↧
cython/CHANGES.rst at master · cython/cython · GitHub
↧
The Synference Blog: Why Wikipedia's highly successful A/B testing is conceptually wrong (and how contextual bandits can fix it)
URL:http://synference.blogspot.com/2014/01/why-wikipedias-highly-successful-ab.html
Summary: Every year, the Wikimedia fundraising team goes on a quest to find the perfect fundraising banner. The team has a long and successful history of using A/B tests to increase the effectiveness of their fundraising banners. A/B tests, however, are the wrong tool for the job: they find the best banner to serve, if you have to serve the same banner to everyone. They ignore the possibility of serving different banners to users with different preferences. We argue that the contextual bandit algorithms are a better fit for Wikipedia's fundraisers, because they customize banner selection based on user attributes.
Success story
Wikimedia recently wrapped up another fundraising campaign worth tens of millions of dollars. The campaign targeted English-speaking readers from the US, UK, Canada, Australia, and New Zealand. If you use Wikipedia, you might have taken part in one of Wikimedia's A/B tests, which they run to determine which banners most effectively convince visitors to donate.
By running a series of A/B tests, the Wikimedia team incrementally changed last year's banner (on top) until it looked like the banner on the bottom. While the addition of the payment form inside the banner is the most dramatic change, there are a few more subtle changes that also measurably improved the banner, such as the gold highlighting of text. These changes significantly increased banner effectiveness: the bottom banner earned 50% more revenue per impression than the top one.
A/B testing's hidden assumption: all users are the same
Wikipedia's use of A/B testing is interesting because much of it is organized by volunteers and so many of the results are public. You can look at the noticeboard for the 2013 campaign here, and the 2010 campaign here (the 2010 campaign was particularly well documented), or check out the general lessons learned here.
If you read these pages, the discussion focuses on which banner variant is better. The basic questions are phased in the following form: Is it better to highlight text using a flashy cyan background or a toned-down gold background? Is it better to begin with Dear Readers or should that be left out? The discussion takes this form, because that's how A/B testing works: you randomly split users between variants, and observe which variant performs best.
However, this one-size-fits-all approach is wrong, and the flaw is probably easier to spot for people who haven't been working with A/B tests for a long time: some people will prefer their call-to-action text highlighted with cyan, whereas others will prefer a gold background. (If this isn't obvious, consider a previous campaign, where one of the banners said "We need those nickels" - much of the world might not know what a nickel is, even though the phrase resonates with Americans.) In other words, not everyone is the same, so "which variant is generally better?" isn't really the right question. It makes more sense to ask "given a particular type of user, which variant is better?"
A/B testing sets out to settle on a final design that you can serve to everyone. In some situations, such as where you want to design a consistent user interface (with a single set of documentation) this makes sense, and so A/B testing is the right tool for the job. However, Wikipedia's pages are dynamically generated, and users will not notice or care if they are presented with different banners - so there's no need to settle on a final single design that you serve to everyone.
What about multivariate A/B tests?
Expert users of A/B tests might say that if you're worried about different types of users, you can just segment them using multivariate A/B tests. In the multivariate setting, you can choose to split users into different bins based on some attribute, such as age. You then have to choose age ranges that defines which bin each person gets put into, for example, 20-30, 30-40, 40-50. Then you run a separate A/B test on the users in each of those bins.
Anyone experienced with multi-variate A/B tests will know that this is a painful process. First off, you might have several attributes on which you could split your users: web browser, account age, gender, article category, etc. Which one should you split on? If you split on an attribute like age, what ranges should define the bins? It's usually not clear, and you just have to go on your gut feeling in making such decisions. If you think multiple user attributes are relevant (which is usually true), then it's possible to split on multiple dimensions, but in that case number of bins goes up exponentially. For example, consider the case where you have five attributes that each have five bins. The number of bins needed for splitting on all five attributes simultaneously is \(5^5=3125\). Very few websites generate enough data quickly run A/B tests when they're spread so thin.
In the last decade, the machine learning community has come up with algorithms that automatically discover how to segment your data, with much less data than multivariate A/B testing needs. You don't have to use your gut feeling to choose which attributes you feel are the most important, and how to split on them---the algorithm discovers this based on your data. It's time A/B testing took advantage of these tools.
Contextual Bandit Algorithms: the right tool for the job
We've established that A/B testing ignores user attributes, which is a missed opportunity, and that multivariate A/B tests don't offer a great alternative. But how could Wikipedia take advantage of their user data to show each user the perfect banner? As we just mentioned, supervised machine learning models are the standard approach to making predictions informed by user attributes, but for reasons I'll point out below, they're not quite the right tool to replace A/B testing.
Contextual bandit algorithms are the right tool for this job, but they're relatively new and most people running A/B tests have never heard about them (even Wikipedia doesn't have an article on them yet). So let's go over how contextual bandits work. Because many people are familiar with the basics of ML models (and not so many people are familiar with the multi-armed bandit literature), I'll stick to machine learning terminology in my explanation. And don't worry if you're rusty on ML, you should still be able to follow along.
Let's briefly review the supervised machine learning setting using the example of predicting how much money a user will donate to Wikipedia. In this setting, each user is described by a feature vector \(x\) and and a label \(y\), where \(x\) contains the user's attribute data, and \(y\) indicates how much the user spent. We first collect \(N\) historical data points, which we can represent as $$\{(x_1, y_1), ..., (x_N,\; y_N)\}.$$ Then we feed these data points to a machine learning algorithm, which finds a function \(g\) that maps the feature vectors to labels, i.e. $$g: X \to Y.$$ In practice your historical data and the overall workflow would look something like the following block of code:
# First gather a historical dataset. Each row is a (feature_vector, label) pair.
data = [
({'n_visits': 1, 'loc': 'usa'}, {'donation': 0 }),
({'n_visits': 33, 'loc': 'usa'}, {'donation': 5 }),
({'n_visits': 2, 'loc': 'uk' }, {'donation': 10})
]
# Get prediction function g based on historical data
g = ml_model.train(data)
#We can now use g to make predictions on on unlabeled data
new user = {'n_visits': 23, 'loc': 'uk'}
predicted_donation = g(new_user)The code above fits for the situation where you have a user described by \(x\) and you want to predict how much they will donate, but that's not quite what Wikipedia needs. Wikipedia has a set of possible banners, and they want to know - given a particular \(x\) - which banner will maximize future donations. Furthermore, each user can be shown only one banner, and we will never know what would have happened if we had shown the user a different banner. Thus, the labels contain unknown elements, as in the following block of code:
# Because each user is only shown one banner, Wikipedia's labels have unknown elements.
data = [
({'n_visits': 1, 'loc': 'usa'}, {'banner1': 'unknown', 'banner2': 0}),
({'n_visits': 33, 'loc': 'usa'}, {'banner1': 5, 'banner2': 'unknown' }),
({'n_visits': 2, 'loc': 'uk' }, {'banner1': 'unknown', 'banner2': 10})
]Trading-off Exploration vs. Exploitation
This is a more difficult machine learning problem because it involves an exploration/exploitation trade-off. Let's call a training phase, in which we split users randomly between banners, exploration. Likewise, let's call a subsequent phase, in which we use our trained model to send users to the banner with the highest expected value, exploitation. The more we explore, the more accurate our ML model becomes. Thus, the exploration phase can be seen as an investment: the longer it is, the higher the payoffs will be in the exploitation phase, because the estimates per banner and per user will be more accurate. But it's also possible to over-invest by exploring too much (and not exploiting your model), and it's managing this trade-off that makes the problem hard.
To better understand the trade-off, let's consider the extremes of too much exploration and too much exploitation. Imagine that we explore very little by limiting our exploration to just 100 users; in this case our predictions in the exploitation phase will be completely unreliable. With so little data, it's likely to be the case that nobody donated at all, or it could even be the case that due to a fluke, only the worst banner got a donation! On the other hand, to be more confident in our estimates, we might randomly split the first million users among the banners. That investment might be too expensive though, because during that exploration phase we're just randomly matching users up with banners - even for users we for which are model knows with high confidence which banner is best - and we will therefore miss out on higher revenues. (Advanced AB-testers will recognise this problem, as it also happens in AB-testing.)
Where Contextual Bandit Algorithms fit in
This is where the contextual bandit problem comes in: it formalizes this trade-off between exploration and exploitation. A contextual bandit algorithm decides when exploration or exploitation is necessary. In the background, it uses a statistical model similar to those used in machine learning, but the workflow is better suited for web optimization tasks (and many real-world tasks in general). Whereas with ML you have to collect a training dataset for some arbitrary amount of time, contextual bandits can start with zero data points, making them easier to deploy in practice (initially they'll just explore and make random choices, but they'll soon smoothly transition to exploiting their predictive models of what each user wants). This is much more data efficient than traditional AB-testing methods, as it integrates the power of machine learning with a cost-aware bandit approach.
Where to get contextual bandits
We've gone over why A/B testing isn't really the right solution to problems where we want to cater to users who have different preferences. We've also shown why the traditional machine learning paradigm isn't a great fit for this problem either. Contextual bandits, which combine the statistical models used by machine learning with the clever explore/exploit schedule of bandit algorithms, are a perfect fit (for more details on bandit algorithms, see this blog post).
In the last five years, this previously obscure academic problem has received a lot of attention from companies like Yahoo!, Google, LinkedIn, and Microsoft. But unfortunately these solutions aren't widely available. So we've created an API that allows any developer to use contextual bandit algorithms. If you're interested in an accessible introduction to contextual bandit algorithms, check our this blog post. One of our tutorials even goes over how you would use the API to serve banners, and is based on the case of Wikipedia.
↧
↧
oakes/play-clj · GitHub
Comments:"oakes/play-clj · GitHub"
URL:https://github.com/oakes/play-clj
Introduction
A Clojure library that provides a wrapper for LibGDX, allowing you to write games that run on desktop OSes (Windows, OS X, and Linux) and mobile OSes (Android and iOS) with the same Clojure codebase. It is a work in progress, and currently only covers the parts of LibGDX relevant to 2D games, but the goal is to eventually have full coverage.
Getting Started
You can easily get started with play-clj by creating a new project with Nightcode and choosing the Clojure game option. You may also create a project on the command line with Leiningen:
lein new play-clj hello-worldEither way, you'll get three separate projects for desktop, Android, and iOS, all pointing to the same directories for source code and resources. You can build the projects using Nightcode or Leiningen.
Justification
The best thing about making a game in Clojure is that you can modify it in a REPL while it's running. By simply reloading a namespace, your code will be injected into the game, uninhibited by the restrictions posed by tools like HotSwap. Additionally, a REPL lets you read and modify the state of your game at runtime, so you can quickly experiment and diagnose problems.
