate wrapper code for your protobufs. This even works for iOS projects.
Testing
Your code is only as good the unit-tests you write for them, right? Though not strictly a part of the Chrome, the GTest and GMock libraries that are part of the Chrome checkout provide an excellent framework for writing unit-tests and mocking your C++ classes. All Chrome tests are written using these frameworks so you have a big sample codebase to get inspired by.
GYP even creates platform-appropriate containers for your tests. For example, on iOS, it will automatically create an iOS app to contain your tests so you can run them in the simulator. You just write your tests in cc files, add them to a gyp file, add the right dependencies and viola, you have cross-platform unit-tests.
At MobileSpan, we implemented the core of our business logic in a cross-platform library that is built using Chrome. We then built our UI per platform that uses this underlying library. Porting our app to a new platform means mainly building the UI layer on the new platform and then tying it together with the cross-platform client library.
Conclusion: Tying It Together
If I am sounding like a Chrome fan-boy, that’s because I am one. Since we embraced Chromium more than 2 years ago, we have found it to work really well for us as a dev platform, saving countless person-hours. It has allowed us to reuse some really well-written and, more importantly, well-tested code across several client platforms, and to concentrate our efforts on making a solid product that works equally well on multiple platforms.
Items for a future post
This just scratches the surface of using Chrome source as a development platform. What should I cover in a next post?
Some options include:
- Deep dive into specific libraries like Network, Crypto, etc.
- Keeping up to date with Chromium sources
- How to fork and keep your sanity (and knowing when to fork certain sources)
- Process of checking out Chromium sources
- More details on cross-platform UI development
Have you poked at Chrome's codebase or used it to build a cool product? Tell us about it in the comments section.
Sanjeev Radhakrishnan
Co-Founder and CTO, Sanjeev leads technology development and architecture at MobileSpan. He brings many years of experience from working on Google Chrome's security and sandboxing.
↧
Stop trying to innovate keyboards. You’re just making them worse | Ars Technica
Comments:"Stop trying to innovate keyboards. You’re just making them worse | Ars Technica"
URL:http://arstechnica.com/staff/2014/01/stop-trying-to-innovate-keyboards-youre-just-making-them-worse/
I've written about my struggles to find a good PC laptop before. After literally years of searching, it looks like Lenovo has stepped up to the plate and finally created the machine I crave. The new ThinkPad X1 Carbon, a high-resolution, Haswell-equipped update to 2012's Ivy Bridge-based model looked just about perfect.
This is almost everything I want from a laptop.The machine looks glorious in just about every regard. Fully decked out, it has a 2.1-3.3 GHz two core, four thread Core i7-4600U processor, 8GB RAM, a 14-inch 2560×1440 multitouch screen, 801.11ac, 9 hours of battery life, and a fingerprint reader. It all weighs in at under 3 lbs. It's a sleek, good-looking machine, and I'd buy one in an instant...
... if it weren't for one thing. The new X1 Carbon has what Lenovo is calling an "Adaptive Keyboard." Here's a picture of it:
I admit, I'm very picky about keyboards and their layouts, but golly gosh. Let us marvel together at its non-standardness. The gimmick of this keyboard is the row above the number keys, the place where the function keys should sit. The markings on this strip change according to the mode it's in. It can show a bunch of function key labels—F1 through F12—or media keys, or volume/brightness/etc. buttons, or whatever else is appropriate. I'm not entirely clear on all the ins and outs of its operation. Lenovo says that the options will vary according to the program you're running, but I'd have to use it to know just how well that works.
That these aren't hardware buttons is a bit awkward, though. I'm a touch typist, and as such, I use almost all of the keys on my keyboard without looking at them. This includes the function keys. But I can't really do that if the keys will change meaning of their own accord. Even if they didn't change meaning, the lack of discrete keys and tactile feedback would tend to impede touch usage.
If that's as far as it went, it probably wouldn't be too terrible. I mean, sure, I would prefer real keys, but I do get the point. On most laptop keyboard layouts, the function keys are heavily overloaded, and the non-function-key operations aren't particularly memorable. Using a bit of technology to make the labeling clearer is a fair idea.
Nothing where it should be
But it's the rest of the keyboard that really blows my mind. For example, the removal of the Caps Lock key and the insertion of Home and End keys in its place.
The Caps Lock key has its detractors, and it's true that it's led to far more pieces of online shouting than anyone would like. I do actually use it for legitimate things from time to time, though. Various programming languages have a policy of naming certain things with all capitals, and rather than bouncing from Shift key to Shift key to type out long all-caps words, I'll just use Caps Lock and type normally.
And let's be honest here. Caps Lock is a fantastic key. It's cruise control for cool. It's probably the best key on the keyboard.
The Adaptive Keyboard does seem to have Caps Lock—there's an indicator LED on the Shift key. So it's not that the keyboard lacks the feature entirely. It just changes the way it's invoked. And that's just awkward. It's the same with the placement of the Home and End keys. I'm sure they work there, but again, it's awkward.
The reason it's awkward is that in spite of being a touch typist, I don't really know where the keys are. In fact, there's research that suggests that because I'm a touch typist, I don't really know where the keys are. I don't consciously think about the physical position of the keys. My fingers just know where to move.
So for Caps Lock, I don't think "move my left little finger one key to the left." I just think "Caps Lock." And on the Adaptive Keyboard, that won't work. That same thought will result in me pressing End.
The Home and End keys themselves fall in a similar boat. I don't think of them on my left little finger. I just reflexively, intuitively press them with my right hand.
Unwelcome evolution
In fairness, these particular keys are often subject to poor positioning on laptop keyboards. There was a time that laptops would include the sextet of page navigation keys—Delete, Insert, Home, End, Page Up, and Page Down—in a three-by-two block, just as you'd find on a full-size keyboard. The keys might be a little smaller, and perhaps they'd be located above the main keys rather than off to the right, but they'd have the same positioning relative to one another, so they would be easy to get accustomed to.
Over the years, that block of six keys has been broken up and scattered hither and yon. The X1's previous keyboard design put four of the keys—Home, End, Insert, and Delete—in a row at the top right, with Page Up and Down positioned around the cursor keys (old Lenovo keyboards put Back/Forward Web buttons around the cursor keys, which I much prefer).
The Lenovo Helix's keyboard distorted the sextet further still. Page Up and Down remain down by the cursor keys, but the group of four is now a group of three: Home, End, and Delete. If you want Insert, you'll need to use Fn-Delete.
As such, the new X1 keyboard is just the latest evolution, if we can call it that, of that six-key block. Insert appears to be missing entirely (though it's possible that it's invoked with Fn-Delete, as on the Helix). Home and End are on the left, using the wrong hand. Page up and down stay by the cursor keys.
Other keys are arbitrarily moved around. Escape no longer sits in a row with the function keys; it's now to the left of 1. That's where Backtick/Tilde should live; they're now down on the bottom, between Alt and Ctrl. On the Helix, Print Screen is put in that same spot. Like insert, it appears to be missing entirely from the new X1 keyboard—though it's possible it's been relegated to the "adaptive" keys.
Another pair that deserve explicit mention: the Backspace and Delete keys. Because the block of six page navigation keys is gone, Delete has been squeezed in adjacent to Backspace. How many people are going to end up hitting Delete when they stretch their pinky to the top right corner to hit Backspace? I don't know for sure, but I'd guess it's going to be basically everybody.
Pretty much every key on the keyboard is there for a reason
Ultimately, the new X1 keyboard is a mess. I think these kind of keyboard games betray a fundamental misunderstanding of how people use keyboards. Companies might think that they're being innovative by replacing physical keys with soft keys, and they might think that they're making the keyboard somehow "easier to use" by removing keys from the keyboard. But they're not.
There are three points here. First, as already mentioned, skilled keyboardists don't know where the keys actually are. Moving the keys away from their innately assumed positions, therefore, produces a keyboard that's hard to use. Moving the keys forces the skilled typist to think about where keys are and how to use them, and that entirely defies the point of being a skilled typist. I appreciate that not everyone is a skilled typist, but come on. The X1 is a high-end, expensive machine. I daresay that, were it not for the keyboard, it would find favor with, for example, software developers and IT professionals, almost all of whom are fluent typists.
Second, some people do actually use the keys that get removed. The Break key is missing from many laptop keyboards these days, for example. I'm not going to pretend that the Break key is a key you use every single day, but it's not useless, either. For example, Windows' ping command, when used with the -t switch (endless pinging until stopped) lets you type Ctrl-Break to print the current stats without ending the pinging (as opposed to Ctrl-c, which prints stats and ends the pinging). This isn't the most important thing ever, but it's nonetheless useful to be able to do.
It's the same with other little-used keys. I use the PuTTY ssh client on Windows, and PuTTY uses Shift-Insert as its paste keystroke (it can't use Ctrl-v, because that gets passed through to the remote system). No Insert key means no pasting with the keyboard. I'm sure some people never use Print Screen to capture the screen. I use it all the time! Removing these keys from the keyboard simply makes the keyboard less useful.
No keyboard is an island
The final issue is that the keyboard is, in general, very hard to upgrade, because it's awfully entrenched. Anyone who's tried to learn, for example, the Dvorak layout will probably have discovered this. The benefits of the Dvorak layout aren't well proven (if they exist at all), but some people find the layout more comfortable to use. The trouble is that most people find, from time to time, that they have to use computers that aren't their own. This means that they have to switch between Dvorak and QWERTY, and this switching can be very jarring (especially during the learning phase).
This is a big problem for anyone trying to innovate. The X1's Adaptive Keyboard may have a superior layout to a regular keyboard (I don't think that it does, but for the sake of argument, let's pretend that it does), but that doesn't matter. As long as I have to use regular keyboard layouts too, the Adaptive Keyboard will be at a huge disadvantage. Every time I use another computer, I'll have to switch to the conventional layout. The standard layout has tremendous momentum behind it, and unless purveyors of new designs are able to engineer widespread industry support—as Microsoft did with the Windows keys, for example—then their innovations are doomed to being annoyances rather than improvements.
This is something that all PC manufacturers are essentially guilty of, too. Take a look at the 2012 Acer Aspire S7. It discards the function key row entirely (instead doubling up the number key row), and squishes Tilde in next to Caps Lock.
Enlarge / Even though there's abundant space, the S7 just discards a row of keys. Andrew CunninghamInnovation should be sympathetic, not disruptive
Keyboard innovation can be done—and done well—but it has to be innovation that is in service of the keyboard's purpose, not opposed to it. One very old example of this is IBM's famous butterfly keyboard, back when Big Blue owned the ThinkPad line. The butterfly keyboard of the ThinkPad 701c was a remarkable contraption that enabled the keyboard to be wider than the laptop itself, enabling IBM to preserve a more conventional keyboard layout. Rather than using innovation to break expectations, the butterfly keyboard used innovation to help preserve expectations.
When opened up, the ThinkPad 701c's butterfly keyboard spills over the edges of the machine to make it bigger and better.More recently, many laptops now ship with backlit keys. In addition to looking exciting, many find this feature invaluable when typing in otherwise gloomy conditions; it helps them find keys on the keyboard and makes it easier to familiarize oneself with, and orient oneself on, the keyboard. As with the butterfly keyboard, this is innovation that doesn't undermine expectations.
Good keyboards are standard keyboards. Keyboards that don't break my intuitive expectations. Keyboards that maximize the value of my touch typing expertise and let me switch effortlessly to other systems. This means having all the keys in their regular positions, and when keys must be moved for space constraints, at least keeping the relative positions of related keys correct.
Lenovo's engineers may be well-meaning in their attempts to improve the keyboard. But they've lost a sale as a result. The quest for the perfect laptop continues.
↧
Dropbox Raises About $250 Million at $10 Billion Valuation - WSJ.com
↧
↧
The Euler-Maclaurin formula, Bernoulli numbers, the zeta function, and real-variable analytic continuation | What's new
The Riemann zeta function


