↧
'OpenBSD Foundation Fundraising for 2014' - MARC
↧
51 Startup Failure Post-Mortems
Comments:"51 Startup Failure Post-Mortems"
URL:http://www.cbinsights.com/blog/trends/startup-failure-post-mortem
On his many failed experiments, Thomas Edison once said
I have learned fifty thousand ways it cannot be done and therefore I am fifty thousand times nearer the final successful experiment.And so while we have dug into the data behind startups that have died (as well as those acqui-hired) and found they usually die 20 months after raising financing and after having raised about $1.3 million, we thought it would be useful to see how startup founders and investors describe their failures. While not 50,000 ways it cannot be done, below is a compilation of 51 startup post-mortems that describe the factors that drove a startup’s demise. Most of the failures have been told by the company’s founders, but in a few cases, we did find a couple from investors including Roger Ehrenberg (now of IA Ventures) and Bruce Booth (Atlas Venture).
They are in no particular order, and there is something to learn from each and every one of them.
Title: 7 Lessons I’ve Learned From a Failed Startup
You Are MUCH More Resilient Than You Think Had someone told me I was going to work a night audit job, get 4 hours sleep a day, consult, and be part of a startup, I would have told them that they’re crazy. I knew I was resilient, but this really pushed me to the next level. NEVER underestimate your capabilities.Title: 7 Things I learned from Startup Failure
Company: Intellibank
Focus and simplicity are often more difficult to achieve than building features on top of features on top of features. As a result, too many startups are unfocused. The time required to trim back an idea is not insignificant — said best by Mark Twain: “If I had more time, I would have written a shorter letter.”Title: Startup Lessons Learned from My First Startup
Company: Teamometer
(Don’t) multiply big numbers Multiply $30 times 1.000 clients times 24 months. WOW, we will be rich! Oh, silly you, you have no idea how hard it is to get 1.000 clients paying anything monthly for 24 months. Here is my advice: get your first client. Then get your first 10. Then get more and more. Until you have your first 10 clients, you have proved nothing, only that you can multiply numbers.Title: A Postmortem Analysis of Standout Jobs
Company: Standout Jobs
I raised too much money, too early for Standout Jobs (~$1.8M). We didn’t have the validation needed to justify raising the money we did. Part of the reason for this is that the founding team couldn’t build an MVP on its own. That was a mistake. If the founding team can’t put out product on its own (or with a small amount of external help from freelancers) they shouldn’t be founding a startup. We could have brought on additional co-founders, who would have been compensated primarily with equity versus cash, but we didn’t.Title: Cusoy: A postmortem
Company: Cusoy
I didn’t want a startup, but an actual business that generates revenue, and Cusoy would not fulfill that personal goal for me without a full-time team, 1-2+ years of funding, multiple years of hard work (3-5+ years at the very least?) trying to answer the if/when questions of whether or not Cusoy could make money (very expensive questions too, might I add — not only in money but time, my most valuable asset). While I know there might be a possibility I could hustle incredibly hard and try to set up partnerships, the time investment required far outweighed the already incredibly slim chances of generating revenue.Title: Flowtab
Company: Flowtab
We hired a local operations manager in Denver (Sasha Juliard) and soon launched at Shotgun Willie’s (the highest-grossing strip club in CO) and two other bars. We made about $1,200 on each deal (50% went to DexOne, we spent $800 on each launch event and we had $500 in hardware costs), this was the only sales revenue Flowtab ever made. We were tightening up our sales process, but it was hard to market ourselves properly in those bars without being there. It quickly become a distraction to our operations in San Francisco.Title: Formspring – A Postmortem
Company: Formspring
Entrepreneurs: build your product, not someone else’s. The most successful products execute on a vision that aligns with their product’s and users’ goals. It’s hard to put blinders on when your stats are slowly coming down and you see other startups skyrocketing around you with various tactics and strategies. For the love of god, put them on. It’s the only way to build what you should instead of chasing others’ ideas.Title: Internet Startup: Lessons from Failure
Product: Mass-customized Jeans
We weren’t going to draw from the business until we had recouped our (parents’) initial investment. That meant continuing to operate 9-5 while earning an income at night, which was fine for the months leading up to launch, but totally unsustainable once orders started coming in.Title: Lessons from my failed startup
Company: Parceld
No one likes someone who is too aggressive, but looking back, my idea of “too aggressive” could probably fit very nicely into the “persistent” bucket, which, quite frankly, is not enough when raising money. My father told me that, especially as a woman, to never be afraid to ask for what I want or to remind others of their commitments. People these days are busy, forgetful and over-scheduled; it’s quite possible my three emails each got buried, so a fourth or fifth email (not daily, though; maybe weekly) would have served me well. I’ll never know.Title: Lessons from my failed startup
Company: Saaspire
If you’re bootstraping, cashflow is king. If you want to possibly build a product while your revenue is coming from other sources, you have to get those sources stable before you can focus on the product.Title: Looking back at 7 years with my startup GroupSpaces
Company: GroupSpaces
…we most definitely committed the all-too-common sin of premature scaling. Driven by the desire to hit significant numbers to prove the road for future fundraising and encouraged by our great initial traction in the student market, we embarked on significant work developing paid marketing channels and distribution channels that we could use to demonstrate scalable customer acquisition. This all fell flat due to our lack of product/market fit in the new markets, distracted significantly from product work to fix the fit (double fail) and cost a whole bunch of our runway.Title: My Startup Failed. F@<#.