Clojure also brings the benefits of functional programming. This is becoming a big topic of discussion in gamedev circles, including by John Carmack. Part of this is due to the prevalence of multi-core hardware, making concurrency more important. Additionally, there is a general difficulty of maintaining object-oriented game codebases as they grow, due to complicated class hierarchies and state mutations.
Documentation
(ns game-test.core(:require[play-clj.core:refer:all][play-clj.g2d:refer:all])); define a screen, where all the action takes place(defscreenmain-screen; all the screen functions get a map called "screen" containing various; important values, and a list called "entities" for storing game objects; the entities list is immutable, so in order to update it you must simply; return a new list at the end of each screen function; this function runs only once, when the screen is first shown:on-show(fn [screenentities]; update the screen map to hold a tiled map renderer and a camera(update!screen:renderer(orthogonal-tiled-map"level1.tmx"(/ 18)):camera(orthographic))(let [; load a sprite sheet from your resources dirsheet(texture"tiles.png"); split the sheet into 16x16 tiles; (the texture! macro lets you call TextureRegion methods directly)tiles(texture!sheet:split1616); get the tile at row 6, col 0player-image(texture(aget tiles60)); add position and size to the player-image map so it can be drawnplayer-image(assoc player-image:x0:y0:width2:height2)]; return a new entities list with player-image inside of it[player-image])); this function runs every time a frame must be drawn (about 60 times per sec):on-render(fn [screenentities]; make the screen completely black(clear!); render the tiled map, draw the entities and return them(render!screenentities)); this function runs when the screen dimensions change:on-resize(fn [screenentities]; make the camera 20 tiles high, while maintaining the aspect ratio(height!screen20); you can return nil if you didn't change any entitiesnil)); define the game itself, and immediately hand off to the screen(defgamegame-test:on-create(fn [this](set-screen!thismain-screen)))
Licensing
All files that originate from this project are dedicated to the public domain. I would love pull requests, and will assume that they are also dedicated to the public domain.
↧
It's bobsleigh time: Jamaican team raises $25,000 in Dogecoin | Technology | theguardian.com
Comments:" It's bobsleigh time: Jamaican team raises $25,000 in Dogecoin | Technology | theguardian.com "
A group of supporters has raised more than $25,000 in the internet currency Dogecoin to let the Jamaican bobsleigh team attend the Winter Olympics in Sochi.
On Sunday, news broke that the team had qualified for the Winter Olympics for the first time since 2002. The two-man sled will be piloted by Winston Watt, a 46-year-old Jamaican-American who also competed in 2002, with Marvin Dixon as the brakeman.
But Watt revealed that, even after putting his own money up to fly the team to his training session, there wasn't enough money to send the two to Russia. As a result, he turned to donations, launching a PayPal account to pay for the estimated $40,000.
The Jamaican bobsleigh team achieved international fame after qualifying for the 1988 Winter Olympics with a team of four men who had very little experience in the sport. That fame was boosted with the release of Cool Runnings in 1993, a loosely fictionalised account of their trials. The film remains a cult hit, and fans spread word of Watt's plight.
One of them was Liam Butler, who runs the Dogecoin foundation along with the currency's initial creators Jackson Palmer and Billy Markus. Dogecoin is a crypto-currency, based on a combination of bitcoin, the popular digital money, and Doge, the internet meme that superimposes broken English written in Comic Sans onto pictures of Shiba Inu dogs.
"As someone who grew up in the 90's, Cool Runnings was the ultimate feel good movie about underdogs out of their element achieving their dreams," Butler told the Guardian. "When I was about 7 years old, my best friend and I had a billy-cart that his dad built. When we would start our run down his driveway, we would shout out the catchphrase from the movie: 'Feel the rhythm, feel the rhyme, get on up, it's bobsled time!'"
On Monday in Sydney, where he lives, Butler launched Dogesled, aiming to raise some of the money required to send Watt and Dixon to Sochi. "We started without a concrete plan in mind," Butler says. "I sent a few emails out… but that was the extent of it."
Within a few hours, however, the fundraiser had collected just over 26m Dogecoins. So many people had been donating, in fact, that they seemed to raise the price of the currency itself; in 12 hours, the Dogecoin to Bitcoin exchange rate rose by 50%.
"Myself and Jackson Palmer (the creator of Dogecoin) were at a local pub trivia in Sydney when we noticed the value of Dogecoin had more than doubled since we'd last checked so we raced back to my house to ensure we could get the best price for the donations in a form the team could actually use. As much as we have faith in Dogecoin to become the community currency of the internet, we still understand that the team need to buy their airfares in a fiat currency."
At the exchange rate Butler secured, he has $25,000 ready to send to the bobsleigh team, and the donations continue to flood in. It looks like the Jamaican bobsleigh team might be going to Sochi.
• US prosecutors ponder what to do with multimillion-dollar Bitcoin hoard
↧
Article 30
Comments:""
URL:http://www.bittorrent.org/beps/bep_0039.html
With episodic content or content that recieves periodic updates, it's often useful for users to be able to subscribe to subsequent episodes or revisions. This BEP aims to provide a convenient way for users to do so by allowing content providers to embed a feed URL into a torrent file.
The feed URL through which content providers can distribute updates is specified by an "update-url" key in the torrent's info dict. A GET "info_hash" parameter whose value is the hexadecimal info hash of the torrent will be added to requests sent to this URL. If a response with a 200 status and a valid torrent file is recieved, the client should download that torrent.
Because in many cases it's preferable for clients to be able to download new content without user interaction, the torrent pointed to by the feed URL should be signed. For a client to download new torrents automatically, they need to be signed by the torrent originator, who should be specified by an "originator" key within the info dict. The value of this key should be a byte string containing the originator's DER encoded X.509 certificate. See BEP 35 for details regarding torrent signing.
If a torrent is signed by its originator, and the originator's signature contains an "update-url" key inside of its optional info dict, that url will be used instead of the one in the torrent's info dict.
For each torrent with a feed URL, the client should periodically check for new downloads as described above. Once the feed URL for a torrent returns a valid torrent, the feed URL of the older torrent should no longer be checked. To continue providing updates, content providers should embed a feed URL into the newer torrent.
Example Torrent Format
{
"announce": ...,
"info": {
"originator": com.bittorrent's DER encoded x.509 certificate,
"update-url": "http://www.bittorrent.com/update-feed",
...
},
"signatures": {
"com.bittorrent": {
"signature": info dict signature,
},
...
}
}It's strongly recommended that clients implementing this BEP also implement BEP 38 . In cases where the torrents being updated are receiving new revisions of themselves, this can dramatically reduce disk usage and download time.
↧
↧
Gmane -- ANNOUNCEMENT: The Scala Programming Language
↧
Technology and jobs: Coming to an office near you | The Economist
Comments:"Technology and jobs: Coming to an office near you | The Economist"
INNOVATION, the elixir of progress, has always cost people their jobs. In the Industrial Revolution artisan weavers were swept aside by the mechanical loom. Over the past 30 years the digital revolution has displaced many of the mid-skill jobs that underpinned 20th-century middle-class life. Typists, ticket agents, bank tellers and many production-line jobs have been dispensed with, just as the weavers were.
For those, including this newspaper, who believe that technological progress has made the world a better place, such churn is a natural part of rising prosperity. Although innovation kills some jobs, it creates new and better ones, as a more productive society becomes richer and its wealthier inhabitants demand more goods and services. A hundred years ago one in three American workers was employed on a farm. Today less than 2% of them produce far more food. The millions freed from the land were not consigned to joblessness, but found better-paid work as the economy grew more sophisticated. Today the pool of secretaries has shrunk, but there are ever more computer programmers and web designers.
Remember Ironbridge
Optimism remains the right starting-point, but for workers the dislocating effects of technology may make themselves evident faster than its benefits (see article). Even if new jobs and wonderful products emerge, in the short term income gaps will widen, causing huge social dislocation and perhaps even changing politics. Technology’s impact will feel like a tornado, hitting the rich world first, but eventually sweeping through poorer countries too. No government is prepared for it.
Why be worried? It is partly just a matter of history repeating itself. In the early part of the Industrial Revolution the rewards of increasing productivity went disproportionately to capital; later on, labour reaped most of the benefits. The pattern today is similar. The prosperity unleashed by the digital revolution has gone overwhelmingly to the owners of capital and the highest-skilled workers. Over the past three decades, labour’s share of output has shrunk globally from 64% to 59%. Meanwhile, the share of income going to the top 1% in America has risen from around 9% in the 1970s to 22% today. Unemployment is at alarming levels in much of the rich world, and not just for cyclical reasons. In 2000, 65% of working-age Americans were in work; since then the proportion has fallen, during good years as well as bad, to the current level of 59%.
Worse, it seems likely that this wave of technological disruption to the job market has only just started. From driverless cars to clever household gadgets (see article), innovations that already exist could destroy swathes of jobs that have hitherto been untouched. The public sector is one obvious target: it has proved singularly resistant to tech-driven reinvention. But the step change in what computers can do will have a powerful effect on middle-class jobs in the private sector too.
Until now the jobs most vulnerable to machines were those that involved routine, repetitive tasks. But thanks to the exponential rise in processing power and the ubiquity of digitised information (“big data”), computers are increasingly able to perform complicated tasks more cheaply and effectively than people. Clever industrial robots can quickly “learn” a set of human actions. Services may be even more vulnerable. Computers can already detect intruders in a closed-circuit camera picture more reliably than a human can. By comparing reams of financial or biometric data, they can often diagnose fraud or illness more accurately than any number of accountants or doctors. One recent study by academics at Oxford University suggests that 47% of today’s jobs could be automated in the next two decades.
At the same time, the digital revolution is transforming the process of innovation itself, as our special report explains. Thanks to off-the-shelf code from the internet and platforms that host services (such as Amazon’s cloud computing), provide distribution (Apple’s app store) and offer marketing (Facebook), the number of digital startups has exploded. Just as computer-games designers invented a product that humanity never knew it needed but now cannot do without, so these firms will no doubt dream up new goods and services to employ millions. But for now they are singularly light on workers. When Instagram, a popular photo-sharing site, was sold to Facebook for about $1 billion in 2012, it had 30m customers and employed 13 people. Kodak, which filed for bankruptcy a few months earlier, employed 145,000 people in its heyday.
The problem is one of timing as much as anything. Google now employs 46,000 people. But it takes years for new industries to grow, whereas the disruption a startup causes to incumbents is felt sooner. Airbnb may turn homeowners with spare rooms into entrepreneurs, but it poses a direct threat to the lower end of the hotel business—a massive employer.
No time to be timid
If this analysis is halfway correct, the social effects will be huge. Many of the jobs most at risk are lower down the ladder (logistics, haulage), whereas the skills that are least vulnerable to automation (creativity, managerial expertise) tend to be higher up, so median wages are likely to remain stagnant for some time and income gaps are likely to widen.