For 








Clearly, these formulae do not make sense if one stays within the traditional way to evaluate infinite series, and so it seems that one is forced to use the somewhat unintuitive analytic continuation interpretation of such sums to make these formulae rigorous. But as it stands, the formulae look “wrong” for several reasons. Most obviously, the summands on the left are all positive, but the right-hand sides can be zero or negative. A little more subtly, the identities do not appear to be consistent with each other. For instance, if one adds (4) to (5), one obtains whereas if one subtracts 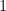
However, it is possible to interpret (4), (5), (6) by purely real-variable methods, without recourse to complex analysis methods such as analytic continuation, thus giving an “elementary” interpretation of these sums that only requires undergraduate calculus; we will later also explain how this interpretation deals with the apparent inconsistencies pointed out above.
To see this, let us first consider a convergent sum such as (2). The classical interpretation of this formula is the assertion that the partial sums
converge to 

where 
we have the sharper result
Thus we can view 

One can then try to inspect the partial sums of the expressions in (4), (5), (6), but the coefficients bear no obvious relationship to the right-hand sides:
For (7), the classical Faulhaber formula (or Bernoulli formula) gives
for 
The problem here is the discrete nature of the partial sum
which (if 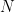

However, these issues can be resolved by replacing the abruptly truncated partial sums 


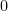
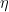

Note that smoothing does not affect the asymptotic value of sums that were already absolutely convergent, thanks to the dominated convergence theorem. For instance, we have
whenever 
However, smoothing can greatly improve the convergence properties of a divergent sum. The simplest example is Grandi’s series
The partial sums
oscillate between
and sets 

If 


and so we recover the value of
If we now revisit the divergent series (4), (5), (6), (7) with smooth summation in mind, we finally begin to see the origin of the right-hand sides. Indeed, for any fixed smooth cutoff function 

This interpretation clears up the apparent inconsistencies alluded to earlier. For instance, the sum 



Similarly, if we add together (12) and (11) we obtain while if we subtract 
— 1. Smoothed asymptotics —
We now prove (11), (12), (13), (14). We will prove the first few asymptotics by ad hoc methods, but then switch to the systematic method of the Euler-Maclaurin formula to establish the general case.
For sake of argument we shall assume that the smooth cutoff 


To establish (11), we shall exploit the trapezoidal rule. For any smooth function 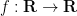

for any 

and
eliminating 
Summing in 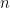
We apply this with 

But from (15) and a change of variables, the left-hand side is just 
The same argument does not quite work with (12); one would like to now set 
where 
and
We cannot simultaneously eliminate both 
one obtains
and thus on summing in 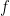
We apply this with 
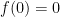


The proof of (13) is similar. With a fourth order Taylor expansion, the above arguments give
and
Here we have a minor miracle (equivalent to the vanishing of the third Bernoulli number 


and thus
With 


Now we do the general case (14). We define the Bernoulli numbers

The first few values of 
From (19) we see that for any polynomial 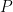

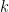

As (20) holds for all polynomials, it also holds for all formal power series (if we ignore convergence issues). If we then replace
we conclude the formal power series (in 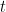
leading to the familiar generating function
for the Bernoulli numbers.
If we apply (20) with 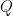
which we rearrange as the identity
which can be viewed as a precise version of the trapezoidal rule in the polynomial case. Note that if 

Now let
for 

for 
Translating this by an arbitrary integer 
Summing the telescoping series, and assuming that 




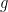


— 2. Connection with analytic continuation —
Now we connect the interpretation of divergent series as the constant term of smoothed partial sum asymptotics, with the more traditional interpretation via analytic continuation. For sake of concreteness we shall just discuss the situation with the Riemann zeta function series 
In the previous section, we have computed asymptotics for the partial sums
when 

Now suppose that 
with 
From (24) we have
which can be viewed as a definition of
For each fixed 


We still have to connect this definition with the traditional definition (1) of the zeta function on the other half of the complex plane. To do this, we observe that
for
for 





We have thus seen that asymptotics on smoothed partial sums of 
Let’s see how. Fix a complex number 

where
The function 
where
and so (26) can be rewritten as
The function 
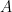
Now we have
integrating by parts (which is justified when
where
We can thus write (26) as a contour integral
Note that 




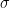





for any 
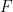


and thus we have
for any
The above argument reveals that the simple pole of 
has a meromorphic continuation to the entire complex plane, and does not grow too fast at infinity, then one (heuristically at least) has the asymptotic
where 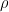
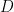

where 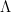

has a simple pole at 
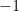
The link between poles of the zeta function (and its relatives) and asymptotics of (smoothed) partial sums of arithmetical functions can be used to compare elementary methods in analytic number theory with complex methods. Roughly speaking, elementary methods are based on leading term asymptotics of partial sums of arithmetical functions, and are mostly based on exploiting the simple pole of 