Company: Zillionears.com
More importantly though, people really didn’t really LIKE anything about our product. No one that used the service thought it was that cool. In fact, some people that participated in the sale didn’t even like our “dynamic pricing” system. They were trying to support the artist, so saving a few dollars didn’t excite them. They could easily have just gotten his music for free elsewhere.Title: Out of the Picture: Why the world’s best photo startup is going out of business (Editorial)
Company: Everpix
The founders acknowledge they made mistakes along the way. They spent too much time on the product and not enough time on growth and distribution. The first pitch deck they put together for investors was mediocre. They began marketing too late. They failed to effectively position themselves against giants like Apple and Google, who offer fairly robust — and mostly free — Everpix alternatives. And while the product wasn’t particularly difficult to use, it did have a learning curve and required a commitment to entrust an unknown startup with your life’s memories — a hard sell that Everpix never got around to making much easier. Rimer put it a bit differently: “Having a great product is not the only thing that ultimately makes a company successful.”Title: Part Two of the HelloParking postmortem: a look back, and a new perspective
Company: HelloParking
But we never defined clear hypotheses, developed experiments, and we rarely had meaningful conversations with our target end-users. And while we had some wonderful advisors in the parking industry, we should have met with everyone we could get our hands on. Worst, we rarely got out of the building.Title: Play By Your Own Rules
Company: Gowalla
Unfortunately, once your key metric is tied to cash value in the eyes of investors, it sucks to be number two. Your ceiling has been bolted in place. Your future capacity to raise cash or sell has a lid on it now. We felt that in order to survive we had to get our numbers up. We tried just about everything to juice growth, some ideas being more successful than others.Title: Postmortem of a Venture-Backed Startup
Company: Sonar
We received conflicting advice from lots of smart people about which is more important. We focused on engagement, which we improved by orders of magnitude. No one cared. Lesson learned: Growth is the only thing that matters if you are building a social network. Period. Engagement is great but you aren’t even going to get the meeting unless your top-line numbers reach a certain threshold (which is different for seed vs. series A vs. selling advertising).Title: Postmortem of a Venture-Backed, Acquired Startup
Company: Decide.com
Decide how you want do things then hire people that want to do things that way. There’s value in having a diversity of opinion but in a early stage startups, the benefits (moving fast) of hiring people that generally agree with you outweigh the benefits (diversity of opinion) of hiring people that don’t. If you can’t hire anyone that agrees with you, re-evaluate how you want to do things.Title: Shnergle Post Mortem
Company: Shnergle
Does your idea only monetise at scale? If your idea can only be monetised at scale, head to San Francisco / Silicon Valley. There isn’t enough risk capital, or enough risk appetite, in the UK/EU venture market to pour capital into unproven R&D concepts. If you want to build in the UK, find some way of charging money from day one. You can still use a freemium structure to up-sell later. Shnergle was never going to monetise before it had scaled fairly significantly. Fail!Title: Tis the Season for a Tigerbow Post Mortem
Company: Tigerbow
Don’t raise money from people who don’t invest in startups. We raised a (comparatively) small amount of money from friends and family. For the most part they were very supportive, but there were exceptions. Aside from the fact that we got little (non-monetary) value added from these investors, people who are unfamiliar with investing in startups and the risks and challenges of building a company will drive you bananas. (Tempting, but don’t / duh.)Title: Travelllll Post-Mortem
Company: Travelllll.com
If your monetisation strategy is advertising, you need to be marketing to an enormous audience. It’s possible to make a little money from a lot of people, or a lot of money from a few people. Making a little money from a few people doesn’t add up. If you’re not selling something, you better have a LOT of eyeballs. We didn’t.Title: Vitoto Offically Shutting Down
Company: Vitoto
Product outside area of specialization: Nobody in the team had built a successful consumer product before. We all had experience in the enterprise space, selling to businesses. We had no experience in consumer of video. We were not playing to our strengths. Next time: Next time I will play in a space I have lived in before.Title: Why Startups Fail: A Postmortem For Flud, The Social Newsreader (Editorial)
Company: Flud
“We really didn’t test the initial product enough,” Ghoshal says. The team pulled the trigger on its initial launches without a significant beta period and without spending a lot of time running QA, scenario testing, task-based testing and the like. When v1.0 launched, glitches and bugs quickly began rearing their head (as they always do), making for delays and laggy user experiences aplenty — something we even mentioned in our early coverage. Not giving enough time to stress and load testing or leaving it until the last minute is something startups are known for — especially true of small teams — but it means things tend to get pretty tricky at scale, particularly if you start adding a user every four seconds.”Title: On-Q-ity, a Cancer Diagnostic Company: R.I.P. (A VC’s perspective)
Company: On-Q-ity
Getting the technology right, but the market-timing wrong, is still wrong, confirming cliche about the challenge of innovating… We may have been right that CTCs are “hot” and will be important in the future, but we certainly didn’t have enough capital around the table to fund the story until the market caught up. It will be great in 5-10 years to see CTCs evolve as a routine part of cancer care, though clearly bittersweet for those of us involved with On-Q-ity.Title: How My Startup Failed
Product: Condom Key Chains
There was no doubt about it: I had discovered The Next Big Thing. Like Edison and the lightbulb, like Gates and the pc operating system, I would launch a revolution that would transform society while bringing me wealth and fame. I was about to become the first person in America to sell condom key chains.Title: Why Wesabe Lost to Mint
Company: Wesabe
Between the worse data aggregation method and the much higher amount of work Wesabe made you do, it was far easier to have a good experience on Mint, and that good experience came far more quickly. Everything I’ve mentioned — not being dependent on a single source provider, preserving users’ privacy, helping users actually make positive change in their financial lives — all of those things are great, rational reasons to pursue what we pursued. But none of them matter if the product is harder to use, since most people simply won’t care enough or get enough benefit from long-term features if a shorter-term alternative is available.Title: ArsDigita – From Start-up to Bust-up
Company: ArsDigita
1. spent $20 million to get back to the same revenue that I had when I was CEO 2. declined Microsoft’s offer (summer 2000) to be the first enterprise software company with a .NET product (a Microsoft employee came back from a follow-up meeting with Allen and said “He reminds me of a lot of CEOs of companies that we’ve worked with… that have gone bankrupt.”) 3. deprecated the old feature-complete product (ACS 3.4) before finishing the new product (ACS 4.x); note that this is a well-known way to kill a company among people with software products experience; Informix self-destructed because people couldn’t figure out whether to run the old proven version 7 or the new fancy version 9 so they converted to Oracle instead)Title: RiotVine Post-Mortem
Company: RiotVine
It’s not about good ideas or bad ideas: it’s about ideas that make people talk. And this worked really well for foursquare thanks to the mayorship. If I tell someone I’m the mayor of a spot, I’m in an instant conversation: “What makes you the mayor?” “That’s lame, I’m there way more than you” “What do you get for being mayor?”. Compare that to talking about Gowalla: “I just swapped this sticker of a bike for a sticker of a six pack of beer! What? Yes, I am still a virgin”. See the difference? Make some aspect of your product easy and fun to talk about, and make it unique.Title: The Last AnNounce(r)ment
Company: Nouncer
A month ago, half way through my angel funds raised from family members, I decided to review the progress I’ve made and figure out what still needs to happen to make this a viable business. I was also actively pursuing raising VC funds with the help of a very talented and well connected friend. At the end, I asked myself what are the most critical resources I need to be successful and the answer was partners and developers. I’ve been looking for both for about a year and was unable to find the right people. I realized that money was not the issue.Title: BricaBox: Goodbye World!