Anger about rising inequality is bound to grow, but politicians will find it hard to address the problem. Shunning progress would be as futile now as the Luddites’ protests against mechanised looms were in the 1810s, because any country that tried to stop would be left behind by competitors eager to embrace new technology. The freedom to raise taxes on the rich to punitive levels will be similarly constrained by the mobility of capital and highly skilled labour.
The main way in which governments can help their people through this dislocation is through education systems. One of the reasons for the improvement in workers’ fortunes in the latter part of the Industrial Revolution was because schools were built to educate them—a dramatic change at the time. Now those schools themselves need to be changed, to foster the creativity that humans will need to set them apart from computers. There should be less rote-learning and more critical thinking. Technology itself will help, whether through MOOCs (massive open online courses) or even video games that simulate the skills needed for work.
The definition of “a state education” may also change. Far more money should be spent on pre-schooling, since the cognitive abilities and social skills that children learn in their first few years define much of their future potential. And adults will need continuous education. State education may well involve a year of study to be taken later in life, perhaps in stages.
Yet however well people are taught, their abilities will remain unequal, and in a world which is increasingly polarised economically, many will find their job prospects dimmed and wages squeezed. The best way of helping them is not, as many on the left seem to think, to push up minimum wages. Jacking up the floor too far would accelerate the shift from human workers to computers. Better to top up low wages with public money so that anyone who works has a reasonable income, through a bold expansion of the tax credits that countries such as America and Britain use.
Innovation has brought great benefits to humanity. Nobody in their right mind would want to return to the world of handloom weavers. But the benefits of technological progress are unevenly distributed, especially in the early stages of each new wave, and it is up to governments to spread them. In the 19th century it took the threat of revolution to bring about progressive reforms. Today’s governments would do well to start making the changes needed before their people get angry.
↧
git add -p: The most powerful git feature you're not using yet
Comments:"git add -p: The most powerful git feature you're not using yet"
URL:http://johnkary.net/blog/git-add-p-the-most-powerful-git-feature-youre-not-using-yet/
Update January 20, 2014 - This old post from 2012 has again become popular on Hacker News. Since first publishing this article, I've learned that the way I presented editing hunks in the second video, where I show how to edit the line spans at the top of the diff, is both not very efficient and rarely necessary. Hopefully the rest of that video is still useful.
git and GitHub have revolutionized not only how I do development, but how we developers share code.
I have two tools I need to do software development: an editor and version control.
The Pragmatic Programmer advocates you should know your editor inside and out. So why don't you know your version control system just as well?
Patch Mode
If you use git, you've used the command git add. But do you know about git add's "patch mode" using git add -p ?
Patch mode allows you to stage parts of a changed file, instead of the entire file. This allows you to make concise, well-crafted commits that make for an easier to read history.
Since I learned about it a year or so ago, patch mode has taken my git usage to another level. It's one of the most powerful git commands, right up there with rebasing, but much less dangerous!
Screencasts
I have recorded two 10-minute screencasts about how I use git add's patch mode. And I want to share them with you for free.
In the first video I walk you through why patch mode is something you should be using today, then demonstrate its basic features.
In the second video I talk through the dark art of editing hunks. Even some of the most knowledgeable git users I know have struggled with this! To really master patch mode you will want to know how to edit hunks. Never fear "patch does not apply" again!
I hope that after watching you will be armed with a new skill you can start using right away and begin to know git at a deeper level.
Please enable JavaScript to view the comments powered by Disqus.comments powered by↧
Build GIT - Learn GIT (P1) - Kushagra Gour- Creativity freak!
Comments:"Build GIT - Learn GIT (P1) - Kushagra Gour- Creativity freak!"
URL:http://kushagragour.in/blog/2014/01/build-git-learn-git/
If you are reading this post, you probably are using Git or want to use Git. I am a big fan of Git and also those posts where people implement some piece of an existing technology in order to understand how their work in the core. Point being that if you have implemented something, you obviously know how it works, right? This is one such post written to spread my love for Git. Yes, we’ll implement Git!…in JavaScript.
This part implements basics of the following concepts:
Repository. Commit. Commit chaining. Branch.All the code written is available in a Github repo:
What is Git?
There is a very simple definition of Git at kernel.org:
Git is best thought of as a tool for storing the history of a collection of files.Yeah, that is essentially why one uses Git…to maintain a history of changes in a project.
Repository (repo)
When you want to use Git in your project, you create something called a Repository. Now we could refer the Git documentation which defines a repo as follows:
A collection of refs together with an object database containing all objects which are reachable from the refs, possibly accompanied by meta data from one or more porcelains. A repository can share an object database with other repositories via alternates mechanism.Well, that is too much to grasp, isn’t it? And that is not what we are here for. So lets make things simple. Consider a Git repository as a collection of everything related to Git. So when you make a project folder a Git repo, Git basically creates some of its internal stuff there and encapsulates them into it. Having said that, lets make a simple class called Git which will basically represent a repo.
function Git(name) {
this.name = name; // Repo name
}Great! Now making a repo simply requires us to instantiate the Git class passing in the name of the repo:
var repo = new Git('my-repo');
// Actual command:
// > git initCommit
Next concept one needs to know about is a Commit. In very simple terms, a commit is a snapshot of your project’s contents. It is these commits which when chained together form the history of your project.
From the looks of it, a simple Commit class would have and id to reference it and a change containing the snapshot of change made. Understanding how a change is actually stored is beyond the scope of this implementation. So lets drop the change part and assume that every commit has the change with it:
function Commit(id) {
this.id = id;
// Assume that 'this' has a 'change' property too.
}In Git, when you commit after making some changes, you can give it a message which describes the change you are commiting. This is called the commit message which we’ll add to our Commit class:
function Commit(id, message) {
this.id = id;
this.message = message;
}Lets add the ability on our Git class to create a commit or commit (verb):
Git.prototype.commit = function (message) {
var commit = new Commit();
return commit;
};We add a function called commit on the Git prototype. It accepts a string message, creates a new Commit instance and returns it. Note that we are not passing in anything yet in the Commit constructor. We need an id to give to the new commit. We’ll make the Git class keep track of the commit ids by keeping a counter called lastCommitId with it:
function Git() {
this.lastCommitId = -1;
}Note: In actual Git, commit id is a 40-hexdigit number also called as “SHA-1 id”. But for keeping things simple we are using integers here.
The commit function can now pass a new id (incremented) along with the message in the constructor:
Git.prototype.commit = function (message) {
var commit = new Commit(++this.lastCommitId, message);
return commit;
};We can now commit anytime like so:
repo.commit('Make commit work');
// Actual command:
// > git commit -m "Make commit work"Match your code
At this point you should have your implementation that looks like the one here. I have wrapped the whole code in an Immediately invoking function expression (IIFE) and exposed the Git class manually to keep global space clean.
Commit history - chaining the commits
Git has a command called log which shows the commit history in reverse chronological order, i.e. first the lastest commit followed by previous ones.
Lets implement this log command as a method on our Git class. Our log function will return an array of commits in reverse chronological order.
Here is a simple test which should pass for our log function:
console.log('Git.log() test');
var repo = new Git('test');
repo.commit('Initial commit');
repo.commit('Change 1');
var log = repo.log();
console.assert(log.length === 2); // Should have 2 commits.
console.assert(!!log[0] && log[0].id === 1); // Commit 1 should be first.
console.assert(!!log[1] && log[1].id === 0); // And then Commit 0.Onto the implementation.
Git.prototype.log = function () {
var history = []; // array of commits in reverse order.
// 1. Start from last commit
// 2. Go back tracing to the first commit
// 3. Push in `history`
return history;
};The log function has only pseudo code right now in form of comments which tell us the logic of the function. To implement such logic 2 requirements arise:
We have a failing test case right now: Build Git - Learn Git (part 1)
Lets take up the first requirement: Knowing the last commit.
Git has something called a HEAD. In actual Git it is simply a pointer to your current branch. But since we have not covered branches yet, we’ll relax the definition here…temporarily.
What we’ll do is add a property called HEAD in the Git class which will reference the last commit’s Commit object:
function Git(name) {
this.name = name; // Repo name
this.lastCommitId = -1; // Keep track of last commit id.
this.HEAD = null; // Reference to last Commit.
}HEAD will be updated everytime a commit is made i.e. in the commit() function.
Git.prototype.commit = function (message) {
// Increment last commit id and pass into new commit.
var commit = new Commit(++this.lastCommitId, message);
// Update HEAD and current branch.
this.HEAD = commit;
return commit;
};Simple! Now we always know which was the last commit made.
Getting on the 2nd requirement: Every commit should somehow know which commit was made before it. This brings up the concept of parent in Git. Commits in Git are kept together in form a data structure called Linked Lists. Simply put, in a Linked List every item stores with itself a pointer to its parent item. This is done so that from every item, we can reach its parent item and keep following the pointers to get an ordered list. This diagram from Wikipedia will will make more sense:
For this, we add a property called parent in the Commit class which will reference its parent commit object:
function Commit(id, parent, message) {
this.id = id;
this.parent = parent;
this.message = message;
}The parent commit also needs to be passed into the Commit constructor. If you think, for a new commit what is the parent/previous commit? Yes, the current commit or the HEAD.
Git.prototype.commit = function (message) {
// Increment last commit id and pass into new commit.
var commit = new Commit(++this.lastCommitId, this.HEAD, message);Having our requirements in place, lets implement the log() function:
Git.prototype.log = function () {
// Start from HEAD
var commit = this.HEAD,
history = [];
while (commit) {
history.push(commit);
// Keep following the parent
commit = commit.parent;
}
return history;
};
// Can be used as repo.log();
// Actual command:
// > git logOur test should pass now: Build Git - Learn Git (part 1)
Match your code
At this point our code looks like this. Next up is Branches!
Branches
Hurray, we have reached at the most interesting & powerful feature of Git: Branches. So what is a Branch and what is it used for?
Imagine this scenario, you are working on a project making commits now and then. At some point may be you or one of your teammate wants to experiment something on your current work, say a different algorithm. You could surely keep making those experimental commits, but remember this was your experiment and hence not guaranteed to be kept in the main project. This way you polluted your main project.
Branches to the rescue. What you need to do here is branch out from your current line of commits so that the commits you make do not pollute the main line of development.
To quote the definition at kernel.org:
A "branch" is an active line of development. The most recent commit on a branch is referred to as the tip of that branch. The tip of the branch is referenced by a branch head, which moves forward as additional development is done on the branch. A single git repository can track an arbitrary number of branchesLets understand what a branch is. A branch is nothing but a mere pointer to some commit. Seriously, that is it. That is what makes branches in Git so lightweight and use-n-throw type. You may say HEAD was exactly this. You are right. The only difference being that HEAD is just one (because at a given time you are only on a single commit) but branches can be many, each pointing to a commit.