With this dictionary between elementary methods and complex methods, the Dirichlet hyperbola method in elementary analytic number theory corresponds to analysing the behaviour of poles and residues when multiplying together two Dirichlet series. For instance, by using the formula (11) and the hyperbola method, together with the asymptotic
which can be obtained from the trapezoidal rule and the definition of
where 
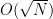
has a double pole at
and no other poles, which of course follows by multiplying (25) with itself.
Remark 3 In the literature, elementary methods in analytic number theorem often use sharply truncated sums rather than smoothed sums. However, as indicated earlier, the error terms tend to be slightly better when working with smoothed sums (although not much gain is obtained in this manner when dealing with sums of functions that are sensitive to the primes, such as , as the terms arising from the zeroes of the zeta function tend to dominate any saving in this regard).↧
SICP in Clojure
Comments:"SICP in Clojure"
This site exists to make it easier to use Clojure rather than Scheme while working through SICP. The folks behind SICP were kind enough to release it under a Creative Commons Attribution-Noncommercial 3.0 Unported License, which will allow me to annotate the text and adapt its source code and exercises to fit the Clojure language.
Structure and Interpretation of Computer Programs, or SICP, is widely considered one of the most influential texts in computer science education.  If you believe Peter Norvig, it will change your life. MIT Scheme, a minimalist dialect of Lisp, is used for all code examples and exercises.
If you believe Peter Norvig, it will change your life. MIT Scheme, a minimalist dialect of Lisp, is used for all code examples and exercises.
Clojure is a “modern” Lisp that runs on the Java Virtual Machine. Its speed, easy access to Java libraries, and focus on concurrency make it an appealing language for many applications.
This site exists to make it easier to use Clojure while working through SICP. The folks behind SICP were kind enough to release it under a Creative Commons Attribution-Noncommercial 3.0 Unported License, which will allow me to annotate the text and adapt its source code and exercises to fit the Clojure language.
All credit, of course, belongs to the authors: Harold Abelson and Gerald Jay Sussman, with Julie Sussman.
You should not be here yet.
Actually, you’re more than welcome to look around. I’ll avoid putting up any gifs of traffic cones and stop signs, but this site is very much under construction, and is nowhere near the point of being useful yet. It’s quite slow as well, since I have disabled all performance optimizations for development purposes. If you’re interested, take a look at the status page for a better idea of where things stand.
↧
Rondam Ramblings: No, the sum of all the positive integers is not -1/12
Comments:"Rondam Ramblings: No, the sum of all the positive integers is not -1/12"
URL:http://blog.rongarret.info/2014/01/no-sum-of-all-positive-integers-is-not.html
I haven't been blogging recently because my new startup is taking up all my time, but someone needs to stand up and say the emperor has no clothes so it might as well be me. About a week ago, two British mathematicians named Tony Padilla and Ed Copeland, who produce a video blog called Numberphile, posted a video that purports to prove that the sum of all the positive integers is -1/12. It was making the usual geek rounds where I would have been content to let it circulate, but today the story was picked up by a naive and credulous reporter at Slate, where the story stands to do some real damage if not challenged.
(Aside for mathematicians: yes, I am aware that the claim is true under Ramanujan summation. That is not the point.)
Let me start by recapping the argument. Finding the flaw in the reasoning makes a nice puzzle:
Step 1: Let S1 = 1 - 1 + 1 - 1 ...
Then S1 + S1 = (1 - 1 + 1 - 1 ...) + (1 - 1 + 1 - 1 ...)
= (1 - 1 + 1 - 1 ...) +
(0 + 1 - 1 + 1 - 1 ...)
= (1 + 0) + (1 - 1) + (1 - 1) ....
= 1 + 0 + 0 ... = 1
So 2xS1 = 1. So S1 must equal 1/2.
Step 2: Let S2 = 1 - 2 + 3 - 4 + 5 ...
So S2 + S2 = (1 - 2 + 3 - 4 + 5 ...) + (1 - 2 + 3 - 4 + 5 ...)
= (1 - 2 + 3 - 4 + 5 ...) +
(0 + 1 - 2 + 3 - 4 + 5 ...)
= (1 + 0) + (1 - 2) + (3 - 2) + (3 - 4) + (5 - 4) + ...
= 1 - 1 + 1 - 1 + 1...
= S1 = 1/2
So S2=1/4.
Step 3: Let S = 1 + 2 + 3 + 4 + 5 ...
So S - S2 = (1 + 2 + 3 + 4 + 5 ...) - (1 - 2 + 3 - 4 + 5 ...)
= (1 + 2 + 3 + 4 + 5 ...) -
(1 - 2 + 3 - 4 + 5 ...)
= (1 + 2 + 3 + 4 + 5 ...) +
(-1 + 2 - 3 + 4 - 5 ...)
= 0 + 4 + 0 + 8 + 0 + ...
= 4 x (1 + 2 + 3 + 4 + 5 ...)
= 4S
So S - S2 = 4S. But S2 = 1/4. So:
S - 1/4 = 4S
3S = -1/4
S = -1/12
Seems like an ironclad argument, doesn't it? Like I said, finding the flaw in the reasoning (and there most assuredly is one) makes an interesting puzzle. Here's a clue:
Let S3 = 1 + 1 + 1 + 1 ...
So S3 - S3 = (1 + 1 + 1 + 1 ...) - (1 + 1 + 1 + 1 ...)
= (1 + 1 + 1 + 1 ...) - (0 + 1 + 1 + 1 ...)
= (1 - 0) + (1 - 1) + (1 - 1) + ...
= 1 + 0 + 0 + 0 ...
= 1
But S3 - S3 must also equal 0, so we have just proven that 0=1.
The flaw in both cases is the same: the algebraic rules that apply to regular numbers do not apply to infinity. Actually, it's more general than that: the algebraic rules that apply to regular numbers do not apply to non-converging infinite sums. All of the sums above are non-converging infinite sums, so regular algebraic rules to not apply. It is no different from using regular algebra when dividing by zero. It doesn't work.
Now, there are ways to define the sums of non-converging infinite series so that they do not lead to contradictions. The one that leads legitimately to the conclusion that 1 + 2 + 3 + 4 ... = -1/12 is called Ramanujan summation, which in turn is based on something called an analytic continuation. But the problem is that the Numberphile video makes no mention of this. They present the result as if it is legitimately derivable using high school algebra, and it isn't. Telling people that it is does a grave disservice to the cause of numerical literacy.
↧
Obama’s Changes to Government Surveillance
↧
↧
Amazon Wants to Ship Your Package Before You Buy It - Digits - WSJ
Comments:"Amazon Wants to Ship Your Package Before You Buy It - Digits - WSJ"
URL:http://blogs.wsj.com/digits/2014/01/17/amazon-wants-to-ship-your-package-before-you-buy-it/
Amazon.com knows you so well it wants to ship your next package before you order it.
The Seattle retailer in December gained a patent for what it calls “anticipatory shipping,” a method to start delivering packages even before customers click “buy.”
The technique could cut delivery time and discourage consumers from visiting physical stores. In the patent document, Amazon says delays between ordering and receiving purchases “may dissuade customers from buying items from online merchants.”
So Amazon says it may box and ship products it expects customers in a specific area will want – based on previous orders and other factors — but haven’t yet ordered. According to the patent, the packages could wait at the shippers’ hubs or on trucks until an order arrives.
An image from patent, showing a possible logistics trail:
In deciding what to ship, Amazon said it may consider previous orders, product searches, wish lists, shopping-cart contents, returns and even how long an Internet user’s cursor hovers over an item.
Today, Amazon receives an order, then labels packages with addresses at its warehouses and loads them onto waiting UPS, USPS or other trucks, which may take them directly to customers’ homes or load them onto other trucks for final delivery.
It has been working to cut delivery times, expanding its warehouse network to begin overnight and same-day deliveries. Last year, Amazon said it is working on unmanned flying vehicles that could take small packages to homes directly from its warehouses.
In the patent, Amazon does not estimate how much the technique will reduce delivery times.
The patent exemplifies a growing trend among technology and consumer firms to anticipate consumers’ needs, even before consumers do. Today, there are refrigerators that can tell when it’s time to buy more milk, smart televisions that predict which shows to record and Google’s Now software, which aims to predict users’ daily scheduling needs.
It’s not clear if Amazon has deployed or will deploy the technique. A spokeswoman declined to comment.
But the patent demonstrates one way Amazon hopes to leverage its vast trove of customer data to edge out rivals.
“It appears Amazon is taking advantage of their copious data,” said Sucharita Mulpuru, a Forrester Research analyst. “Based on all the things they know about their customers they could predict demand based on a variety of factors.”
According to the patent, Amazon may fill out partial street addresses or zip codes to get items closer to where customers need them, and later complete the label in transit, the company said. For large apartment buildings, “a package without addressee information may be speculatively shipped to a physical address … having a number of tenants,” Amazon said in the patent.
Amazon said the predictive shipping method might work particularly well for a popular book or other items that customers want on the day they are released. As well, Amazon might suggest items already in transit to customers using its website to ensure they are delivered, according to the patent.
Of course, Amazon’s algorithms might sometimes err, prompting costly returns. To minimize those costs, Amazon said it might consider giving customers discounts, or convert the unwanted delivery into a gift. “Delivering the package to the given customer as a promotional gift may be used to build goodwill,” the patent said.
↧
Mutation in key gene allows Tibetans to thrive at high altitude | Science | theguardian.com
Comments:" Mutation in key gene allows Tibetans to thrive at high altitude | Science | theguardian.com "
URL:http://www.theguardian.com/science/2010/jul/02/mutation-gene-tibetans-altitude