Company: BricaBox
Go vest yourself. When a co-founder walks out of a company — as was the case for me — you’ve already been dealt a heavy blow. Don’t exacerbate the issue by needing to figure out how to deal with a large equity deadweight on your hands (investors won’t like that the #2 stakeholder is absent, even estranged, from your company). So, the best way of dealing with this issue is to take a long, long vesting period for all major sweat equity founders.Title: Boompa.com Launch Postmortem, Part 1: Research, Picking a Team, Office Space and Money
Company: Boompa.com
Ethan and I came up with the “Zombie Team” test for figuring out whether or not someone is ready to work on an intense project, be it a start-up or otherwise. The test is this: If zombies suddenly sprung from the earth, could you trust the perspective team member to cover your back? Would they tell you if they got bit? Most importantly would you give them the team’s only gun if you knew they were the better shot? If the answer is no to any of those questions you need to let them get eaten by the cubicle wasteland of corporate culture, because they aren’t ready for this kind of work.Title: EventVue Post-Mortem
Company:EventVue
Our Deadly Cultural Mistakes: · didn’t focus on learning & failing fast until it was too late · didn’t care/focus enough about discovering how to market eventvue · made compromises in early hiring decisions – choose expediency over talent/competency The market was not there. The thesis of our current business model (startups are all about testing theses) was that there was a need for video producers and content owners to make money from their videos, and that they could do that by charging their audience. We found both sides of that equation didn’t really work. I validated this in my conversations with companies with more market reach than us, that had tried similar products (ppv video platform), but pulled the plug because they didn’t see the demand for it. Video producers are afraid of charging for content, because they don’t think people will pay. And they’re largely right. Consumers still don’t like paying for stuff, period. We did find some specific industry verticals where the model works (some high schools, some boxing and mixed martial arts events, some exclusive conferences), but not enough to warrant a large market and an independent company. Second, as one of my friends observed, I talked to about 7 people (both acquaintances and friends) whose judgment I trusted. 3 of them sympathized and agreed with my decision and 4 of them admonished me and asked me to “hang in there.” You know what was the clincher? The first 3 had done startups themselves and the latter 4 had not. The latter 4 did not really understand the context, even though they meant well and are intelligent folks.Title: Lessons Learned
Company: Devver
The most significant drawback to a remote team is the administrative hassle. It’s a pain to manage payroll, unemployment, insurance, etc in one state. It’s a freaking nightmare to manage in three states (well, two states and a district), even though we paid a payroll service to take care of it. Apparently, once your startup gets larger, there are companies that will manage this with minimal hassle, but for a small team, it was a major annoyance and distraction.Title: Lessons from Kiko, web 2.0 startup, about Its Failure
Company: Kiko
Make an environment where you will be productive. Working from home can be convenient, but often times will be much less productive than a separate space. Also its a good idea to have separate spaces so you’ll have some work/life balance.Title: Lessons Learned: Startup Failure Part 1
Company: Overto
Thin line between life and death of internet service is a number of users. For the initial period of time the numbers were growing systematically. Then we hit the ceiling of what we could achieve effortlessly. It was a time to do some marketing. Unfortunately no one of us was skilled in that area. Even worse, no one had enough time to fill the gap.
The Seven Deadly Sins
While we certainly made more than seven mistakes during the nearly four-year life of Monitor110, I think these top the list.
1. The lack of a single, “the buck stops here” leader until too late in the game
2. No separation between the technology organization and the product organization
3. Too much PR, too early
4. Too much money
5. Not close enough to the customer
6. Slow to adapt to market reality
7. Disagreement on strategy both within the Company and with the Board
Title: Monitor110: A Post-Mortem (A VC’s perspective)
Company: Monitor110
Title: Why We Shut NewsTilt Down
Company: NewsTilt
None of these problems should have been unassailable, which leads us to why NewsLabs failed as a company:
· Nathan and I had major communication problems,
· we weren’t intrinsically motivated by news and journalism,
· making a new product required changes we could not make,
· our motivation to make a successful company got destroyed by all of the above.
For anyone faced with winding down a company, I’d highly recommend taking a while off before making any big decisions, and not just the two and a half weeks that I’d initially tried. You’re not thinking straight when your startup dies – your perspective may be a bit different in a few months, as might your preferences for what you want to do next.
The corollary to that is to wind up your startup before you’re totally out of money, so that you have options for what to do next and don’t have to bargain from a place of total weakness.
So the most important thing is to sell – a fact lots of startups forget. And we did too. After much thought it comes down to these six reasons why we failed (beside the obvious one that the VC market imploded when we needed money and noone was able to get any funding):
1. We didn’t sell anything
2. We didn’t sell anything
3. We didn’t sell anything
4. The market window was not yet open
5. We focused too much on technology
6. We had the wrong business model
Title: Aftermath
Company: Diffle
Title:10 Lessons from a Failed Startup
Company: PlayCafe
I would advise any entrepreneur or investor considering content to think twice, as Howard Lindzon from Wallstrip warned us. Content is an order of magnitude harder than technology with an order less upside; no YouTube producer will earn within a hundredth of $1.65 billion. This will only become more true as DVRs and media-sharing reduce revenues and pay-for-performance ads eliminate inefficient ad spend, of which there is a lot. The main and perhaps only reason to do content should be the love of creating it.
Title: Lessons from our Failed Startup
Company: SMSnoodle
I have been hearing this advise from the time I have been in my mother’s womb. Dont take this easily.If you are a techie there are more chances that you won’t follow this advise. Your heart doesn’t get satisfied with any levels of development.Ignore your heart. Listen to your brain. If you are a web startup , you can take max 6 months to release your first version( for something like mint.com) .Simpler websites shouldn’t take more than 2-3 months.You can always iterate and extrapolate later. Wet your feet asap.
Title: Untitled Partners Post-Mortem
Company: Untitled Partners
Hiring is hard, and without proper experience, we should have leaned more heavily on our investors to help us with this decision. Hiring was a challenge we found difficult throughout the life of our Company. We made as many bad decisions as we did good ones with regard to hiring full time, part time, and independent contractors/consultants. Biggest takeaway: As soon as the data starts to suggest someone might be the wrong hire, don’t wait, immediately start recruiting a replacement, and upgrade as soon as possible.