The ‘master’ branch
Each Git repo when initialized comes with a default branch called master. Lets understand branches through some diagrams from git-scm.com:
You create a new repository and make some commits: 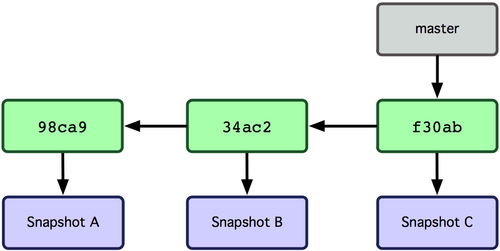
Then you create a new branch called testing: 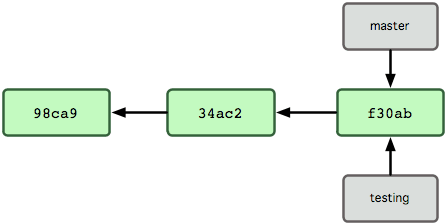
Nothing much, just a new pointer called testing to the lastest commit. How does Git knows which branch you are on? Here comes the HEAD. HEAD points to the current branch: 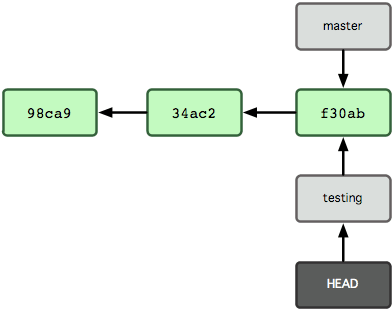
Now comes interesting part. Being on testing branch you make a commit. Notice what happens:
From now on, the testing branch/pointer only moves and not master. Looking at the above diagram and keeping our log() algorithm in mind, lets see what history would each branch return.
testing branch: Currently we are on testing branch. Moving backwards from
HEAD(commit c2b9e) and tracking the visible linkages, we get the history as: |c2b9e| -> |f30ab| -> |34ac2| -> |98ca9|master branch: If we switch to master branch, we would have a state as follows:
![]()
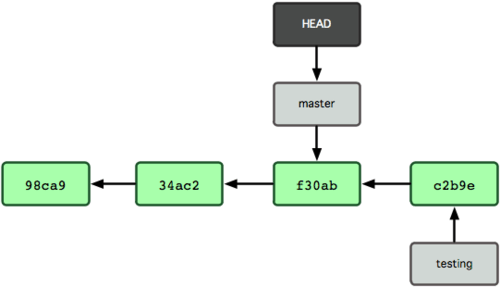
Now tracing back from HEAD gives us the history as: |f30ab| -> |34ac2| -> |98ca9|
You see what we acheived? We were able to make some experimental changes/commits without polluting the main branch (master) history using branches. Isn’t that cool!!!
Enough said, lets code. First lets make a new class for a branch. A branch, as we saw, has a name and a reference to some commit:
function Branch(name, commit) {
this.name = name;
this.commit = commit;
}By default, Git gives you a branch called master. Lets create one:
function Git(name) {
this.name = name; // Repo name
this.lastCommitId = -1; // Keep track of last commit id.
this.HEAD = null; // Reference to last Commit.
var master = new Branch('master', null); // null is passed as we don't have any commit yet.
}Remember we changed the meaning of HEAD in the beginning as we were still to cover branches? Its time we make it do what its meant for i.e. reference the current branch (master when repo is created):
function Git(name) {
this.name = name; // Repo name
this.lastCommitId = -1; // Keep track of last commit id.
var master = new Branch('master', null); // null is passed as we don't have any commit yet.
this.HEAD = master; // HEAD points to current branch.
}This will require certain changes in the commit() function as HEAD is no longer referencing a Commit but a Branch now:
Git.prototype.commit = function (message) {
// Increment last commit id and pass into new commit.
var commit = new Commit(++this.lastCommitId, this.HEAD.commit, message);
// Update the current branch pointer to new commit.
this.HEAD.commit = commit;
return commit;
};And a minor change in log function. We start from HEAD.commit now:
Git.prototype.log = function () {
// Start from HEAD commit
var commit = this.HEAD.commit,Everything works as before. To really verify what we deduced in theory by calculating history of those 2 branches above, we need one final method on our Git class: checkout.
To begin with, consider checkout as switching branches. By default we are on master branch. If I do something like repo.checkout('testing'), I should jump to testing branch…provided it is already created. But if its not created already, a new branch with that name should be created. Lets write a test for this method.
console.log('Git.checkout() test')
var repo = new Git('test');
repo.commit('Initial commit');
console.assert(repo.HEAD.name === 'master'); // Should be on master branch.
repo.checkout('testing');
console.assert(repo.HEAD.name === 'testing'); // Should be on new testing branch.
repo.checkout('master');
console.assert(repo.HEAD.name === 'master'); // Should be on master branch.
repo.checkout('testing');
console.assert(repo.HEAD.name === 'testing'); // Should be on testing branch again.This test fails right now as we don’t have a checkout method yet. Lets write one:
Git.prototype.checkout = function (branchName) {
// Check if a branch already exists with name = branchName
}The comment in above code requires that the repo maintains a list of all created branches. So we put a property called branches on Git class with initially having only master in it:
function Git(name) {
this.name = name; // Repo name
this.lastCommitId = -1; // Keep track of last commit id.
this.branches = []; // List of all branches.
var master = new Branch('master', null); // No commit yet, so null is passed.
this.branches.push(master); // Store master branch.
this.HEAD = master; // HEAD points to current branch.
}Continuing with the checkout function now. Taking first case when we find an existing branch, all we need to do is point the HEAD, the current branch pointer, to that existing branch:
Git.prototype.checkout = function (branchName) {
// Loop through all branches and see if we have a branch
// called `branchName`.
for (var i = this.branches.length; i--;){
if (this.branches[i].name === branchName) {
// We found an existing branch
console.log('Switched to existing branch: ' + branchName);
this.HEAD = this.branches[i];
return this;
}
}
// We reach here when no matching branch is found.
}I returned this from that method so that methods can be chanined. Next, incase we don’t find a branch with the passed name, we create one just like we did for master:
Git.prototype.checkout = function (branchName) {
// Loop through all branches and see if we have a branch
// called `branchName`.
for (var i = this.branches.length; i--;){
if (this.branches[i].name === branchName) {
// We found an existing branch
console.log('Switched to existing branch: ' + branchName);
this.HEAD = this.branches[i];
return this;
}
}
// If branch was not found, create a new one.
var newBranch = new Branch(branchName, this.HEAD.commit);
// Store branch.
this.branches.push(newBranch);
// Update HEAD
this.HEAD = newBranch;
console.log('Switched to new branch: ' + branchName);
return this;
}
// Actual command:
// > git checkout existing-branch
// > git checkout -b new-branchEureka! Now our checkout tests pass :)
Build Git - Learn Git (part 1)
Now the grand moment for which we created the checkout function. Verifying the awesomeness of branches through the theory we saw earlier. We’ll write one final test to verify the same:
console.log('3. Branches test');
var repo = new Git('test');
repo.commit('Initial commit');
repo.commit('Change 1');
// Maps the array of commits into a string of commit ids.
// For [C2, C1,C3], it returns "2-1-0"
function historyToIdMapper (history) {
var ids = history.map(function (commit) {
return commit.id;
});
return ids.join('-');
}
console.assert(historyToIdMapper(repo.log()) === '1-0'); // Should show 2 commits.
repo.checkout('testing');
repo.commit('Change 3');
console.assert(historyToIdMapper(repo.log()) === '2-1-0'); // Should show 3 commits.
repo.checkout('master');
console.assert(historyToIdMapper(repo.log()) === '1-0'); // Should show 2 commits. Master unpolluted.
repo.commit('Change 3');
console.assert(historyToIdMapper(repo.log()) === '3-1-0'); // Continue on master with 4th commit.This test basically represents the diagrams we saw earlier explaining the working of branches. Lets see if our implementation is inline with the theory:
Build Git - Learn Git (part 1)
Wonderful! Our implementation is right. The final code for this part can be found in GIT repo: git-part1.js.
Whats next?
Next I plan to implement concepts like merging (Fast-forward and 3-way-merge) and rebasing of branches.
I had a lot of fun writing this and hope you enjoyed it too. If you did, share the Git love with others.
Till next time, bbye.
References
Thanks JSBin for your lovely console panel :)
Update: Join the discussion on HN.
↧
↧
Linux 3.13 - Linux Kernel Newbies
Comments:"Linux 3.13 - Linux Kernel Newbies"
URL:http://kernelnewbies.org/Linux_3.13
Linux 3.13 was released on Sun, 19 Jan 2014.
Summary: This release includes nftables, the successor of iptables, a revamp of the block layer designed for high-performance SSDs, a power capping framework to cap power consumption in Intel RAPL devices, improved squashfs performance, AMD Radeon power management enabled by default and automatic Radeon GPU switching, improved NUMA performance, improved performance with hugepage workloads, TCP Fast Open enabled by default, support for NFC payments, support for the High-availability Seamless Redundancy protocol, new drivers and many other small improvements.
Prominent featuresA scalable block layer for high performance SSD storage nftables, the successor of iptables Radeon: power management enabled by default, automatic GPU switching, R9 290X Hawaii support Power capping framework Support for the Intel Many Integrated Core Architecture Improved performance in NUMA systems Improved page table access scalability in hugepage workloads Squashfs performance improved Applications can cap the rate computed by network transport layer TCP Fast Open enabled by default NFC payments support Support for the High-availability Seamless Redundancy protocol Drivers and architectures Core Memory management Block layer File systems Networking Crypto Virtualization Security Tracing/perf Other news sites that track the changes of this release1.1. A scalable block layer for high performance SSD storage
Traditional hard disks have defined for decades the design that operating systems use to communicate applications with the storage device drivers. With the advent of modern solid-state disks (SSD), past assumptions are no longer valid. Linux had a single coarse lock design for protecting the IO request queue, which can achieve an IO submission rate of around 800.000 IOs per second, regardless of how many cores are used to submit IOs. This was more than enough for traditional magnetic hard disks, whose IO submission rate in random accesses is in the hundreds, but it has become not enough for the most advanced SSD disks, which can achieve a rate close to 1 million, and are improving fast with every new generation. It is also unfit for the modern multicore world.
This release includes a new design for the Linux block layer, based on two levels of queues: one level of per-CPU queues for submitting IO, which then funnel down into a second level of hardware submission queues. The mapping between submission queues and hardware queues might be 1:1 or N:M, depending on hardware support and configuration. Experiments shown that this design can achieve many millions of IOs per second, leveraging the new capabilities of NVM-Express or high-end PCI-E devices and multicore CPUs, while still providing the common interface and convenience features of the block layer.