Buddhist monks at a monastery in Xiahe. The gene mutation is an adaptation to low oxygen levels on the Tibetan plateau. Photograph: Mark Ralston/AFP/Getty Images
A gene that controls red blood cell production evolved quickly to enable Tibetans to tolerate high altitudes, a study suggests. The finding could lead researchers to new genes controlling oxygen metabolism in the body.
An international team of researchers compared the DNA of 50 Tibetans with that of 40 Han Chinese and found 34 mutations that have become more common in Tibetans in the 2,750 years since the populations split. More than half of these changes are related to oxygen metabolism.
The researchers looked at specific genes responsible for high-altitude adaptation in Tibetans. "By identifying genes with mutations that are very common in Tibetans, but very rare in lowland populations we can identify genes that have been under natural selection in the Tibetan population," said Professor Rasmus Nielsen of the University of California Berkeley, who took part in the study. "We found a list of 20 genes showing evidence for selection in Tibet - but one stood out: EPAS1."
The gene, which codes for a protein involved in responding to falling oxygen levels and is associated with improved athletic performance in endurance athletes, seems to be the key to Tibetan adaptation to life at high altitude. A mutation in the gene that is thought to affect red blood cell production was present in only 9% of the Han population, but was found in 87% of the Tibetan population.
"It is the fastest change in the frequency of a mutation described in humans," said Professor Nielsen.
There is 40% less oxygen in the air on the 4,000m high Tibetan plateau than at sea level. Under these conditions, people accustomed to living below 2,000m – including most Han Chinese – cannot get enough oxygen to their tissues, and experience altitude sickness. They get headaches, tire easily, and have lower birth rates and higher child mortality than high-altitude populations.
Tibetans have none of these problems, despite having lower oxygen saturation in their tissues and a lower red blood cell count than the Han Chinese.
Around the world, populations have adapted to life at high altitude in different ways. One adaptation involves making more red blood cells, which transport oxygen to the body's tissues. Indigenous people in the Peruvian Andes have higher red blood cell counts than their countrymen living at sea level, for example.
But Tibetans have evolved a different method. "Tibetans have the highest expression levels for EPAS1 in the world," said co-author Dr Jian Wang of the Beijing Genomics Institute in Schenzhen, China, a research facility that collected the data. "For Western people, after two to three weeks at altitude, the red blood cell count starts to increase. But Tibetans and Sherpas keep the same levels," he said.
"I just summitted Everest a few weeks ago," added Dr Wang. He said the Sherpas and Tibetans were much stronger than the Westerners or lowland Chinese on the climb. "Their tissue oxygen concentration is almost the same as Westerners and Chinese but they are strong," he said "and their red blood cell count is not that high compared to people in Peru."
"The remarkable thing about Tibetans is that they can function well in high altitudes without having to produce so much haemoglobin," said Prof Nielsen. "The entire mechanism is not well-understood – but is seems that the gene responsible is EPAS1."
Nielsen said the gene is involved in regulating aerobic and anaerobic metabolism in the body (cell respiration with and without oxygen). "It may be that the [mutated gene] helps balance anaerobic versus aerobic metabolism in a way that is more optimal for the low-oxygen environment of the Tibetan plateau," he said.
Writing in Science, where the results are published today, the authors say: "EPAS1 may therefore represent the strongest instance of natural selection documented in a human population, and variation at this gene appears to have had important consequences for human survival and/or reproduction in the Tibetan region."
Dr Wang said future research will focus on comparing the levels of EPAS1 expression in the placentas of Tibetan and Han Chinese women.
↧
How startups can compete with big company perks
Comments:"How startups can compete with big company perks"
URL:http://esft.com/how-startups-can-compete-with-big-company-perks/
Big companies like Facebook, Google and Twitter can afford to hire a professional chef to cook meals every day. They can also afford to do your laundry, drive you to and from work, and clean your apartment. These perks make their job offers incredibly appealing, and it makes their employees less likely to leave. But when you're a startup with <=$10M in the bank, there's simply no way you can afford to provide all these perks in-house.
In the past few years, there have been a surge of new startups built to help other startups (Selling pickaxes during a gold rush, as Chris Dixon puts it). Predominantly, these startups are focused on making it easier to develop & distribute your software. However, there is a new trend of startups that are helping solve the problem nearly every founder faces: attracting & retaining employees.
By taking advantage of digital dualism, these startups are able to keep their prices incredibly low while providing a great user experience, which is atypical in their respective markets. Below are some of the most prevalent startups, spanning from professionally cooked food to chauffeur services.
Do your employee's chores
Homejoy - home/apartment cleaning for $20/hr. Before their service existed, you could either scour craigslist for a reasonably priced cleaner (and hope that they're also trustworthy) or pay a premium for a verified business. This is no longer the case, as Homejoy uses simple software & verified user reviews to ensure a great experience.
SFWash - laundry pickup service for $1.25/pound. SFWash seems to be the most popular "pick up at your door" laundry service. They've been around since 2006, so they're a safe bet for consistency.
Swifto - dog walking service for ~$25/walk. While your employees are at work, they won't have to worry about how their dog is doing, as their dog will be out and about having the time of his life. Happy pets make for happy employees.
Feed your employees
People Food - professionally catered food for $7/meal. A lot of catering services don't make the food themselves and instead buy from restaurants. The problem is that this becomes very expensive, as both the restaurant and the catering service need to make a profit. People Food is able to keep their costs low by doing all of this in-house. You order the food off of their website; they have a professional chef who cooks the food, and they deliver it to your office via their fleet of bike messengers.
Fluc - food delivered on demand from almost any restaurant. Whether your employees are into fast food or local restaurants, Fluc can deliver it within 40 minutes. They also deliver drinks from coffee shops if you want to avoid going outside for your next coffee run.
ZeroCater - food catered from local restaurants. Being the original software assisted catering service, ZeroCater makes the process of scouting and ordering from restaurants unbelievably simple. ZeroCater's software even allows you to enter in food allergies, ensuring that all of your employees can eat delicious lunches. ZeroCater has been growing like crazy since they launched in 2011 and have recently started expanding nationally.
DoorDash - food delivered on demand from local restaurants. If you're in the mood for some delicious dishes from a local joint, DoorDash can deliver it within 40 minutes.
Instacart - groceries delivered to your door. Keep your company's fridge and snack cabinet stocked with delicious food & drinks for late night work sessions.
Keep employees happy
Goldbely - yummy handmade foods in America, delivered to your door. Want to surprise your employees on game night? Order a pizza from Lou Malnati's in Chicago and have it delivered in two days. Did your product ship in time? Buy your engineering team Jeni's delectable ice cream sandwiches. Surprise treats are a great gift to show how much you appreciate their work.
BloomThat - handcrafted flowers delivered in 90 minutes, starting at $35. Whether it's an anniversary, a new baby, or a company welcome gift, Bloomthat can send flowers directly to your employees on demand.
Yiftee - simple giftcarding service. Reward your employees for a job well done by sending them a virtual gift card to that coffee shop down the street. They also have an API that you can take advantage of (automatically send a gift card upon an employee's first git commit, etc).
Chauffeur your employees to and from work
Lyft - "your best friend with a car" for $3.25 a flag pull plus $1.80 per mile. Lyft has become crazy popular because of their low prices and their super friendly drivers. If your employees like chatting with new people, Lyft might be a good fit for your company.
UberX - chauffeur service for $3.00 a flag pull plus $1.50 per mile. If your employees aren't morning people, UberX might be a good option. Their drivers act like pros and aren't particularly chatty. Uber recently slashed the prices of UberX to undercut Lyft, so they're the cheapest chauffeur service available right now.
If you feed your employees lunch everyday (with People Food), clean their apartment every other week (with Homejoy), and do their laundry every other week (with SFWash), you would be paying $280/month/employee to keep them super happy as well as dramatically increase employee retention & attraction.
In the war for talent, a two person startup can now effectively compete with billion dollar companies. Game on.
(Disclamer: I know a few founders that run some of the companies listed above. This isn't a paid endorsement - if you have any startups I missed, I'd be more than happy to add them to the list.)
↧
When a great product hits the funding crunch
Comments:"When a great product hits the funding crunch"
URL:http://andrewchen.co/2013/11/05/when-a-great-product-hits-the-funding-crunch
Building a great product is not enough
Today I read a well-done article by The Verge on the shutdown of Everpix, a photo startup that’s gained a small but loyal following. It’s a great read, and I’d encourage you to check it out. There’s a lot of things to comment on, but the Everpix story is a common one these days- a lot of startups have built great initial products, and even shown some strong engagement, but ultimately not enough traction to gain a Series A.
The essay on Everpix drove home a lot of recent trends in startups that have gained momentum for the last year or two. Let’s examine a couple of these trends.
Funding goalposts continue to move
The first thing we’ll talk about is the company metrics. One of the best things about this article was that they did a good job of covering some of Everpix’s stats on engagement, conversion rate to premium, etc.
Everpix stats
- 55,000 total signups and 6,800 paid users
- Freemium biz model of $4.99/month or $49/year
- Free-to-paid conversion rate of 13%
- 4.5 star rating with 1,000+ reviews
- MAU/signups of 60%
- WAU/signups of 50%
- Raised $1.8M and then a seed extension of $500k
- Ex-Apple founders with 6 FTEs
You can see that other than the top-line metric of total signups, the other metrics are quite solid. If this company were started just a few years ago, I’m convinced they would have had no problem raising their Series A. These days though, it’s gotten a lot harder.
The reason for that is the “moving goalposts” on what you’re expected to do with your funding.
It’s been widely noted that investing milestones have evolved quickly over time:
- In 1998, you’d raise $5M Series A with an idea and not much else. The capital would be spent to build the product, and hopefully you’d have some customers at the end of it, but it wasn’t required. You had to do crazy stuff like put machines into a datacenter, at this point. Then you’d raise a Series B to scale the marketing. The qualitative bar for the team, idea, and market was high.
- In 2004, you’d raise $500k with just an idea. Then you’d build the product and spend $5M to market it. At this point, you could use a free Open Source stack which would accelerate development. You didn’t need to build a datacenter either.
- In 2013, these days, you are expected to have a product coded up and ready before you raise your first substantial angel round. Maybe the product won’t be launched, but people will want to play with a demo at least. Then you raise $1-2M to get traction on your product. Then if you have millions of signups, then you get to raise your Series A of $5-10M.
In fact, it’s been famously written by Chris Dixon, now a partner at Andreessen Horowitz, that 10 million users is the new 1 million users. I’ve previously written that Mobile Startups are Failing Like It’s 1999, due to the long launch cycles that the Apple Store encourages. I’ve also written about mobile getting harder and not easier over time.
There’s a couple things going on: The sheer proliferation of seed-funded startups, combined with investors who want to invest post-traction, post-product/market fit. Combine this with 1999-style launches for mobile apps, and you have a big mismatch in the supply and demand for funding. Series A venture capitalists are often acting like growth investors now, where they want the entire equation de-risked before they put in much capital, and it’s reasonable to expect this given the technology stack and massive distribution channels.
My question is, in 2016, will the bar be even higher? Maybe angel investors will expect a working product, reasonable traction, and product/market fit all before they put in the first $1M? How much can market-risk be proved out before any professional money is raised?
Monetization won’t save you if it’s not combined with growth