Title: Key Lessons from Cryptine Networks’ Failure
Company: Cryptine Networks
No matter how close of friends, how much you trust each other or how good your intentions are money comes between people and everyone over estimates their own contributions. Furthermore, founders become highly emotional about their companies. Thus, the process of negotiating taking back stock from founders is not rational and inherently very difficult. However, vesting schedules reduce the difficult negotiation to simply and mechanically exercising the companies pre-agreed right to repurchase stock at the price it was issued. I foolishly let myself fall into the “it won’t happen to me” trap but no startup gets it right on the first try and theses hiccups often lead to changes in the team. Believing that any startup won’t have to deal with stock vesting issues is totally unrealistic.
Title: Imercive Post-Mortem
Company: Imercive
For one, we stuck with the wrong strategy for too long. I think this was partly because it was hard to admit the idea wasn’t as good as I originally thought or that we couldn’t make it work. If we had been honest with ourselves earlier on we may have been able to pivot sooner and have enough capital left to properly execute the new strategy. I believe the biggest mistake I made as CEO of imercive was failing to pivot sooner.
Title: Meetro Post Mortem
Company: Meetro (aka Lefora)
We could have gone about trying to fix Meetro but the team was just ready to move on. Raising money on the flat growth we had was nearly impossible. Plus I knew that in order to keep the tight-knit team we had built together, we needed to shift focus for sanity sake. People (myself included) just felt beat up. We knew that fixing these issues would involve a complete rearchitecturing of the code, and people just weren’t excited about the idea enough anymore to do it right.
Title: Post Mortem on a Failed Product
Company: eCrowds
As the product became more and more complex, the performance degraded. In my mind, speed is a feature for all web apps so this was unacceptable, especially since it was used to run live, public websites. We spent hundreds of hours trying to speed of the app with little success. This taught me that we needed to having benchmarking tools incorporated into the development cycle from the beginning due to the nature of our product.
Title: Hubris, ambition and mismanagement: the first post-mortem of RealTime Worlds (Editorial)
Company: RealTime Worlds
Dave Jones made a virtue of having no business model for APB. He said “if a game is built around a business model, that’s a recipe for failure.”
Bullsh1t.
But the more we moved down the path, the more I realized the complexities involved with selling answers. Knowledge is a tricky thing to sell, because even experts disagree on some answers. What’s worse, most people think they know more than they really do. Look at how many idiots think they know stocks, or programming, or even business. Nearly everyone thinks they can give good management tips. It is difficult to sell something so… confusing, and we realized it would lead to problems down the road. Yahoo, and most of the other sites, fix this by having people vote on the best answer, but we couldn’t post answers in public because that would take away our residual incentives. And anyway, I’m not convinced in the “wisdom of crowds” for anything beyond general knowledge. It doesn’t work for domain specific stuff.
Title: Co-Founder Potts Shares Lessons Learned from Backfence Bust
Company: Backfence
Hyper-local is really hard. Don’t kid yourself. You don’t just open the doors and hit critical mass. We knew that from the jump. It takes a lot of work to build a community. Look carefully at most hyper-local sites and see just how much posting is really being done, especially by members of the community as opposed to be the sites’ operators. Anybody who’s run a hyper-local site will tell you that it takes a couple of years just to get to a point where you’ve truly got a vibrant online community. It takes even longer to turn that into a viable business. Unfortunately, for a variety of reasons, Backfence was unable to sustain itself long enough to reach that point.Title: What an Entrepreneur Learned from His Failed Startup (Interview)
Company: Sedna Wireless
Finances were just one part of the story. The other part was that we failed to execute our own plans. Both external factors (e.g. the hardware ecosystem in India) and internal reasons (e.g. the expertise of the team) played a role. With money it would have lasted a bit more longer.Title: Couldery Shouldery
Company: Lookery
We exposed ourselves to a huge single point of failure called Facebook. I’ve ranted for years about how bad an idea it is for startups to be mobile-carrier dependent. In retrospect, there is no difference between Verizon Wireless and Facebook in this context. To succeed in that kind of environment requires any number of resources. One of them is clearly significant outside financing, which we’d explicitly chosen to do without. We could have and should have used the proceeds of the convertible note to get out from under Facebook’s thumb rather to invest further in the Facebook Platform.Data related to this research
An Excel list of all early-stage tech companies who appear to be running out of cash
Powered by 
↧
↧
Tijuana Airport Parking, Just Over the Border
↧
@pmarca Tweets as Blog Posts
Comments:"@pmarca Tweets as Blog Posts"
URL:http://pmarcatweetsasblogposts.tumblr.com
I’m utterly confused why this is even a little bit surprising (“N.S.A. Devises Radio Pathway Into Computers”). ”How the N.S.A. Uses Radio Frequencies to Penetrate Computers” is utterly misleading. It’s a hardware BUG that then transmits radio waves. Haven’t intelligence agencies had hardware BUGS that have MICROPHONES that pick up VOICES and “transmit over radio frequency” for 60 years?
Wouldn’t we be shocked and dismayed if the NSA wasn’t doing this? What did people think all those billions of dollars of funding were for? I increasingly feel like we’re all on some gigantic collective fainting couch. Oh my WORD I can’t believe that spy agencies SPY.
Everyone I talked to in 2002: “I can’t BELIEVE that the intelligence agencies didn’t ‘connect the dots’ to catch the hijackers before 9/11.” Everyone I talked to in 2013: “I can’t BELIEVE that the intelligence agencies are collecting and correlating all this information!” If I worked for the NSA, I’d be so confused right now. #1, catch the bad guys. #2, don’t spy. OK, now you go figure it out.