Paper: Linux Block IO: Introducing Multi-queue SSD Access on Multi-core Systems
Recommended LWN article: The multiqueue block layer
Code: commit
1.2. nftables, the successor of iptables
iptables has a number of limitations both at the functional and code design level, problems with the system update rules and code duplication, which cause problems for code maintenance and for users. nftables is a new packet filtering framework that solves these problems, while providing backwards compatibility for current iptable users.
The core of the nftables design is a simple pseudo-virtual machine inspired in BPF. A userspace utility interprets the rule-set provided by the user, it compiles it to pseudo-bytecode and then it transfers it to the kernel. This approach can replace thousands of lines of code, since the bytecode instruction set can express the packet selectors for all existing protocols. Because the userspace utility parses the protocols to bytecode, it is no longer necessary a specific extension in kernel-space for each match, which means that users are likely not need to upgrade the kernel to obtain new matches and features, userspace upgrades will provide them. There is also a new library for utilities that need to interact with the firewall.
nftables provides backwards iptables compatibility. There are new iptables/iptables utilities that translate iptables rules to nftables bytecode, and it is also possible to use and add new xtable modules. As a bonus, these new utilities provide features that weren't possible with the old iptables design: notification for changes in tables/chains, better incremental rule update support, and the ability to enable/disable the chains per table.
The new nft utility has a improved syntax. A small how-to is available here (other documentation should be available soon)
Recommended LWN article: The return of nftables
Video talk about nftables: http://youtu.be/P58CCi5Hhl4 (slides)
Project page and utility source code: http://netfilter.org/projects/nftables/
1.3. Radeon: power management enabled by default, automatic GPU switching, R9 290X Hawaii support
Power management enabled by default
Linux 3.11 added power management support for many AMD Radeon devices. The power management support provides improved power consumption, which is critical for battery powered devices, but it is also a requirement to provide good high-end performance, as it provides the ability to reclock to GPU to higher power states in GPUs and APUs that default to slower clock speeds.
This support had to be enabled with a module parameter. This release enables power management by default for lots of AMD Radeon hardware: BTC asics, SI asics, SUMO/PALM APUs, evergreen asics, r7xx asics, hawaii. Code: commit, commit, commit, commit, commit, commit
Linux 3.12 added infrastructure support for automatic GPU switching in laptops with dual GPUs. This release adds support for this feature in AMD Radeon hardware. Code: commit
This release adds support for R9 290X "Hawaii" devices. Code: commit
1.4. Power capping framework
This release includes a framework that allow to set power consumption limits to devices that support it. It has been designed around the Intel RAPL (Running Average Power Limit) mechanism available in the latest Intel processors (Sandy Bridge and later, many devices will also be added RAPL support in the future). This framework provides a consistent interface between the kernel and user space that allows power capping drivers to expose their settings to user space in a uniform way. You can see the Documentation here
1.5. Support for the Intel Many Integrated Core Architecture
This release adds support for the Intel Many Integrated Core Architecture or MIC, a multiprocessor computer architecture incorporating earlier work on the Larrabee many core architecture, the Teraflops Research Chip multicore chip research project, and the Intel Single-chip Cloud Computer multicore microprocessor. The currently world's fastest supercomputer, the Tianhe-2 at the National Supercomputing Center in Guangzhou, China, utilizes this architecture to achieve 33.86 PetaFLOPS.
The MIC family of PCIe form factor coprocessor devices run a 64-bit Linux OS. The driver manages card OS state and enables communication between host and card. More information about the Intel MIC family as well as the Linux OS and tools for MIC to use with this driver are available here. This release currently supports Intel MIC X100 devices, and includes a sample user space daemon.
1.6. Improved performance in NUMA systems
Modern multiprocessors (for example, x86) usually have non-uniform memory access (NUMA) memory designs. In these systems, the performance of a process can be different depending on whether the memory range it accesses it's attached to the local CPU or other CPU. Since performance is different depending on the locality of the memory accesses, it's important that the operating system schedules a process to run in the same CPU whose memory controller is connected to the memory it will access.
The way Linux handles these situations was deficient; Linux 3.8 included a new NUMA foundation that would allow to build smarter NUMA policies in future releases. This release includes many of such policies that attempt to put a process near its memory, and can handle cases such as shared pages between processes or transparent huge pages. New sysctls have been added to enable/disable and tune the NUMA scheduling (see documentation here)
Recommended LWN article: NUMA scheduling progress
1.7. Improved page table access scalability in hugepage workloads
The Linux kernels tracks information about each memory page in a data structure called page table. In workloads that use hugepages, the lock used to protect some parts of the table has become a lock contention. This release uses finer grained locking for these parts, improving the page table access scalability in threaded hugepage workloads. For more details, see the recommended LWN article.
Recommended LWN article: Split PMD locks
1.8. Squashfs performance improved
Squashfs, the read-only filesystem used by most live distributions, installers, and some embedded Linux distributions, has got important improvements that dramatically increase performance in workloads with multiple parallel reads. One of them is the direct decompression of data into the Linux page cache, which avoids a copy of the data and eliminates the single lock used to protect the intermediate buffer. The other one is multithreaded decompression.
1.9. Applications can cap the rate computed by network transport layer
This release adds a new socket option, SO_MAX_PACING_RATE, which offers applications the ability to cap the rate computed by transport layer. It has been designed as a bufferbloat mechanism to avoid buffers getting filled up with packets, but it can also be used to limit the transmission rate in applications. To be effectively paced, a network flow must use FQ packet scheduler. Note that a packet scheduler takes into account the headers for its computations. For more details, see the:
Recommended LWN article: TSO sizing and the FQ scheduler (5th and 6th paragraph)
Code: commit
1.10. TCP Fast Open enabled by default
TCP Fast Open is an optimization to the process of stablishing a TCP connection that allows the elimination of one round time trip from certain kinds of TCP conversation, which can improve the load speed of web pages. In Linux 3.6 and Linux 3.7, support was added for this feature, which requires userspace support. This release enables TCP Fast Open by default.
Code: commit
1.11. NFC payments support
This release implements support for the Secure Element. A netlink API is available to enable, disable and discover NFC attached (embedded or UICC ones) secure elements. With some userspace help, this allows to support NFC payments, used to implement financial transactions. Only the pn544 driver currently supports this API.
Code: commit
1.12. Support for the High-availability Seamless Redundancy protocol
High-availability Seamless Redundancy (HSR) is a redundancy protocol for Ethernet. It provides instant failover redundancy for such networks. It requires a special network topology where all nodes are connected in a ring (each node having two physical network interfaces). It is suited for applications that demand high availability and very short reaction time.
Code: commit
All the driver and architecture-specific changes can be found in the Linux_3.13-DriversArch page
epoll: once we get over 10+ cpus, the scalability of SPECjbb falls over due to the contention on the global 'epmutex', which is taken in on EPOLL_CTL_ADD and EPOLL_CTL_DEL operations. This release improves locking to improve performance: on the 16 socket run the performance went from 35k jOPS to 125k jOPS. In addition the benchmark when from scaling well on 10 sockets to scaling well on just over 40 sockets commit, commit
Allow magic sysrq key functions to be disabled in Kconfig commit
modules: remove rmmod --wait option. commit
iommu: Add event tracing feature to iommu commit
Add option to disable kernel compression commit
gcov: add support for gcc 4.7 gcov format commit
fuse: Implement writepages callback, improving mmaped writeout commit
seqcount: Add lockdep functionality to seqcount/seqlock structures commit
Provide a per-cpu preempt_count implementation commit
/proc/pid/smaps: show VM_SOFTDIRTY flag in VmFlags line commit
Add a generic associative array implementation. commit
RCU'd vfsmounts commit
Changes in the slab have been done to improve the slab memory usage and performance. kmem_caches consisting of objects less than or equal to 128 byte have now one more objects in a slab, and a change to the management of free objects improves the locality of the accesses, which improve performance in some microbenchmarks commit, commit
memcg: support hierarchical memory.numa_stats commit
Introduce movable_node boot option to enable the effects of CONFIG_MOVABLE_NODE commit
thp: khugepaged: add policy for finding target node commit
bcache: Incremental garbage collection. It means that there's less of a latency hit for doing garbage collection, which means bcache can gc more frequently (and do a better job of reclaiming from the cache), and it can coalesce across more btree nodes (improving space efficiency) commit
dm cache: add passthrough mode which is intended to be used when the cache contents are not known to be coherent with the origin device commit
dm cache: add cache block invalidation support commit
dm cache: cache shrinking support commit
virtio_blk: blk-mq support commit
Multi-queue aware null block test driver commit
Add FIEMAP_EXTENT_SHARED fiemap flag: Similar to ocfs2, btrfs also supports that extents can be shared by different inodes, and there are some userspace tools requesting for this kind of 'space shared infomation' commit
Add new btrfs mount options: commit, which sets the interval of periodic commit in seconds, 30 by default, and rescan_uuid_tree, which forces check and rebuild procedure of the UUID tree commit
XFS: For v5 filesystems scale the inode cluster size with the size of the inode so that we keep a constant 32 inodes per cluster ratio for all inode IO commit
F2FS Introduce CONFIG_F2FS_CHECK_FS to disable BUG_ONs which check the file system consistency in runtime and cost performance commit
SMB2/SMB3 Copy offload support (refcopy, aka "cp --reflink") commit
Query File System alignment, and the preferred (for performance) sector size and whether the underlying disk has no seek penalty (like SSD), make it visible in /proc/fs/cifs/DebugData for debugging purposes commit
Query network adapter info commit
Allow setting per-file compression commit, commit
Add a lightweight Berkley Packet Filter-based traffic classifier that can serve as a flexible alternative to ematch-based tree classification, i.e. now that BPF filter engine can also be JITed in the kernel commit
ipv6: Add support for IPsec virtual tunnel interfaces, which provide a routable interface for IPsec tunnel endpoints commit
ipv4: introduce new IP_MTU_DISCOVER mode IP_PMTUDISC_INTERFACE. Sockets marked with IP_PMTUDISC_INTERFACE won't do path mtu discovery, their sockets won't accept and install new path mtu information and they will always use the interface mtu for outgoing packets. It is guaranteed that the packet is not fragmented locally. The purpose behind this flag is to avoid PMTU attacks, particularly on DNS servers commit
ipv4: Allow unprivileged users to use network namespaces sysctls commit
Create sysfs symlinks for neighbour devices commit
ipv6: sit: add GSO/TSO support commit
ipip: add GSO/TSO support commit
packet scheduler: htb: support of 64-bit rates commit
openvswitch: TCP flags matching support. commit
Add network namespaces commit
Support comments for ipset entries in the core. commit, in bitmap-type ipsets commit, in hash-type ipsets commit, and in the list-type ipset. commit
Enable ipset port set types to match IPv4 package fragments for protocols that doesn't have ports (or the port information isn't supported by ipset) commit
Add hash:net,net set, providing the ability to configure pairs of subnets commit