The Everpix story also shows that having a business model isn’t enough- after all, a 12% conversion rate to premium is stellar, which you can compare to Evernote’s 6%, as they mention. The problem is, if you have monetization in place, investors also want to see a lot of growth. Or you need enough growth and scale to be profitable without outside funding.
Work backwards on the latter to see what that looks like:
- 6 FTEs plus operations costs about $100k/month
- At $5/month, you need 20k paid subscribers to break even
- At a 12% free-to-paid rate, you need 160k signups
Turns out, 160k users is a lot, especially if you have a short runway. It’s well outside the boundary of a list of friends and family, or a Techcrunch article, or a big week of promotion from Apple . If you combine this with the rest of your schedule, like 6 months to raise VC, another 6-12 months to build the product, etc., then you don’t have much time to hit your traction milestones.
In contrast to the option to hit profitability, VCs don’t care that much about small scale monetization. They understand that a freemium service can get 1-5% conversion rates, and the question is if you have enough top-of-funnel signups to make the revenue numbers big. In fact, too much focus on monetization too early can lead a red flag, since it’ll mean maybe the entrepreneur is thinking small rather than focusing on winning the market.
A modern startup’s costs are all people costs
The final thing that’s worth pointing out in the article is the cost structure of the company and where the money went:
- $565k consulting and legal fees
- $128k office space
- $360k operating costs
- $1.4 total personnel costs
In other words, 80% of the costs went towards the employees and contractor/consultants/legal. It’s basically all people costs. You could argue that the office space is really just a function of the people too. Really, only ~15% of the capital went towards actually running the service.
If anything, this trend will only continue. San Francisco housing costs continue the rise, while computing infrastructure only gets cheaper and more flexible.
The nice thing about these costs, of course, is that you can always scale them down by scaling down your team. It’s complicated to do this, of course, since the value in this acquihires incent you to keep a large group of people going up until the end. But if you are convinced to work on the business for the long term, you can always scale things down to a few core folks, though it can be painful.
This is another reason why increasing your cost structure can be tricky if your product isn’t working in the market already. You end up in a case where just a year or two down the road, you have to make the tough decisions to keep going, or to shut the product down. So if you are working on something that you’re really passionate about – or as they say, amazing founder/market fit – then you may want to delay the team buildout so that you don’t end up creating that situation in the first place.
“Milestone awareness” and clear product roadmaps
Ultimately, this flavor of startup shutdown will continue to happen. Products that hit immense traction are the exception, not the norm, for a reason. Given that, what can you do? Ultimately, every founder needs a strong sense of “milestone awareness.” What I mean by that is the ability to understand what you need to accomplish before the next round of funding, and then to work backwards on that until you can put together a reasonable roadmap to get there. You might have to cut costs if the plan doesn’t seem to work. And you’ll have to revisit this plan on a regular basis to understand how it fits together.
The problem with hyper product-oriented entrepreneurs is that they often have one tool in their pocket: Making a great product. That’s both admirable, and dangerous. Once the initial product is working, the team has to quickly transition into marketing and user growth, which requires a different set of skills. It has to be more about metrics rather than product design: running experiments, optimizing signup flows, arbitraging LTVs and CACs, etc. It’s best when this is built on the firm foundation of user engagement that’s already been set up. In contrast, an entrepreneur that’s too product oriented will just continue polishing features or possibly introducing “big new ideas” that ultimately screw the product up. Or keep doing the same thing unaware of the milestone cliff in front of them. Scary.
Any startups that are at the “just add water stage” should email me and I’ll connect you with the resources and people to grow.
It’s funny that people take the lesson away from Apple that you should just focus on product. That’s only half the story, I think, because when you dig into why Apple is so secretive, it’s because the company is really focused on advertising and product launches. The secrecy that’s so deeply embedded in the organization facilitates their distribution strategy- can you imagine building your company culture around your marketing strategy? That’s what Apple’s done, though it’s not often talked about.
Good luck, guys
Finally, I want to wish the Everpix team good luck- they put together something that thousands of people enjoyed. That’s very hard, and more than most people can say. And they took away some very useful lessons that will only make them better entrepreneurs.
It’s never an easy thing to shut down something you’ve worked on for years, but I was insanely happy to see such a high-quality post mortem from The Verge. Thanks for writing this up, guys!
PS. Get new essays sent to your inbox
Get my weekly newsletter covering what's happening in Silicon Valley, focused on startups, marketing, and mobile.
↧
↧
Operating Systems: Three Easy Pieces
Comments:"Operating Systems: Three Easy Pieces"
URL:http://pages.cs.wisc.edu/~remzi/OSTEP/
Welcome to Operating Systems: Three Easy Pieces (now version 0.6 -- seeBOOK NEWS for details), a free online (and available for purchase in printed form) operating systems book! The book is centered around three conceptual pieces that are fundamental to operating systems: virtualization,concurrency, and persistence. In understanding the conceptual, you will also learn the practical, including how an operating system does things like schedule the CPU, manage memory, and store files persistently. Lots of fun stuff!
This book is and will always be free in PDF form, as seen below, on a chapter-by-chapter basis. For those of you wishing to BUY a copy, please consider the following:
- A wonderfulhardcover edition - this may be the best printed form of the book (it really looks pretty good), but it is also the most expensive way to obtain the black book of operating systems.
- An almost-as-wonderful (and somewhat cheaper)softcover edition - this way is pretty great too, if you like to read printed material but want to save a few bucks.
- A pretty awesomeelectronic edition (for only ten dollars!) - this is a nice convenience and adds things like a glossary of terms and a few other small things not seen below.
And now, the free online form of the book, in chapter-by-chapter form:
↧
Data Structures in Clojure – Macromancy
Comments:"Data Structures in Clojure – Macromancy"
URL:http://macromancy.com/2014/01/16/data-structures-clojure-singly-linked-list.html
About this Series
This series is about the implementation of common data structures. Throughout the series we will be implementing these data structures ourselves, exploring how they work. Our implementations will be done in Clojure. Consequently this tutorial is also about Lisp and Clojure. It is important to note that, unlike the standard collection of data structures found in Clojure, which are persistent, ours will be mutable.
To start with, we will explore a linked list implementation using deftype
(more on this later) to define a JVM class from Clojure-land. This
implementation will be expanded to include in-place reversal. Finally we will
utilize Clojure's built-in interfaces to give our linked list access to some of
the methods Clojure provides.
Basic Requirements
While this is a tutorial, some working-knowledge of Clojure is assumed. We will not cover setting up an environment for development or basic introductory Clojure subjects. If you are looking for an introduction to Clojure itself, consider Clojure From the Ground Up. However, no knowledge of Java or previous experience implementing these data structures is otherwise required.
Some background with recursion will be beneficial. Most of the methods we implement will rely on recursion because it is a concise and idiomatic choice for many of these algorithms. That said most of the examples should be fairly easy to follow even without a lot of experience with recursion.
Linked Lists
Linked lists are a simple and common data structure. While being simple, they can be surprisingly subtle. This makes them a good choice for an introductory series on data structures and in fact our initial implementation will be used again later when we explore hash tables (one potential use for linked lists). They are also important with regard to Lisp because S-expressions can be derived from linked lists. This is a topic we will explore more closely in a future series.
Basic Structure
Singly-linked lists are composed of links or nodes, where each node
contains some data or cargo and a next pointer. The next pointer points to the
next node in the list or some empty value, e.g. nil, indicating the end of
the list. A list of three nodes might look something like this:
In the above example the values "foo", "bar", and "baz" are all cargo. While
the arrows are pointers to the next node in the list. The last node does not
point to anything and instead holds nil as a terminating value. This will be
the basic structure of our singly-linked list implementation.
Performance Characteristics
Linked lists provide extremely efficient insertion and deletion at the head of the list. These operations are O(1). Additionally, inserts and deletes into the middle of the list can be performed in constant-time provided a reference is kept to the node proceeding the node to be operated on, otherwise this is an O(n) operation. Inserts and deletes at the end of the list can also be performed in constant-time if the last element is known by some reference.
Our implementation will not provide any but the first performance guarantee, in the interest of simplicity. However, this implementation could fairly trivially be extended to a doubly-linked list to provide the aforementioned benefits.
Applications
While linked list are an excellent choice for situations where an algorithm interacts frequently with the head node or dynamic list size is desired, arrays and dynamic arrays provide a different set of advantages and ultimately a linked list is a trade off.
For instance, linked lists can be used to implement a Last-In First-Out stack
in a fairly simple manner. Given the fact that appends to the head of the list
are cheap, the push operation is inexpensive. Similarly, the pop operation
is cheap--both of these methods are constant time.
That said, where random access is needed, a linked list may not be the best candidate. This is because we always have to traverse the list from the head unlike an array, where knowing the index ahead of time gives us efficient, near-constant lookups.
Variations
Linked lists come in various flavors. Generally when we say linked list, we mean a singly-linked list, which is what this article will focus on. It is worth mentioning there exists other variations which are beyond the scope of this tutorial.
Types in Clojure
defrecord and deftype
Before we get started, we should briefly discuss methods for defining custom types in Clojure, i.e. JVM classes. There are two:
and
For this tutorial we will be using deftype. Records, via defrecord, should
be preferred for application-level data modeling. Records provide map-like
objects with faster access to their fields and which can implement custom
interfaces and protocols. Whereas deftype is a superset of defrecord and
does not provide accessors, equality, and default interfaces. Because we are
interested in defining our own data structures, we will prefer deftype here.
Basic Implementation
Node Class
Now we will get started with our singly-linked list implementation. Recall that
our list will be made up of links or nodes. These nodes will have two fields,
a data field, which we will call car (you can think of this as short for
"cargo"), and a next pointer field, which we will call cdr. (If you are
curious about the nomenclature, this bit of Lisp history is relevant
here.)
It seems like a class called Node might be a good way to encapsulate this
structure. Let us go ahead and outline a Node type with deftype:
Notice that our binding vector contains two symbols, car and cdr. Under the
covers, these will become fields on the JVM class, of the same name. If we
were now to use our type from a REPL we would be able to see how these fields
work in practice:
=>(def node (Node."foo"nil))=>(.carnode)"foo"=>(.cdrnode)nilTo construct a new Node instance, we use the the name of the class
suffixed with a period. This is a shortcut for telling Clojure to give us
a new Node object. We could also use (new Node "foo" nil), to the same
effect.
With our newly constructed object, we can access its properties directly. As we
can see, (.car node) returns the expected value of "foo". Likewise(.cdr node) returns nil.
We now have a singly-linked list of one element in length. Our last element
terminates with a pointer to nil, indicating the end of the list. This is
looking good so far. But we probably will not be satisfied with lists of only
one node in practice, so we should think about how to encapsulate lists of
many nodes.
One way we can approach this, without writing any additional code, is to simply
nest invocations of the Node object. What if we do something like this:
=>(def linked-list(Node."foo"(Node."bar"(Node."baz"nil))))=>(.car(.cdrlinked-list))"bar"Cool! That worked. By nesting constructions of the nodes, we built a linked list with multiple elements. This is pretty neat, but there's actually a problem with our implementation as it sits: how do we update nodes?