Excellent engagement in replies! Just to say a few things clearly:
I’m not saying I’m in favor of (or opposed to) any specific level of spying or targets of spying or oversight of spying. I am saying that I have yet to see one Snowden revelation that wasn’t obvious to people who had read existing books + articles + history. I am also saying that US intelligence agencies have been funded in our US collective names for huge $ ($75B annually now) for decades. I am therefore saying that shock and outrage that spying is happening is odd; for all that money, what did we think was happening? In fact, how big would the scandal be if all that money was being spent and all those people employed and the spying wasn’t happening? Further, in terms of Merkel et al, isn’t it obvious that all governments have all spied on all other gov’t’s both now and for 1000s of yrs? Does anyone really think that each European country isn’t spying on the US as well as all other European leaders? And finally, isn’t there a real discussion to be had that’s not flash-point “NSA is evil” cartoonish like so much of the current commentary?OH! Also, filling in some history, lest people think I am reflexively pro-NSA and anti-privacy: My colleagues and I at Netscape cut the first deal with RSA to bring crypto to the web, and first built crypto into web browsers/servers. A little later, we were on the front lines in the battle to legalize export of strong crypto globally, versus… the NSA. We also created SSL and HTTPS and catalyzed their standardization — so if you like your web crypto, that’s where it all came from :-).
A few closing thoughts for the moment on NSA topics…
Think there are some very legitimate, very real, very complex issues to be discussed, such as controls on surveillance of American citizens. Very much respect people engaging on these complex issues from all sides. But generally, too much rush to judgment, too much simplification, and false cartoon version of “NSA is evil” — not appropriate or helpful. In US, we all collectively hired tens of thousands of our fellow citizens & gave them $75B/year budget with a mission to spy on our behalf. To suddenly turn on them and blanket accuse them of comprehensive illegality and moral horrors is unfair to them, and lets us off the hook. Citizens of every other democratic country all have their own version of this exact same question. And shouldn’t fool themselves about it.
Time for introspection, careful examination of facts, cautious judgment, deep thinking, and prudent reform.
↧
FBI files on Richard Feynman | Muckrock
Comments:" FBI files on Richard Feynman | Muckrock"
FBI files on Richard Feynman
Requested by morisy on March 12, 2012 for the Federal Bureau of Investigation of United States of America and fufilled on March 21, 2012
Status: Completed
From Michael Morisy on March 12, 2012:
To Whom It May Concern:
This is a request under the Freedom of Information Act. I hereby request the following records:
A copy of any FBI files on Richard Feynman (May 11, 1918–February 15, 1988), a noted American physicist. His death has been widely reported.
I also request that, if appropriate, fees be waived as I believe this request is in the public interest. The requested documents will be made available to the general public free of charge as part of the public information service at MuckRock.com, processed by a representative of the news media/press and is made in the process of news gathering and not for commercial usage.
In the event that fees cannot be waived, I would be grateful if you would inform me of the total charges in advance of fulfilling my request. I would prefer the request filled electronically, by e-mail attachment if available or CD-ROM if not.
Thank you in advance for your anticipated cooperation in this matter. I look forward to receiving your response to this request within 20 business days, as the statute requires.
Sincerely,
Michael Morisy
From "Sobonya, David P." <David.Sobonya@ic.fbi.gov> to Michael Morisy on March 12, 2012:
Dear Mr. Morisy,
The FBI has received your Freedom of Information Act/Privacy (FOI/PA) request and it will be forwarded to the Work Process Unit or a Single Station Disclosure Team for review. Your request will be processed under the provisions of FOI/PA and a response will be mailed to you at a later date.
Requests for fee waivers and expedited processing will be addressed once your request has been assigned an FOI/PA request number. You will receive written notification of the FBI’s decision.
Information regarding the Freedom of Information Act/Privacy is available at http://www.fbi.gov/ or http://www.fbi.gov/foia/. Upon receipt of an FOI/PA Request Number, you can check the status of your request online at: http://www.fbi.gov/foia/, and by clicking on the ‘Check Status of Your FOI/PA Request’ link under the (Records Available Now) section. If you require additional assistance please contact the Public Information Officer.
Thank you,
↧
↧
career development - How do I keep the passion and energy up after 17 years of writing software? - The Workplace Stack Exchange
While I lack the many years of life experience you have, I can certainly relate to the feeling of losing passion for "my main trade". As far as I know, the most solid remedy is to simply do something else for a while. This will:
- Break up the tedium and give your mind some breathing room to rest from 17 years of focus.
- Teach you to better appreciate the nice things about web programming. For example, straightforward distribution to users, far fewer headaches in supporting legacy users, relative independence from user system unlike desktop applications. After a while, you may start to miss the job you are now disinterested in.
- Remind you that if you're so sick of web programming that you have to give it up and find another career, it's not the end of the world, because hey, it's not like you can't do this other thing, too.
- Gain you a new, valuable skill that will improve your marketability and broaden the spectrum of projects you can readily attempt.
Often, when you do something you love for many years, and then one day start feeling like you're sick of it and never want to touch it again, you're not really sick of it, and you don't really never want to touch it again - you just want a break. I am reminded of a short bit from Jonathan Haidt's The Happiness Hypothesis where he talks about surgeons who go on vacation to Haiti to escape the stress of their jobs, only to start volunteering at the local hospital after a few days out of sheer boredom.
As for what exactly you will do, it really depends on your personal circumstance and preference. You can try:
- Things related to your job: Server-client software, web scrapers, network administration, browser games.
- Things vaguely related to your job: Developing software that has little to do with the web, contributing to open source projects, (desktop) game development, solving computer science exercises from a textbook or the Euler Project, trying your hand at an AI project.
- Things completely unrelated to your job: Start an exercise routine, volunteer for a local charity, learn a language, get into a new sport, learn to play an instrument, join a local dancing class, start working on your long backlog of books or films, make a garden if you have a yard, try to do some DIY home maintenance.
It really doesn't matter what you do, so long as it interests you and and feels appropriately challenging (you don't want something effortless, but you also don't want something hopelessly difficult). It doesn't even matter if you ever get good at it - it's a hobby; being good is not the point. In fact, it is crucial to not get carried away and start stressing out over how much better some other people are at it. You're not competing with them.
It is preferable to pick something that is productive rather than a complete waste of time. However, it's not necessary: Once again, your objective isn't to become the master of your hobby, but to give yourself a break from work. Moreover, often it's impossible to predict what skills will come in handy one day. The rule of thumb is that if you're learning anything at all, or progressing in some fashion, you're doing fine.
If you don't have the luxury of taking a break form work entirely, such as a vacation, then the occasional evening or some time on the weekends will work just fine. If you are so overloaded with other pursuits that you have absolutely no time left over for a hobby, this is probably part of your problem.