Add hash:net,port,net set, providing similar functionality to ip,port,net but permits arbitrary size subnets for both the first and last parameter commit
Add NFC digital layer implementation: Most NFC chipsets implement the NFC digital layer in firmware, but others only implement the NFC analog layer and expect the host to implement this layer
Add support for NFC-A technology at 106 kbits/s commit
Add support for NFC-F technology at 212 kbits/s and 424 kbits/s commit
Add initiator NFC-DEP support commit
Add target NFC-DEP support commit
Implement the mechanism used to send commands to the driver in initiator mode commit
Digital Protocol stack implementation commit
Introduce new HCI socket channel that allows user applications to take control over a specific HCI device. The application gains exclusive access to this device and forces the kernel to stay away and not manage it commit, commit
Add support creating virtual AMP controllers commit
Add support for setting Device Under Test mode commit
Add a new mgmt_set_bredr command for enabling/disabling BR/EDR functionality. This can be convenient when one wants to make a dual-mode controller behave like a single-mode one. The command is only available for dual-mode controllers and requires that Bluetooth LE is enabled before using it commit
Add management command for setting static address on dual-mode BR/EDR/LE and LE only controllers where it is possible to configure a random static address commit
Add new management setting for enabling and disabling Bluetooth LE advertising commit, commit
tcp_memcontrol: Remove setting cgroup settings via sysctl, because the code is broken in both design and implementation and does not implement the functionality for which it was written for commit
wifi: implement mesh channel switch userspace API commit
wifi: enable channels 52-64 and 100-144 for world roaming commit
wifi: enable DFS for IBSS mode commit, commit, add support for CSA in IBSS mode commit,
B.A.T.M.A.N.: remove vis functionality (replaced by a userspace program) commit, add per VLAN interface attribute framework commit, add the T(ype) V(ersion) L(ength) V(alue) framework commit, commit, commit, commit
caam: Add platform driver for Job Ring, which are part of Freescale's Cryptographic Accelerator and Assurance Module (CAAM) commit
random: Our mixing functions were analyzed, they suggested a slight change to improve our mixing functions which has been implemented commit
random32: upgrade taus88 generator to taus113 from errata paper commit
hyperv: fb: add blanking support commit, add PCI stub, the hyperv framebuffer driver will bind to the PCI device then, so Linux kernel and userspace know there is a proper kernel driver for the device active commit
kvm: Add VFIO device commit
xen-netback: add support for IPv6 checksum offload to guest commit
xen-netback: enable IPv6 TCP GSO to the guest commit
xen-netfront: convert to GRO API commit
SELinux: Enable setting security contexts on rootfs (ramfs) inodes. commit
SELinux: Reduce overhead that harmed the high_systime workload of the AIM7 benchmark commit
SELinux: Add the always_check_network policy capability which, when enabled, treats SECMARK as enabled, even if there are no netfilter SECMARK rules and treats peer labeling as enabled, even if there is no Netlabel or labeled IPsec configuration.policy capability for always checking packet and peer classes commit
Smack treats setting a file read lock as the write operation that it is. Unfortunately, many programs assume that setting a read lock is a read operation, and don't work well in the Smack environment. This release implements a new access mode (lock) to address this problem commit
Smack: When the ptrace security hooks were split the addition of a mode parameter was not taken advantage of in the Smack ptrace access check. This changes the access check from always looking for read and write access to using the passed mode commit
audit: new feature which only grants processes with CAP_AUDIT_CONTROL the ability to unset their loginuid commit
audit: feature which allows userspace to set it such that the loginuid is absolutely immutable, even if you have CAP_AUDIT_CONTROL. CONFIG_AUDIT_LOGINUID_IMMUTABLE has been removed commit, commit
keys: Expand the capacity of a keyring commit
keys: Implement a big key type that can save to tmpfs commit
keys: Add per-user namespace registers for persistent per-UID kerberos caches commit
ima: add audit log support for larger hashes commit
ima: enable support for larger default filedata hash algorithms commit
ima: new templates management mechanism commit
perf record: Add option --force-per-cpu to force per-cpu mmaps commit
perf record: Add abort_tx,no_tx,in_tx branch filter options to perf record -j commit
perf report: Add --max-stack option to limit callchain stack scan commit
perf top: Add new option --ignore-vmlinux to explicitly indicate that we do not want to use these kernels and just use what we have (kallsyms commit
perf tools: Add possibility to specify mmap size via -m/--mmap-pages by appending unit size character (B/K/M/G) to the number commit
perf top: Add --max-stack option to limit callchain stack scan commit
perf stat: Add perf stat --transaction to print the basic transactional execution statistics commit
perf: Add support for recording transaction flags commit
perf: Support sorting by in_tx or abort branch flags commit
ftrace: Add set_graph_notrace filter, analogous to set_ftrace_notrace and can be used for eliminating uninteresting part of function graph trace output commit
perf bench sched: Add --threaded option, allow the measurement of thread versus process context switch performance commit
perf buildid-cache: Add ability to add kcore to the cache commit
↧
Marginally Interesting: Apache Spark: The Next Big Data Thing?
Comments:"Marginally Interesting: Apache Spark: The Next Big Data Thing?"
URL:http://blog.mikiobraun.de/2014/01/apache-spark.html
Friday, January 17, 2014
Apache Spark is generating quite some buzz right now. Databricks, the company founded to support Spark raised $14M from Andreessen Horowitz, Cloudera has decided to fully support Spark, and others chime in that it’s the next bigthing. So I thought it’s high time I took a look to get an understanding what the whole buzz is around.
I played around with the Scala API (Spark is written in Scala), and to be honest, at first I was pretty underwhelmed, because Spark looked, well, so small. The basic abstraction are Resilient Distributed Datasets (RDDs), basically distributed immutable collections, which can be defined based on local files or files stored in on Hadoop via HDFS, and which provide the usual Scala-style collection operations like map, foreach and so on.
My first reaction was “wait, is this basically distributed collections?” Hadoop in comparison seemed to be so much more, a distributed filesystem, obviously map reduce, with support for all kinds of data formats, data sources, unit testing, clustering variants, and so on and so on.
Others quickly pointed out that there’s more to it, in fact, Spark also provides more complex operations like joins, group-by, or reduce-by operations so that you can model quite complex data flows (without iterations, though).
Over time it dawned on me that the perceived simplicity of Spark actually said a lot more about the Java API of Hadoop than Spark. Even simple examples in Hadoop usually come with a lot of boilerplate code. But conceptually speaking, Hadoop is quite simple as it only provides two basic operations, a parallel map, and a reduce operation. If expressed in the same way on something resembling distributed collections, one would in fact have an even smaller interface (some projects like Scalding actually build such things and the code looks pretty similar to that of Spark).
So after convincing me that Spark actually provides a non-trivial set of operations (really hard to tell just from the ubiqitous word count example), I digged deeper and read this paper which describes the general architecture. RDDs are the basic building block of Spark and are actually really something like distributed immutable collections. These define operations like map or foreach which are easily parallelized, but also join operations which take two RDDs and collects entries based on a common key, as well as reduce-by operations which aggregates entries using a user specified function based on a given key. In the word count example, you’d map a text to all the words with a count of one, and then reduce them by key using the word and summing up the counts to get the word counts. RDDs can be read from disk but are then held in memory for improved speed where they can also be cached so you don’t have to reread them every time. That alone adds a lot of speed compared to Hadoop which is mostly disk based.
Now what’s interesting is Spark’s approach to fault tolerance. Instead of persisting or checkpointing intermediate results, Spark remembers the sequence of operations which led to a certain data set. So when a node fails, Spark reconstructs the data set based on the stored information. They argue that this is actually not that bad because the other nodes will help in the reconstruction.
So in essence, compared to bare Hadoop, Spark has a smaller interface (which might still become similarly bloated in the future), but there are many projects on top of Hadoop (like Twitter’s Scalding, for example), which achieve a similar level of expressiveness. The other main difference is that Spark is in-memory by default, which naturally leads to a large improvement in performance, and even allows to run iterative algorithms. Spark has no built- in support for iterations, though, it’s just that they claim it’s so fast that you can run iterations if you want to.
Spark Streaming - return of the micro-batch
Spark also comes with a streaming data processing model, which got me quite interested, of course. There is again a paper which summarizes the design quite nicely. Spark follows an interesting and different approach compared to frameworks like Twitter’s Storm. Storm is basically like a pipeline where you push individual events in which then get processed in a distributed fashion. Instead, Spark follows a model where events are collected and then processed at short time intervals (let’s say every 5 seconds) in a batch manner. The collected data become an RDD of their own which is then processed using the usual set of Spark applications.
The authors claim that this mode is more robust against slow nodes and failures, and also that the 5 second interval are usually fast enough for most applications. I’m not so sure about this, as distributed computing is always pretty complex and I don’t think you can easily say that something’s are generally better than others. This approach also nicely unifies the streaming with the non- streaming parts, which is certainly true.
Final thoughts
What I saw looked pretty promising, and given the support and attention Spark receives, I’m pretty sure it will mature and become a strong player in the field. It’s not well-suited for everything. As the authors themselves admit, it’s not really well suited to operations which require to change only a few entries the data set at the time due to the immutable nature of the RDDs. In principle, you have to make a copy of the whole data set even if you just want to change one entry. This can be nicely paralellized, but is of course costly. More efficient implementations based on copy-on-write schemes might also work here, but are not implement yet if I’m not mistaken.
Stratosphere is research project at the TU Berlin which has similar goals, but takes the approach even further by including more complex operations like iterations and not only storing the sequence of operations for fault tolerance, but to use them for global optimization of the scheduling and paralellization.
Immutability is pretty on vogue here as it’s easier to reason about, but I’d like to point you to this excellent article by Baron Schwartz on how you’ll always end up with mixed strategies (mutable and immutable data) to make it work in the real-world.
Posted by Mikio L. Braun at Fri Jan 17 16:12:00 +0100 2014
View the discussion thread.blog comments powered by↧
Oxfam: 85 richest people as wealthy as poorest half of the world | Business | theguardian.com
Comments:" Oxfam: 85 richest people as wealthy as poorest half of the world | Business | theguardian.com "
URL:http://www.theguardian.com/business/2014/jan/20/oxfam-85-richest-people-half-of-the-world

The InterContinental Davos luxury hotel in the Swiss mountain resort of Davos. Oxfam report found people in countries around the world believe that the rich have too much influence over the direction their country is heading. Photograph: Arnd Wiegmann/REUTERS
The world's wealthiest people aren't known for travelling by bus, but if they fancied a change of scene then the richest 85 people on the globe – who between them control as much wealth as the poorest half of the global population put together – could squeeze onto a single double-decker.