When we use deftype to set up up our classes, they get compiled down to JVM
classes. During this process the fields are set up as final. This
effectively makes them immutable. In Clojure-land, this is a perfectly
sane default. But not all data structures lend themselves to these kinds of
restrictions. Not only that, but one motivating factor for defining custom
types is performance. Sometimes, for performance reasons, we want mutability.
Some algorithms are just faster or simpler when we can mutate data in place.
Because of this, we have two options for exposing our fields as mutable.
The metadata^:volatile-mutable and ^:unsynchronized-mutable, will
yield mutable fields. While the particulars of these two options will not be
covered here entirely, essentially ^:volatile-mutable will compile the field
with the volatile modifier. This means that set operations over these fields
are guaranteed to be visible to other threads immediately upon completion.
Whereas ^:unsynchronized-mutable specifies a field which does not make this
guarantee.
We will use the volatile option for the sake of simplicity.
(deftype Node[^:volatile-mutablecar^:volatile-mutablecdr])Okay great! We can now modify the values of the car and cdr fields on our objects. But there's actually another lurking problem here.
=>(def node (Node."foo"nil))(.carnode)IllegalArgumentExceptionNomatchingfieldfound:carfor class Nodeclojure.lang.Reflector.getInstanceField(Reflector.java:271)Uh-oh. What happened? Well, when we made our field volatile, we also made it private. It is no longer accessible from the outside world. These fields will have to be accessible from outside the class if our list is going to be useful. What we can do here is expose their values via getter methods. At the same time we will also define methods for setting these values from outside the class. Let us go ahead and write those now.
(definterface INode(getCar[])(getCdr[])(setCar[x])(setCdr[x]))(deftype Node[^:volatile-mutablecar^:volatile-mutablecdr]INode(getCar[this]car)(getCdr[this]cdr)(setCar[thisx](set!carx)this)(setCdr[thisx](set!cdrx)this))Let us take a minute to talk about what we have done here. First we added an
interface called INode. This defines an interface for our class. An interface
is a collection of functions that can be applied to a type which implements
that interface. Again we won't cover this in much depth here, however from
Clojure definterface provides this facility for us.
With our INode interface, we define our methods on the Node type. Note that
the this reference is implicit in the context of definterface, so it is not
a listed parameter of our interface methods. But because the reference is
needed from within our class, we explicitly define it.
Finally we setup our getters and setters. These are pretty straightforward.set! implicitly understand its context and therefore only needs a field
symbol and a value to bind it to. Here is what we have now:
=>(def node (Node."foo"nil))=>(.getCarnode)"foo"=>(.getCdr(.setCdrnode "bar"))"bar"At this point our Node is starting to shape up. Not only can we define a list
of nodes but we can alter them later on and get meaningful data back from them.
This is really all we need to build useful linked lists.
Now let us extend our interface a bit. Say we want to reverse the ordering of
our linked list so that (.getCar linked-list) actually returned "baz"?
Reversing a Singly-Linked List
It turns out there is an efficient, in time and space, way to do just that. Returning to the original description of a linked list, we recall that nodes have two values: a cargo and a next pointer. So to reverse the list, perhaps all we need to do is start with the head node and swap it with its neighbor? We could then continue on to the next node in the list until we ran out of nodes.
If we consider a simple list of two elements:
We can say that we would like a's cdr value to hold a pointer to b and for b's
cdr value to be nil. In essence, we want to switch the two nodes. This seems
pretty straightforward. Here this will work. But what if we have a slightly
longer list? Will the same approach work for a list of three elements?
This introduces a slight complication. If we were to have a list of three elements in length, what happens after we switch the head node with its neighbor? All would be fine until we went to select the next node, which would actually be the first node. We need to ensure that we do not step on ourselves as we traverse the list.
One approach here is to introduce an accumulator which ultimately will become the new head of the list. With this accumulator we can cons the current list's head on it. And then the cdr of the current head, followed by the cdr of the cdr of the head, and so on, until we reach a null cdr. At this point we would have a completely reversed set of node elements collected in our accumulator. All we would then do is return the accumulator.
Now we will implement this scheme in our reverse method:
(definterface INode(getCar[])(setCar[x])(getCdr[])(setCdr[n])(reverse []))(deftype Node[^:volatile-mutablecar^:volatile-mutable^INodecdr]INode(getCar[_]car)(setCar[_x](set!carx))(getCdr[_]cdr)(setCdr[_n](set!cdrn))(reverse [this](loop [curthisnew-headnil](if-not cur(or new-headthis)(recur(.getCdrcur)(Node.(.getCarcur)new-head))))))Let us pick apart of the reverse method by stepping through it. Our main goal here was to start with the head node and treat it as though it were the tail, persisting whatever value its cdr held, assuming it was non-nil, and then cons each successive node's car onto this new head. In this way we reverse the list. To do this we use Clojure's loop construct to recursively move through our nodes, passing over each one by one.
We start by defining cur and new-head in our loop. new-head is what we
will eventually return as the head node, it's our accumulator. On the first
iteration of the loop, it will point to nil. This is because our linked list
is null-terminated and this will serve as a sentinel for the tail node. We then
bind cur to the value of head.
We now check for cur to be nil. This is our base case, the condition under
which the recursive loop will terminate. If we have any nodes this check will
fail and we will drop down into our second branch of the conditional.
Here we do two important things. First we make good on our strategy of
consing the head node onto an accumulator, new-head. At this moment in time,new-head points to nil. Take careful note here, this is important because
our list terminates with that value and therefore this defines the final node
in our soon-to-be-reversed list. cur's cdr value now points to nil, whereas
before it pointed to the node that held "a". The second thing we do is set new
values for the second iteration of the loop: new-head becomes the value of(Node. (.getCar cur) new-head)) (i.e. a new node containing "b"), cur
becomes the value of (.getCdr cur) (i.e. the node containing "a"). We recur
with these values.
So where does this leave us? We are entering the second iteration of our loop.
Our loop values have changed and we once again check if cur is nil. In fact
it is not (it is the node containing "a"). That puts us in the second branch.
Once again we set the cdr of cur to new-head. Think about whatnew-head points to: the value of setting the cdr of the the head node to the
previous value of new-head, i.e. nil. In other words, it points to a
sublist of one element. That element was the first node of our original list.
We are going to set that value as the cdr of the cur node, which is the node
that holds "a". Again we recur.
This is the final iteration of our loop. This time cur's value is in factnil. Our linked list is reversed. Time to give it a try:
=>(def linked-list(Node."b"(Node."a"nil)))=>(.. linked-listgetCar)"b"=>(.. linked-listreverse getCar)"a"Great. It works! There is one caveat to this approach: we originally said that there was a solution that was efficient in both time and space. While that is true, our implementation is not efficient in terms of space. Because we copy the list instead of reassigning the node's pointers, we end up consuming more memory than necessary. To remedy this we could instead change the node's pointers in place.
(deftype Node[^:volatile-mutablecar^:volatile-mutable^INodecdr]INode(getCar[_]car)(setCar[_x](set!carx))(getCdr[_]cdr)(setCdr[thisn](set!cdrn)this)(reverse [this](loop [curthisnew-listnil](if-not cur(or new-listthis)(let [cur->cdr(.getCdrcur)](recurcur->cdr(.setCdrcurnew-list)))))))However this is slightly dangerous if our linked list is bound to var such aslinked-list. Since the original pointer bound to the var will become the tail
of the list and references to the rest of the list will not be accessible. For
simplicity we will not take that approach here.
Clojure Interfaces
Up until now we have used the methods we defined ourselves exclusively to
manipulate our custom type. While there is nothing inherently wrong with this
approach, it does mean we have been eschewing the use of Clojure's API. One
thing we might want to be able to do is call methods like first and next
over our linked list.
If we try this now we will get an error that informs us our object does not
participate in the ISeq interface. Indeed this is true and it is also
something we can fix. Let us implement a generalization of the seq interface
via clojure.lang.Seqable.
(definterface INode(getCar[])(setCar[x])(getCdr[])(setCdr[n])(reverse []))(deftype Node[^:volatile-mutablecar^:volatile-mutable^INodecdr]INode(getCar[_]car)(setCar[_x](set!carx))(getCdr[_]cdr)(setCdr[_n](set!cdrn))(reverse [this](loop [curthisnew-headnil](if-not cur(or new-headthis)(recur(.getCdrcur)(Node.(.getCarcur)new-head)))))clojure.lang.Seqable(seq [this](loop [curthisacc()](if-not curacc(recur(.getCdrcur)(concat acc(list (.getCarcur))))))))Here we have implemented clojure.lang.Seqable. Our goal in defining the seq
method is to return a sequence that represents our object. So in the case of
our linked list that would be a sequence of all of our nodes. Each node is
referenced by the current node forming a list. We use concat, in order to
preserve the correct ordering, build up an accumulator list. Ultimately we
return this accumulator. This is what we get when we call seq over a linked
list instance now. Let us give it a shot.
=>(def linked-list(Node."foo"(Node."bar"(Node."baz"nil))))=>(seq linked-list)("foo""bar""baz")=>(first linked-list)"foo"By implementing the seqable interface we have access to some of Clojure's
built-in methods. Notably our object can now be cast to a sequence which meansfirst, next, and rest will work. While this is certainly handy, there
is a caveat.
Sometimes clojure.lang.Seqable will not be enough to satisfy the ISeq
interface. In this case, we will have to implement clojure.lang.ISeq
explicitly. Furthermore, Clojure objects implement more than just the sequence
interface. So you may find some built-in methods will complain and throw
errors.
Completeness
In order for our object to be a "complete" Clojure datatype we would have to
implement a number of interfaces. This is largely outside the scope of this
tutorial and we will not attempt that here. But one additional interface we
might consider is clojure.lang.ITransientCollection and its associated
methods.
Also note that Clojure interfaces need not be implemented comprehensively. That
is to say that you can implement any number of methods they provide and not
necessarily all of them. That said, generally it is a good idea to implement
all of them or we may find we end up with strange errors such asAbstractMethodError, indicating a method that the interface provides was not
implemented.
Conclusion
This is the end of our exploration of a linked list implementation. While our
implementation is simple, it is correct and usable. By utilizing Clojure'sdeftype we have created a proper JVM class. This class could even be used
from other JVM languages, such as Java.
Additionally we explored the implementation of a fundamental linked list operation: reversal. Our solution is a recursive solution that builds up a new list but successively taking nodes from the head of a given list and appending those to the accumulator list.
Finally we took a look at how we can take advantage of some of Clojure's
built-in methods by implementing the clojure.lang.Seqable interface. While
this does not qualify as a comprehensive datatype from the perspective of
Clojure, it is nonetheless useful.
Our implementation could be used to implement a variety of more complex data
structures, some of which we will explore in the future. However one simple
exercise is to leverage what we have here to build a simple stack. Try to
implement the push and pop methods, where push takes a value and stores
it in a node appended to an underlying linked list and pop takes the first
node of that same list, returning its value.
=>(def s(stack))=>(.pushs"foo")=>(.pushs"bar")=>(.pops)"bar"=>(.pops)"foo"=>(.pops)nilFuture Posts
Now that we have a linked list, we will use this linked list to build a hash table. The next post will introduce hash tables and cover an implementation that uses separate chaining and dynamic resizing. Stay tuned!
↧
Carms Perez - Google+ - 5 months ago exactly I asked you all what you guys thought…
Comments:"Carms Perez - Google+ - 5 months ago exactly I asked you all what you guys thought…"
URL:https://plus.google.com/u/0/+CarmsPerez/posts/cDK6ZNpZ6YH
5 months ago exactly I asked you all what you guys thought of the Jobs movie that had just been released in theatres and I had the honor of Mr. +Steve Wozniak coming on to the post (original comment here https://plus.google.com/+CarmsPerez/posts/GnVTvQNgvpf)