Lastly, in the event that nothing excites your attention, consider that you may be depressed. Then, the issue is not with your job, but with you. If you are, indeed, depressed, chances are that there is no worthwhile activity that will be interesting to you. Such is the nature of depression. Regarding this possibility, you should really seek professional help (or at least research the topic from reputable sources). However, be wary of hypochondria and self-diagnosis - don't make trips to the therapist your hobby!
↧
Tesla Motors’ Over-the-Air Repairs Are the Way Forward | MIT Technology Review
Comments:"Tesla Motors’ Over-the-Air Repairs Are the Way Forward | MIT Technology Review"
URL:http://www.technologyreview.com/view/523621/tesla-motors-over-the-air-repairs-are-the-way-forward/
Tesla Motors is using over-the-air software updates to quickly fix the sort of problems that often arise when bringing a new car to market. This forward-looking approach is an important part of the company’s success (see “How Tesla is Driving Electric Car Innovation”).
Today the National Highway Safety Administration officially published two recall announcements, one from Tesla Motors and one from GM. Both are related to problems that could cause fires. In the case of GM, trucks left idling can overheat and catch fire—eight fires have been reported. In Tesla’s case, an overheating charger plug seems have to have been the cause of a fire in a garage (it’s not clear if the problem had to do with miswiring of the wall charger, damage to the plug, or something else).
Both problems can be addressed with software updates–in Tesla’s case, the software detects charging problems and decreases charging rates to avoid overheating (GM hasn’t provided details). Owners of 370,000 Chevrolet Silverado and GMC Sierra pickups will need to find time to take their pickups to the dealer to get the software fixed. But because of its ability to send software updates to its vehicles wirelessly, the 29,222 Tesla Model S electric cars that were affected have already been fixed. (While Tesla says the software update addresses the issue, it is also mailing Tesla owners new charger plugs that have a thermal fuse designed to provide another layer of safety.)
Indeed, Tesla’s CEO Elon Musk argues the fix shouldn’t be called a recall at all, although it technically is from the point of view of NHTSA. On Twitter he noted that no vehicles were being “physically recalled” and said, in light of the over-the-air software updates, “The word ‘recall’ needs to be recalled.”
This isn’t the first time Tesla has taken advantage of its software update system—it has become common for Tesla to send out updates that address problems and enhance performance. One of the most notable examples happened last year after three Tesla Model S’s caught fire in collisions, two with objects in the road. Tesla sent out an update that changed the suspension settings, giving the car more clearance at high speeds. No further fires have been reported, although it’s difficult to know if that’s because of the update (see “Are Electric Vehicles a Fire Hazard?” and “Why Electric Cars Could be Safer Than Gasoline Powered Ones”).
Of course, some problems can’t be fixed with software updates. A manufacturing defect on 1,098 Model S’s last year required a trip to the service station to repair a problem with the way seats were attached.
Expect over-the-air updates to become more common, although companies will need to work to make sure they can be done securely. Not only are they more convenient, they can also improve safety, since the updates can be made right away. And the updates may be critical for Tesla’s success, not just by giving the ability to respond to big issues like fires, but also to small ones—annoying but not dangerous software bugs—that could give the car a bad name if they persisted or were difficult for owners to have fixed. For example, Tesla was able to update the car’s estimates for how far it could go in cold weather (the use of a heater decreases battery range), avoiding a problem where the car underestimated how far it could go. In the future, software updates could make such predictions even more accurate by figuring in weather forecasts.
↧
User Onboarding | A frequently-updated compendium of web app first-run experiences
↧
Dogecoin and the Appeal of Small Numbers | Diego Basch's Blog
Comments:"Dogecoin and the Appeal of Small Numbers | Diego Basch's Blog"
URL:http://diegobasch.com/dogecoin-and-the-appeal-of-small-numbers
Dogecoin is a unique phenomenon in the fascinating world of cryptocurrencies. It’s barely six weeks old, and as I write this post its network has more computing power than any other cryptocurrency except for Bitcoin. It made headlines this weekend when its community raised enough money to send the Jamaican bobsled team to the Sochi Winter Olympics.
From a technical standpoint, Dogecoin is essentially a branded clone of Litecoin (the second cryptocurrency in terms of total market value). Without a doubt one of the most important factors contributing to Dogecoin’s popularity is its community. The Dogecoin subreddit has almost 40k users right now. The front page usually has a good mix of humor, good will, finance, and technology. Check it out if you haven’t already.
There’s another more subtle factor that I believe plays in Dogecoin’s favor: its tiny value. One DOGE is worth about $0.0015 right now. In other words, one dollar buys you about 600-700 DOGE. Contrast that with Bitcoin: $1 is about 0.001 BTC. This puts Bitcoin and Dogecoin in two completely different mental buckets for most people. One BTC is comparable to an ounce of gold. The press reinforces this idea, and many people view Bitcoin as a digital store of value. The daily transaction volume of BTC is about 0.2 percent of the total bitcoins in existence, which means that BTC does not circulate very much yet.
Contrast this with Dogecoin, for which the daily transaction volume is close to 15%. Where does that money go? Perhaps the most common usage of DOGE is to give online tips. Compare the activity of Reddit’s bitcointip and dogetipbot, and you’ll see the latter is much more active. What would you prefer as a tip, 100 DOGE or 0.000002 BTC? Both are almost meaningless in terms of monetary value, but receiving 100 units of a coin does feel better. It’s also easier to give tips; you don’t have to think much about tipping someone 10, 25 or 100 DOGE. With BTC you either have to choose a dollar amount, or be very careful with the number of zeroes.
The reason a DOGE is worth so little is the total supply of coins. The Bitcoin software has an embedded constant called MAX_MONEY. For Bitcoin it’s set to 21 million, which means that if Bitcoin takes over as a world currency it will be impossible for most people to ever own one. Litecoin is only slightly better, at 84 million. For DOGE, it’s one hundred billion (perhaps more, yet to be decided). This makes it unlikely that one DOGE will be worth $1 any time soon (or ever). It’s easy and fun to exchange $20 for 10k DOGE and give a fraction of them to strangers on the internet. Anyone can still mine hundreds of dogecoins per day with a desktop computer, and not feel very attached to them. Being a “slumdoge millionaire” is still affordable to many.
In a world where people get a kick out of likes or retweets, Dogetips take it up a notch. A Dogetip is an upvote that you can use, internet karma points that are actually worth something. So fun, very value.