The extent to which so much global wealth has become corralled by a virtual handful of the so-called 'global elite' is exposed in a new report from Oxfam on Monday. It warned that those richest 85 people across the globe share a combined wealth of £1tn, as much as the poorest 3.5 billion of the world's population.
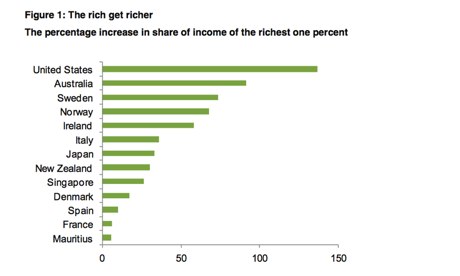 Source: F. Alvaredo, A. B. Atkinson, T. Piketty and E. Saez, (2013) ‘The World Top Incomes Database’, http://topincomes.g-mond.parisschoolofeconomics.eu/ Only includes countries with data in 1980 and later than 2008. Photograph: Oxfam
Source: F. Alvaredo, A. B. Atkinson, T. Piketty and E. Saez, (2013) ‘The World Top Incomes Database’, http://topincomes.g-mond.parisschoolofeconomics.eu/ Only includes countries with data in 1980 and later than 2008. Photograph: Oxfam
The wealth of the 1% richest people in the world amounts to $110tn (£60.88tn), or 65 times as much as the poorest half of the world, added the development charity, which fears this concentration of economic resources is threatening political stability and driving up social tensions.
It's a chilling reminder of the depths of wealth inequality as political leaders and top business people head to the snowy peaks of Davos for this week's World Economic Forum. Few, if any, will be arriving on anything as common as a bus, with private jets and helicopters pressed into service as many of the world's most powerful people convene to discuss the state of the global economy over four hectic days of meetings, seminars and parties in the exclusive ski resort.
Winnie Byanyima, the Oxfam executive director who will attend the Davos meetings, said: "It is staggering that in the 21st Century, half of the world's population – that's three and a half billion people – own no more than a tiny elite whose numbers could all fit comfortably on a double-decker bus."
Oxfam also argues that this is no accident either, saying growing inequality has been driven by a "power grab" by wealthy elites, who have co-opted the political process to rig the rules of the economic system in their favour.
In the report, entitled Working For The Few (summary here), Oxfam warned that the fight against poverty cannot be won until wealth inequality has been tackled.
"Widening inequality is creating a vicious circle where wealth and power are increasingly concentrated in the hands of a few, leaving the rest of us to fight over crumbs from the top table," Byanyima said.
Oxfam called on attendees at this week's World Economic Forum to take a personal pledge to tackle the problem by refraining from dodging taxes or using their wealth to seek political favours.
As well as being morally dubious, economic inequality can also exacerbate other social problems such as gender inequality, Oxfam warned. Davos itself is also struggling in this area, with the number of female delegates actually dropping from 17% in 2013 to 15% this year.
How richest use their wealth to capture opportunities
Polling for Oxfam's report found people in countries around the world - including two-thirds of those questioned in Britain - believe that the rich have too much influence over the direction their country is heading.
Byanyima explained:
"In developed and developing countries alike we are increasingly living in a world where the lowest tax rates, the best health and education and the opportunity to influence are being given not just to the rich but also to their children.
"Without a concerted effort to tackle inequality, the cascade of privilege and of disadvantage will continue down the generations. We will soon live in a world where equality of opportunity is just a dream. In too many countries economic growth already amounts to little more than a 'winner takes all' windfall for the richest."
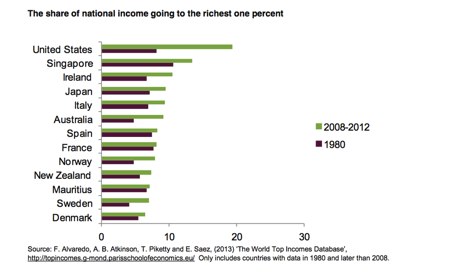 Source: F. Alvaredo, A. B. Atkinson, T. Piketty and E. Saez, (2013) ‘The World Top Incomes Database’, http://topincomes.g-mond.parisschoolofeconomics.eu/ Only includes countries with data in 1980 and later than 2008. Photograph: Oxfam
Source: F. Alvaredo, A. B. Atkinson, T. Piketty and E. Saez, (2013) ‘The World Top Incomes Database’, http://topincomes.g-mond.parisschoolofeconomics.eu/ Only includes countries with data in 1980 and later than 2008. Photograph: Oxfam
The Oxfam report found that over the past few decades, the rich have successfully wielded political influence to skew policies in their favour on issues ranging from financial deregulation, tax havens, anti-competitive business practices to lower tax rates on high incomes and cuts in public services for the majority. Since the late 1970s, tax rates for the richest have fallen in 29 out of 30 countries for which data are available, said the report.
This "capture of opportunities" by the rich at the expense of the poor and middle classes has led to a situation where 70% of the world's population live in countries where inequality has increased since the 1980s and 1% of families own 46% of global wealth - almost £70tn.
Opinion polls in Spain, Brazil, India, South Africa, the US, UK and Netherlands found that a majority in each country believe that wealthy people exert too much influence. Concern was strongest in Spain, followed by Brazil and India and least marked in the Netherlands.
In the UK, some 67% agreed that "the rich have too much influence over where this country is headed" - 37% saying that they agreed "strongly" with the statement - against just 10% who disagreed, 2% of them strongly.
The WEF's own Global Risks report recently identified widening income disparities as one of the biggest threats to the world community.
Oxfam is calling on those gathered at WEF to pledge: to support progressive taxation and not dodge their own taxes; refrain from using their wealth to seek political favours that undermine the democratic will of their fellow citizens; make public all investments in companies and trusts for which they are the ultimate beneficial owners; challenge governments to use tax revenue to provide universal healthcare, education and social protection; demand a living wage in all companies they own or control; and challenge other members of the economic elite to join them in these pledges.
• Research Now questioned 1,166 adults in the UK for Oxfam between October 1 and 14 2013.
↧
Baboom
Comments:"Baboom"
↧
↧
The 2 Biggest Mistakes I Made (Before Reaching $500 MRR)
Comments:"The 2 Biggest Mistakes I Made (Before Reaching $500 MRR)"
URL:https://www.wisecashhq.com/blog/the-2-biggest-mistakes-i-made-before-reaching-500-mrr
I launched WiseCash in July 2013 and reached $500 MRR in roughly 6 months:
While I’m happy to have reached that milestone already (yay!), I made two huge mistakes in the process. I’m sharing those mistakes so that you, dear reader, can avoid it. I would be much closer from completely sustaining my family with WiseCash alone, without those two mistakes. Read on and avoid shooting yourself in the foot.
Charging Later Than I Should Have Done
Biggest mistake ever. Who would want to delay their income? It sounds crazy, especially with a SaaS and its typical Long, Slow Ramp of Death. I should (and could, in retrospect) have charged roughly one year earlier. 12 months. Extrapolating on the current growth trends I have + historical data, WiseCash would currently account for 27% of our “minimum family revenue” instead of 10% currently:
The reasons for shipping later were numerous and all good looking: a lot of time spent figuring out which billing service to pick, VAT handling, paperwork, a new baby on its way in the family, too much consulting (I later changed the way I organize my gigs and balance this with product work, by using WiseCash itself), a feature that was deemed super necessary, etc.
My point here is that despite these good reasons, I should still have prioritized billing code and related paperwork earlier on the roadmap, and maybe delay a feature and some consulting work. If you are not charging, you didn’t ship yet. Ship it. Getting paid subscribers will be veeery sloooow, so do it earlier than later.
Failing To Warm Up a Proper Newsletter
I put a super simple landing page online in September 2011. I tweeted about WiseCash as I built it, and eventually got around 900 emails in the waiting list (half of them coming after a beta tester submitted the landing page to HackerNews).
My failure here is that I did not email the list regularly, failed to build tension, failed to figure out what I should write about, and as well handled the collection of emails in my app rather than in MailChimp (or similar).
In retrospect I should have done this:
- getting comfortable with newsletter services
- setting up a mail campaign for the sake of learning
- making sure it renders properly on mobile
- getting comfortable with writing newsletters
- sending a few words each month (fixed schedule) to my subscribers
In all cases, I should never have left a mailing list sleeping almost one year without any message.
The biggest thing that blocked me (and seems to block many bootstrappers I discussed with) is figuring out what to write to my subscribers. There was so much I could have written about: how WiseCash and cash flow control help you negotiate your rates, bootstrap your own product, pick the kind of gig you want to work on etc. Or even: the things I learned as I build WiseCash (technical or not). Anything that would increase trust gradually.
My conversion rate when sending a lifetime offer to beta-testers was around 1%. Being more comfortable with emailing would definitely have increased this several times (based on discussions with experienced bootstrappers) — here is a visual estimate:
My point here is: make sure to get comfortable with email newsletter and writing. This is critical.
These Errors Do Stack Up
I could be around 37% (again a vague estimate, but still much higher than today) without these mistakes:
Being closer from financial independence without consulting would let me work on WiseCash (promoting it, writing educational content, crafting features) more than I already do today.
Despite these two big mistakes and the fact that revenue takes a lot of time to grow, I’m glad we’ve been dogfooding and used WiseCash to know our “time-wealth” (= how long we can sustain our current lifestyle given planned expenses and income) since the beginning, because this allowed us to never even remotely risk bankruptcy, keep a health family life and mix product development with balanced consulting the whole time.
I’ll discuss this topic (“Sustainable Bootstrapping”) in an upcoming post, make sure to subscribe to updates!
PS: thanks for sharing this article around!
↧
NHS patient data to be made available for sale to drug and insurance firms | Society | The Guardian
URL:http://www.theguardian.com/society/2014/jan/19/nhs-patient-data-available-companies-buy

If an application is approved then firms will have to pay to extract NHS patient information, which will be scrubbed of some personal identifiers Photograph: Dominic Lipinski/PA
Drug and insurance companies will from later this year be able to buy information on patients – including mental health conditions and diseases such as cancer, as well as smoking and drinking habits – once a single English database of medical data has been created.
Harvested from GP and hospital records, medical data covering the entire population will be uploaded to the repository controlled by a new arms-length NHS information centre, starting in March. Never before has the entire medical history of the nation been digitised and stored in one place.
Advocates say that sharing data will make medical advances easier and ultimately save lives because it will allow researchers to investigate drug side effects or the performance of hospital surgical units by tracking the impact on patients.
But privacy experts warn there will be no way for the public to work out who has their medical records or to what use their data will be put. The extracted information will contain NHS numbers, date of birth, postcode, ethnicity and gender.