and commenting and explaining what really went on at the time vs what the movie portrayed. I chose to not watch the movie then, however, tonight I rented it simply out of curiosity it was so good to see it knowing his perspective and the account of how things actually happened. I want to thank Mr. Wozniak from the bottom of my heart for every bit of time spent working on creating Apple computers. YOU are the true force behind this operating system which I love so much bc it makes my life so easy. Thank you for dedicating so much of your youth to this project. Honored once more to have such unique commentary from you on my page.
Original comment from Steve Wozniak below
and commenting and explaining what really went on at the time vs what the movie portrayed. I chose to not watch the movie then, however, tonight I rented it simply out of curiosity it was so good to see it knowing his perspective and the account of how things actually happened. I want to thank Mr. Wozniak from the bottom of my heart for every bit of time spent working on creating Apple computers. YOU are the true force behind this operating system which I love so much bc it makes my life so easy. Thank you for dedicating so much of your youth to this project. Honored once more to have such unique commentary from you on my page.
Original comment from Steve Wozniak below
Steve Wozniak Aug 19, 2013
"Actually, the movie was largely a lie about me. I was an engineer at HP designing the iPhone 5 of the time, their scientific calculators. I had many friends and a good reputation there. I designed things for people all over the country, for fun, all the time too, including the first hotel movie systems and SMPTE time code readers for the commercial video world. Also home pinball games. Among these things, the Apple I was the FIFTH time that something I had created (not built from someone else's schematic) was turned into money by Jobs. My Pong game got him his job at Atari but he never was an engineer or programmer. I was a regular member at the Homebrew Computer Club from day one and Jobs didn't know it existed. He was up in Oregon then. I'd take my designs to the meetings and demonstrate them and I had a big following. I wasn't some guy nobody talked to, although I was shy in social settings. i gave that computer design away for free to help people who were espousing the thoughts about computers changing life in so many regards (communication, education, productivity, etc.). I was inspired by Stanford intellectuals like Jim Warren talking this way at the club. Lee Felsenstein wanted computers to help in things like the antiwar marches he'd orchestrated in Oakland and I was inspired by the fact that these machines could help stop wars. Others in the club had working models of this computer before Jobs knew it existed. He came down one week and I took him to show him the club, not the reverse. He saw it as a businessman. It as I who told Jobs the good things these machines could do for humanity, not the reverse. I begged Steve that we donate the first Apple I to a woman who took computers into elementary schools but he made my buy it and donate it myself.
When I first met Jobs, I had EVERY Dylan album. I was a hardcore fan. I had bootlegs too. Jobs knew a few popular Dylan songs and related to the phrase "when you ain't got nothin' you got nothing to lose." I showed Jobs all my liner notes and lyrics and took him to record stores near San Jose State and Berkeley to buy Dylan bootlegs. I showed him brochures full of Dylan quotes and articles and photos. I brought Jobs into this Dylan world in a big way. I would go to the right post office at midnight, in Oakland, to buy tickets to a Dylan concert and would take Jobs with me. Jobs asked early on in our friendship whether Dylan or the Beatles were better. I had no Beatles album. We both concurred that Dylan was more important because he said important things and thoughtful things. So a Beatles fan was kind of a pop lamb to us. Why would they portray us in the movie as Dylan for Jobs and Beatles for me?
And when Jobs (in the movie, but really a board does this) denied stock to the early garage team (some not even shown) I'm surprised that they chose not to show me giving about $10M of my own stock to them because it was the right thing. And $10M was a lot in that time.
Also, note that the movie showed a time frame in which every computer Jobs developed was a failure. And they had millions of dollars behind them. My Apple ][ was developed on nothing and productized on very little. Yet it was the only revenue and profit source of the company for the first 10 years, well past the point that Jobs had left. The movie made it seem that board members didn't acknowledge Jobs' great work on Macintosh but when sales fall to a few hundred a month and the stock dives to 50% in a short time, someone has to save the company. The proper course was to work every angle possible, engineering and marketing, to make the Macintosh marketable while the Apple ][ still supported us for years. This work was done by Sculley and others and it involved opening the Macintosh up too.
The movie shows Steve's driving of the Macintosh team but not the stuff that most of the team said they'd never again work for him. It doesn't show his disdain and attempts to kill the Apple ][, our revenue source, so that the Macintosh wouldn't have to compete with it. The movie audience would want to see a complete picture and they can often tell when they are being shortchanged.
And ease of computer came to the world more than anything from Jef Raskin, in many ways and long before Jef told us to look into Xerox. Jef was badly portrayed.
And if you think that our investor and equal stock holder and mentor Mike Markkula was Jobs' stooge (and not in control of everything), well, you have been duped.
Jobs mannerisms and phrases are motivational and you need a driver to move things along. But it's also important to have the skills to execute and create products that will be popular enough to sell for more than it costs to make them. Jobs didn't have that success at Apple until the iPod, although OS X deserves the credit too. These sorts of things people would have wanted to see, about Jobs or about Apple, but the movie gives other images of what was behind it all and none add up." #Apple
↧
Lisp: more is less
Comments:"Lisp: more is less"
URL:http://jameso.be/2014/01/19/lisp.html
There’s recently been a resurgence of interest in Lisp (specifically, Clojure) in my neighborhood. I have some kind of a fondness for Lisp, but I think some of its characteristics make it poorly suited for use in large programming efforts. Indeed many of the unique properties that Lisp devotees (myself once included) tout over other languages, like homoiconicity, make Lisp into an unweidly, conceptual sledgehammer that’s often out of scale with the problem being solved.
I liked Lisp
At some point in college, I began following a charismatic AI professor around who was very knowledgeable and enthusiastic about Lisp. He described it in a way that made it seems like some sort of remarkably powerful, higher form of expression. So I dove in and started doing many of my projets in Common Lisp.
I eagerly read through ANSI Common Lisp, Practical Common Lisp, and SICP; all great reads. I watched talks that sold me on Rich Hickey’s vision of how Clojure tackles modeling reality with concurrency primitives. I wrote a basic robot driver and a shitty blog framework in Clojure. I strove to grok code-as-data-data-as-code, metacircular evaluators, hygenic macros; the whole enchilada.
And frankly, I got a lot of mileage out of that pursuit. SICP in particular taught me a ton about good abstraction, programming structure, and (unexpectedly) numerical analysis. Rich Hickey’s talks are fascinating works of thought, and they’re engaging as hell. There is no shortage of entertaining philosophical content in the Lisp community.
But that doesn’t make Lisp an appropriate tool for large software projects.
Remember “less is more?”
Lisps, for those unacquainted, have the unique property of homoiconicity. This means, among other things, that Lisps offer the ability to write very powerful macros which put users on roughly even footing with language implementors. In fact, most builtin functionality in Lisps are implemented as macros.
At first blush this may sound enticing, but it’s actually a property that gets progressively uglier as the number of active programmers goes up.
Most programmers are not (nor should be) language designers
A smart programmer is not necessarily an empathetic language designer; they are occupations that require different skillsets. Giving any programmer on your team the ability to arbitrarily extend the compiler can lead to a bevy of strange syntax and hard-to-debug idiosyncrasies. Introducing macros increases the conceptual surface area of a language by an unbounded amount, and it defeats compactness, which I’ve seen is an important characteristic that aids programmers in quickly and effectively understanding a code base.
Let me be clear: I think Lisp is more powerful language than, say, Python or Java. That’s what I’m arguing is its downfall. Using the simplest tool that provides enough convenience to get a job done enjoyably (which Python often does for me very nicely) has all kinds of peripheral benefits. Ones that Lisp’s power may exclude itself from, like…
Goodbye, static analysis
One of the most helpful programming tools I’ve discovered in the past few years has been in-editor static analysis tools, e.g. syntastic. Especially when developing in an interpreted language like Python, having syntactic analysis tools on hand to catch bugs before they happen and patrol code-quality in CI builds is a massive boon.
With macros, or any form of extraordinary dynamic language abilities, many of these benefits get thrown out the window. How can a static analysis tool keep up with a language that’s being arbitrarily extended at runtime? The prospect is daunting.
Unix wisdom
Benefits like static analysis and compactness are consequences of using the simplest thing that works with a reasonable amount of convenience. Obviously “a reasonable amount” is tough to pin down and I won’t attempt to do it here, but suffice to say that the only convenience I see on the margin between a Lisp and, say, Python, is a little bit of added syntactic sugar.
Projects like Korma sure look cool, and I’m sure are a ball to write, but is there really such an advantage over something like sqlalchemy in terms of readability? An advantage great enough to abandon automated sanity checks and to introduce obscure macro-based stacktraces? I don’t think so.
Perhaps it’s possible to write a linter that is informed by macro definitions within the codebase, but that’s certainly a more challenging task than just having to internalize a published language spec.
Conceptual clutter
Popular Lisps these days seem to be, optimistically, more conceptually diverse or, pessimistically, more conceptually undecided than other languages in popular usage.
Unix is in part such an effective environment because its concepts are easy and consistent. To see everything as a file, to work in terms of text streaming through pipes; these are straightforward ideas that govern the entire system. OOP is widely-used and easily comprehended because it is a fairly simple way of modeling reality that is compatible with how human beings do it.
By comparison, Common Lisp and Clojure (which rejects OOP but does, to its credit, impose some generally useful frameworks, e.g. the seq interface) seem to fall prey to the same affliction that I see in Haskell, Ruby, and Scala: they give you varied and often overlapping options for how to model a certain process or piece of state.
In Clojure, if I want to define a symbol there are nine different ways of doing so. In Python, there are three (=, def, class). By the way, those nine creational procedures only apply to Vars; there are also Refs, Agents, and Atoms with their own assortment of creation semantics; all of which are different primitive ways to reference pieces of data in Clojure.
Clojure claims to include these language features as a way to mitigate the complexity of parallelism; frankly, I’ve never found threading or interprocess communication to be any sort of conceptual bottleneck while working on some fairly complex distributed systems in Python.
Simplicity buys a lot
I attribute a lot of Python’s success to its devotion to simplicity; Python wants the conceptual machinery for accomplishing a certain thing within the language to be obvious and singular. This makes it easy for experienced Python users to quickly grok foreign code, and it makes it easy for newbies to master the language quickly.
The relatively few conceptual mechanisms in Python may not cover every single problem domain as well as picking the perfect one out in Clojure case-by-case, but they work well enough for most things to be make Python a powerful general-purpose programming language that is very effective at quickly communicating systems to programmers. This property is paramount in large engineering efforts.
Not all Lisps
This sort of excessive complexity isn’t inherent in Lisps (certain types of Scheme are wonderfully simple languages) but it does seem common to popular variants.
On the margin
On the margin, Lisp’s additional power over other common languages like Python and Java doesn’t buy much practical benefit. It does, however, impose significant costs in terms of programmer comprehension, code complexity, and automated tooling like static analysis.
I believe in Lisp and its communities as worthwhile resources and valuable for personal intellectual growth, but as, an engineer, I think it’d be irresponsible to choose Lisp for a large-scale project given the risks it introduces.
Less is more (as long as “less” is sufficiently convenient).
↧
↧
What Happens When the Poor Receive a Stipend?
↧
Ingredients of an All-Natural Banana | James' reading list
Comments:"Ingredients of an All-Natural Banana | James' reading list"
URL:http://jameskennedymonash.wordpress.com/2013/12/12/ingredients-of-an-all-natural-banana/
This visualisation has a short story behind it.