Image credit: /u/binxalot, this person deserves tips. Of course I accept them too ![]()
DHpZsQCDKq9WbqyqfetMcGq87pFZfkwLBh
↧
↧
How I “hacked” Kayak and booked a cheaper flight | Jose Casanova's Blog
Comments:"How I “hacked” Kayak and booked a cheaper flight | Jose Casanova's Blog"
URL:http://www.josecasanova.com/blog/how-i-hacked-kayak-and-booked-a-cheaper-flight/
Let me start this out by saying I didn’t “hack” something in the black hat Hackers way, but by finding a market inefficiency and leveraging it to my advantage. It must be the day trader in me. No harm was done to any computers or systems in the making of this post.
TL;DR: I booked a flight through Kayak using a VPN and saved ~$100.
Long version: I was looking for flights to New Orleans when I realized that the flight price I checked yesterday was ~$100 cheaper. I started to think why the price went up so much in one day and tried checking the flight again using only Google Incognito but there was no price budge. Maybe my VPN had something to do with it? The night before I was using a VPN (I use BTGuard btw) and Kayak thought I was from Toronto, Canada. I guess if you are not from the departure city then flights are cheaper?
So what did I do?
So I had originally went to Kayak today and checked flights from Miami to New Orleans (Mardi Gras, w00t!). This was done without a VPN but using Google’s Incognito feature. Take a look at how much the flights were:

Flights to New Orleans from Miami (Non-VPN)
Also, check out where my IP was saying that I was from:

This is my “real” IP, no VPN
I thought this was strange since the night before I had checked flights and they were ~$100 cheaper. I realized I was logged into my VPN and thought it might have to do with that (BTW, I use the VPN to mask my internet traffic… sorry NSA). So what did I do? Tried checking again while being logged into my VPN!
This is me being logged into my VPN:

VPN FTW!
And here is where my IP is saying that I am from:

Canada, eh?
So I tried Kayak again, while being “shown” as being from Canada and this is what I got:

Check out the Canadian flag at the top right
That is about a ~$70+ price difference (I don’t think that included taxes)! Also, when I had checked earlier, that $345 flight wasn’t there… so it was a +$100 difference. When I went to book my flight my checkout total was in EUROS! The thing is, it wasn’t 380 euros, but 207 euros! That converts to about $280 USD.

Euros wuddup
Moral of the story? Try booking your flights through a VPN, maybe you’ll save a few bucks….. even if you pay in euros.
PS: I checked my online bank statement and I paid $281.60 total!
PSS: The flight is now over $400 on a non-VPN via Kayak + Google Incognito.
↧
Facebook will lose 80% of users by 2017, say Princeton researchers | Technology | The Guardian
Comments:" Facebook will lose 80% of users by 2017, say Princeton researchers | Technology | The Guardian "
URL:http://www.theguardian.com/technology/2014/jan/22/facebook-princeton-researchers-infectious-disease
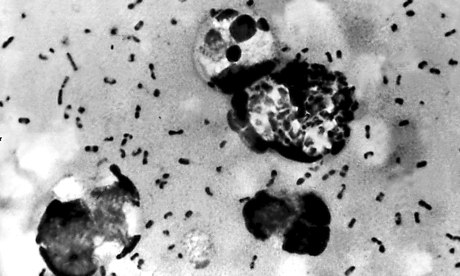
Bubonic plague bacteria. Scientists argue that, like bubonic plague, Facebook will eventually die out. Photograph: AFP/Getty Images
Facebook has spread like an infectious disease but we are slowly becoming immune to its attractions, and the platform will be largely abandoned by 2017, say researchers at Princeton University.
The forecast of Facebook's impending doom was made by comparing the growth curve of epidemics to those of online social networks. Scientists argue that, like bubonic plague, Facebook will eventually die out.
The social network, which celebrates its 10th birthday on 4 February, has survived longer than rivals such as Myspace and Bebo, but the Princeton forecast says it will lose 80% of its peak user base within the next three years.
John Cannarella and Joshua Spechler, from the US university's mechanical and aerospace engineering department, have based their prediction on the number of times Facebook is typed into Google as a search term. The charts produced by the Google Trends service show Facebook searches peaked in December 2012 and have since begun to trail off.
"Ideas, like diseases, have been shown to spread infectiously between people before eventually dying out, and have been successfully described with epidemiological models," the authors claim in a paper entitled Epidemiological modelling of online social network dynamics.
"Ideas are spread through communicative contact between different people who share ideas with each other. Idea manifesters ultimately lose interest with the idea and no longer manifest the idea, which can be thought of as the gain of 'immunity' to the idea."
Facebook reported nearly 1.2 billion monthly active users in October, and is due to update investors on its traffic numbers at the end of the month. While desktop traffic to its websites has indeed been falling, this is at least in part due to the fact that many people now only access the network via their mobile phones.
For their study, Cannarella and Spechler used what is known as the SIR (susceptible, infected, recovered) model of disease, which creates equations to map the spread and recovery of epidemics.
They tested various equations against the lifespan of Myspace, before applying them to Facebook. Myspace was founded in 2003 and reached its peak in 2007 with 300 million registered users, before falling out of use by 2011. Purchased by Rupert Murdoch's News Corp for $580m, Myspace signed a $900m deal with Google in 2006 to sell its advertising space and was at one point valued at $12bn. It was eventually sold by News Corp for just $35m.
The 870 million people using Facebook via their smartphones each month could explain the drop in Google searches – those looking to log on are no longer doing so by typing the word Facebook into Google.
But Facebook's chief financial officer David Ebersman admitted on an earnings call with analysts that during the previous three months: "We did see a decrease in daily users, specifically among younger teens."
Investors do not appear to be heading for the exit just yet. Facebook's share price reached record highs this month, valuing founder Mark Zuckerberg's company at $142bn.
Facebook billionaire
When Facebook shares hit their peak in New York this week, it meant Sheryl Sandberg's personal fortune ticked over $1bn (£600m), making her one of the youngest female billionaires in the world.
According to Bloomberg, the 44-year-old chief operating officer of the social network owns about 12.3m shares in the company, which closed at $58.51 (£35) on Tuesday in New York, although they fell back below $58 on Wednesday. Her stake is valued at about $750m.
Her fortune has risen rapidly since last August, when she sold $91m of shares and was estimated to be worth $400m.
Sandberg has collected more than $300m from selling shares since the company's 2012 initial public offering, and owns about 4.7m stock options that began vesting last May.