Once live, organisations such as university research departments – but also insurers and drug companies – will be able to apply to the new Health and Social Care Information Centre (HSCIC) to gain access to the database, called care.data.
If an application is approved then firms will have to pay to extract this information, which will be scrubbed of some personal identifiers but not enough to make the information completely anonymous – a process known as "pseudonymisation".
However, Mark Davies, the centre's public assurance director, told the Guardian there was a "small risk" certain patients could be "re-identified" because insurers, pharmaceutical groups and other health sector companies had their own medical data that could be matched against the "pseudonymised" records. "You may be able to identify people if you had a lot of data. It depends on how people will use the data once they have it. But I think it is a small, theoretical risk," he said.
Once the scheme is formally approved by the HSCIC and patient data can be downloaded from this summer, Davies said that in the eyes of the law one could not distinguish between "a government department, university researcher, pharmaceutical company or insurance company" in a request to access the database.
In an attempt to ease public concern, this month NHS England is sending a leaflet entitled Better Information Means Better Care to 26m households, to say parts of the care.data database will be shared with "researchers and organisations outside the NHS" – unless people choose to opt out via their family doctor.
However, a leading academic and government adviser on health privacy said pursuing a policy that opened up data to charities and companies without clearly spelling out privacy safeguards left serious unanswered questions about patient confidentiality.
Julia Hippisley-Cox, a professor of general practice at Nottingham University who sits on the NHS's confidentiality advisory group – the high-level body that advises the health secretary on accessing confidential patient data without consent – said that while there may be "benefits" from the scheme "if extraction [sale] of identifiable data is to go ahead, then patients must be able find out who has their identifiable data and for what purpose".
Hippisley-Cox added that "there should be a clear audit trail which the patient can access and there needs to be a simple method for recording data sharing preferences and for these to be respected".
Davies, who is a GP, defended the database, saying there was "an absolute commitment to transparency" and rejecting calls for an "independent review and scrutiny of requests for access to data". "I am tempted to say that we will have 50 million auditors [referring to England's population] looking over our shoulder."
He said it was necessary to open up medical data to commercial companies especially as private firms take over NHS services to "improve patient care". Davies said: "We have private hospitals and companies like Virgin who are purchasing NHS patient care now. This is a trend that will continue. As long as they can show patient care is benefiting then they can apply."
But Davies accepted there was now a "need to open a debate on this".
He pointed out that a number of private companies – such as Bupa – already had access to some sensitive hospital data, although none had been able to link to GP records until now. He added: "I am not sure how helpful in the NHS the distinction between public and private is these days. Look at Dr Foster [which] is a private company that used data to show significantly how things can be improved in the NHS and revealed what was going wrong at Mid Staffs. The key test is whether the data will be used to improve patient care."
Campaigners warned many members of the public would be uneasy about private companies benefiting from their health data – especially when the spread of data will not be routinely audited. Phil Booth, co-ordinator at patient pressure group medConfidential, said: "One of people's commonest concerns about their medical records is that they'll be used for commercial purposes, or mean they are discriminated against by insurers or in the workplace.
"Rather than prevent this, the care.data scheme is deliberately designed so that 'pseudonymised' data – information that can be re-identified by anyone who already holds information about you – can be passed on to 'customers' of the information centre, with no independent scrutiny and without even notifying patients. It's a disaster just waiting to happen."
Booth said the five listed reasons data can be released for are exceptionally broad: health intelligence, health improvement, audit, health service research and service planning. He said: "Officials would have you believe they're doing this all for research or improving care but the number of non-medical, non-research uses is ballooning before even the first upload has taken place. And though you won't read it in their junk mail leaflet, the people in charge now admit the range of potential customers for this giant centralised database of all our medical records is effectively limitless."
NHS England said it would publish its own assessment of privacy risks this week and pointed out that one of the key aims of care.data was to "drive economic growth by making England the default location for world-class health services research".
A spokesperson said: "A phased rollout of care.data is being readied over a three month period with first extractions from March allowing time for the HSCIC to assess the quality of the data and the linkage before making the data available. We think it would be wrong to exclude private companies simply on ideological grounds; instead, the test should be how the company wants to use the data to improve NHS care."
↧
Smoking is Worse Than You Imagined
↧
To the Girls of HackerNews: I am a Female Founder who Codes | Susie Ye
Comments:"To the Girls of HackerNews: I am a Female Founder who Codes | Susie Ye"
URL:http://susieye.com/2014/01/20/to-the-girls-of-hackernews-i-am-a-female-founder-who-codes/
Female founders who also code are unicorns in the startup world. The female founders that I’ve read about or met in person are all “industry” or “business”–they have the vision and experience, but not the technical abilities so prized in Silicon Valley. Which is why I’m glad that Paul Graham recently chose to address the issue in his article, Female Founders.
He concluded that in order to have more female founders, we need more girls to become programmers, and to do that, we should give girls more examples of female role models. I agree with this sentiment wholeheartedly, and would like to take this a step further by adding this postscript: we should give girls female role models who code technically difficult ideas in all domains and not simply fashion, non-profit, and e-commerce.
Not that there’s anything wrong with fashion, non-profit, or e-commerce startups, but it seems to me that women naturally gravitate towards those domains partly because of their own interest, but also in part because those are the areas in which the world will take you seriously. When my previous co-founder and I (both women) were brainstorming ideas, we considered 3 target audiences: Moms, Teachers (and we always envisioned female teachers), and 25 – 40 year old working women, even though I knew nothing about those demographics. There’s an unspoken expectation that women founders can only build businesses that appeal to women audiences — mostly shopping, motherhood, or home and lifestyle. We automatically discount ideas in other fields because our gender subtracts points in the “domain expertise” section of our resume.
My current co-founder and I are working on an idea to teach others how to code web apps. Let me preface this by saying that he’s a 25-year old dude who went to Harvard. When we pitch our idea to others, decide on who’s the face of our company, or who will do the voiceover for our videos, we both agree without discussion it should be him. It’s not because I can’t speak as well or I don’t know the material — it’s because he fits the mold so much better. And here’s the even more crazy confession: I would never have pursued this idea with another female founder. And if I did, it would probably have targeted women.
I guess what I’m trying to say is if you’re a girl, you should learn to code, and build whatever crazy idea you have. Forget the rest. It’s not as hard or exclusive as they make it out to be. It’s no more difficult than learning broken French, or how to play the piano. You don’t have to be a CS major at MIT, or play RPGs with the boys. You can drink your soy lattes and practice your yoga and read your Vogue magazines, and then go on to build Temple Run, or Eventbrite, or even Y-Combinator.
When I first began learning to code, people rarely took me seriously. I got admiration for expressing the sentiment, but few expected anything to come of my efforts. Perhaps due to this kind of well-intentioned but still patronizing reaction, I am reluctant to admit to anyone that I can code. Assigning a label to myself like “hacker” or “developer” gives me the heebie-jeebies. I don’t think I have enough experience or technical know-how for those labels, yet I am still cracking away at this coding thing, working on projects that give me immense satisfaction, all without selling a single piece of jewelry.
Trust me when I say I am the last person anyone would ever have expected to learn these skills. But if you decide you’re interested in learning, take a leap and try. You can even message me with your questions or ramblings. I promise I will try to help. And if you insist on hiding your newfound skills, I won’t tell if you won’t.
-Susie
Co-founder @ BaseRails
[Note: I'm really overwhelmed and thankful for all the comments and emails and tweets! It was unexpected to say the least. I appreciate everyone's thoughtful insights and feedback ![]() ]
]
↧
↧
A big step towards generational and compacting GC | Nicholas Nethercote
Comments:"A big step towards generational and compacting GC | Nicholas Nethercote"
URL:https://blog.mozilla.org/nnethercote/2014/01/20/a-big-step-towards-generational-and-compacting-gc/
People frequently ask me for status updates on generational GC, and I usually say I’ll tell them when something notable happens. Well, something notable just happened: exact rooting landed.
What is exact rooting? In order to support generational and/or compacting GC, you need to be able to move GC-allocated things such as objects around. This means you can’t have raw C++ pointers to any objects that might move; instead, you need some kind of indirect pointer that can be updated when necessary.
Unfortunately, both the JS engine and Gecko have a lot of pointers to GC-allocated things. The process of checking and converting them has been the main part of a task called “exact rooting”, and that’s what just finished. This has required an enormous amount of what is essentially very tedious work. Jim Blandy summarized it nicely, as follows.
I’ve never heard of a major project escaping from conservative GC once it had entered that state of sin; nor have I heard of anyone implementing a moving collector after starting with a non-moving collector. So, doing *both* is impressive. I hope it pays off big!Major kudos to Terrence Cole, Steve Fink, Jon Coppeard, Brian Hackett, and the small army of other helpers who did this. Now that they’ve finished eating this gigantic serving of vegetables, they can move onto dessert, i.e. making the GC generational and compacting.
↧
hike.io
Comments:"hike.io"
URL:http://hike.io
Name
Location
Distancemiles
Elev. GainElevation Gainfeet
Elev. MaxElevation Maxfeet
Lat. / Lng.
↧
Romanian Billionaire Saves OpenBSD | Bingo Blog
Comments:"Romanian Billionaire Saves OpenBSD | Bingo Blog"
URL:http://www.thedrinkingrecord.com/2014/01/19/romanian-billionaire-saves-openbsd/
The following link: http://www.osnews.com/story/27519/_OpenBSD_will_shut_down_if_we_do_not_have_the_funding_
Was dropped in the IRC Channel #bitcoin-assets and within hours an announcement was made:
mircea_popescu: and it pleases me to announce openbsd got itself sponsored.It is important to note that not only did this announcing happen on IRC, the important fact finding happened there as well, from the channel #openbsd:
Jan 19 22:14:04 <mircea_popescu> soo, who has the authority to make a deal so I can cover the 20k shortfall Jan 19 22:16:24 <woopstar> mircea_popescu: you need to contact Theo Jan 19 22:16:32 <mircea_popescu> how would i go about that ? Jan 19 22:18:27 <woopstar> mircea_popescu: i believe his email is [redacted because email addresses don't belong in plaintext] Jan 19 22:20:32 <mircea_popescu> woopstar ty. Jan 19 22:20:49 <woopstar> mircea_popescu: anytime. Would be fantastic, if you can set up a deal with TheoThis episode just goes to show that IRC even in the 2010's continues to be one of the most expressive, influential, and effective communications mediums on the Internet. It also shows for Open Source projects seeking sponsorships to continue their operations that the traditional channels by which they hope the Microsofts, Apples, and Oracles of the world that happily vacuum up their code may not be the there in their time of need, but if they are truly doing something that is both useful and interesting chances are someone out there might have the money and intelligence to appreciate your project enough to buy it at least another year.
I for one am happy that for at least another year the Vaxen will have an OS to run.
↧