Click to download JPEG version
I usually care too much about food labels. If something has monosodium glutamate (E621) or high fructose corn syrup (HFCS) in it, I’m probably not going to buy it no matter how healthy or delicious the food looks as a whole. (Strangely, I’d be willing to eat it, though.)
Some people care about different ingredients such as “E-numbers”. I made this graphic to demonstrate how “natural” products (such as a banana) contain scary-looking ingredients as well. All the ingredients on this list are 100% natural in a non-GM banana. None of them are pesticides, fertilisers, insecticides or other contaminants.
There’s a tendency for advertisers to use the words “pure” and “simple” to describe “natural” products when they couldn’t be more wrong. With this diagram, I want to demonstrate that “natural” products are usually more complicated than anything we can create in the lab. For brevity’s sake, I omitted the thousands of minority ingredients found in a banana, including DNA ![]()
Enjoy!
↧
OH NO LINODE GOT HACKED AGAIN (LOL GET RAPED) - Industry News - vpsBoard
Comments:"Linode hacked again?"
URL:https://vpsboard.com/topic/3282-oh-no-linode-got-hacked-again-lol-get-raped/
Today some whitehat on IRC decided to paste this on irc:
13:13 < n0tryan> mysqldump -hnewnova.theshore.net --all-databases -ulinode -pcfr41qa --lock-tables=false -f 13:13 < n0tryan> GUYS 13:13 < n0tryan> PLEASE DO NOT HACK LINODE
And that appears to be the credentials to linodes database server that for example hosts their forums. All user logins leaked again, well played linode.
↧