"She was brought in to figure out how to make money," David Kirkpatrick, author of The Facebook Effect, a history of the company, told Bloomberg. "It's proving to be one of the greatest stories in business history."
Sandberg's rise in wealth mirrors her broadening role on the global stage. The Harvard University graduate and one-time chief of staff for former Treasury secretary Lawrence Summers is a donor to President Barack Obama, sits on the board of Walt Disney Co, and wrote the book Lean In. She will be discussing gender issues with IMF boss Christine Lagarde at Davos on Saturday.
↧
Chrome Bugs Lets Sites Listen to Your Private Conversations
Comments:"Chrome Bugs Lets Sites Listen to Your Private Conversations"
URL:http://talater.com/chrome-is-listening/
While we’ve all grown accustomed to chatting with Siri, talking to our cars, and soon maybe even asking our glasses for directions, talking to our computers still feels weird. But now, Google is putting their full weight behind changing this. There’s no clearer evidence to this, than visiting Google.com, and seeing a speech recognition button right there inside Google’s most sacred real estate - the search box.
Yet all this effort may now be compromised by a new exploit which lets malicious sites turn Google Chrome into a listening device, one that can record anything said in your office or your home, as long as Chrome is still running.
Check out the video, to see the exploit in action
Google’s Response
I discovered this exploit while working on annyang, a popular JavaScript Speech Recognition library. My work has allowed me the insight to find multiple bugs in Chrome, and to come up with this exploit which combines all of them together.
Wanting speech recognition to succeed, I of course decided to do the right thing…
I reported this exploit to Google’s security team in private on September 13. By September 19, their engineers have identified the bugs and suggested fixes. On September 24, a patch which fixes the exploit was ready, and three days later my find was nominated for Chromium’s Reward Panel (where prizes can go as high as $30,000.)
Google’s engineers, who’ve proven themselves to be just as talented as I imagined, were able to identify the problem and fix it in less than 2 weeks from my initial report.
I was ecstatic. The system works.
But then time passed, and the fix didn’t make it to users’ desktops. A month and a half later, I asked the team why the fix wasn’t released. Their answer was that there was an ongoing discussion within the Standards group, to agree on the correct behaviour - “Nothing is decided yet.”
As of today, almost four months after learning about this issue, Google is still waiting for the Standards group to agree on the best course of action, and your browser is still vulnerable.
By the way, the web’s standards organization, the W3C, has already defined the correct behaviour which would’ve prevented this… This was done in their specification for the Web Speech API, back in October 2012.
How Does it Work?
A user visits a site, that uses speech recognition to offer some cool new functionality. The site asks the user for permission to use his mic, the user accepts, and can now control the site with his voice. Chrome shows a clear indication in the browser that speech recognition is on, and once the user turns it off, or leaves that site, Chrome stops listening. So far, so good.
But what if that site is run by someone with malicious intentions?
Most sites using Speech Recognition, choose to use secure HTTPS connections. This doesn’t mean the site is safe, just that the owner bought a $5 security certificate. When you grant an HTTPS site permission to use your mic, Chrome will remember your choice, and allow the site to start listening in the future, without asking for permission again. This is perfectly fine, as long as Chrome gives you clear indication that you are being listened to, and that the site can’t start listening to you in background windows that are hidden to you.
When you click the button to start or stop the speech recognition on the site, what you won’t notice is that the site may have also opened another hidden popunder window. This window can wait until the main site is closed, and then start listening in without asking for permission. This can be done in a window that you never saw, never interacted with, and probably didn’t even know was there.
To make matters worse, even if you do notice that window (which can be disguised as a common banner), Chrome does not show any visual indication that Speech Recognition is turned on in such windows - only in regular Chrome tabs.
You can see the full source code for this exploit on GitHub.
Speech Recognition's Future
Speech recognition has huge potential for launching the web forward. Developers are creating amazing things, making sites better, easier to use, friendlier for people with disabilities, and just plain cool…
As the maintainer of a popular speech recognition library, it may seem that I shot myself in the foot by exposing this. But I have no doubt that by exposing this, we can ensure that these issues will be resolved soon, and we can all go back to feeling very silly talking to our computers… A year from now, it will feel as natural as any of the other wonders of this age.
↧
Should App.net accept Bitcoin?
Comments:"Should App.net accept Bitcoin?"
How can I pay for my App.net account with bitcoins?
We're testing the market to see if enough people are willing to commit to paying for App.net using bitcoins. What you can do today is commit to paying for a year of a premium subscription via a Bitcoin transaction. If enough people commit with you, we'll credit your account for a year of service. If not, we'll send back the amount you committed to a wallet of your choice.
Click on the "Pay Now" button below the account plan of your choice. If you don't already have an App.net account, you'll first sign up for a free account. You'll then be prompted to complete a Bitcoin payment to App.net. It's easy to pay with any Bitcoin wallet. If you don't have a wallet yet, you can sign up for free Coinbase account.
Why is this priced in BTC?
We've approximated our existing USD pricing in BTC, but rather than pegging the price to USD, we've decided to price Bitcoin-funded subscriptions in BTC. As the market price of BTC fluctuates, we'll likely make adjustments to the pricing. When your subscription is up, we'll offer you a current price for renewal.
When will my account be upgraded to paid?
If our fundraising goal is met, we'll upgrade your account to the appropriate premium tier as soon as possible. It may take us about a week to get your account upgraded or credited for the appropriate amount of time. We'll send you an email as soon as your account is upgraded. After the first goal is met, we'll work on making upgrades take effect immediately as quickly as possible.
What if I already have a paid App.net account?
We're happy to transition your account to be funded via Bitcoin if we meet our goal. We'll extend your existing subscription without you losing any of your existing time.
How will my account renew?
When your paid subscription is up, we'll send you an email reminding you to renew your subscription by completing the purchase flow again.
Why aren't you using m-of-n transactions?
The payment processor we're using for this experiment doesn't yet support complex transactions. That said, the promise of limited-trust crowdfunding is appealing, and those of us behind the scenes are really interested in trying out "interesting" transaction types. If you want to try one by hand, we're game. The best way to get started is to sign up for a free account and create a post mentioning @berg. He'll get back to you on the service or via email and we'll try it out.
Can I verify your progress via the blockchain?
We're using Coinbase as our processor, and some of their transactions take place off-blockchain. When we receive payments from non-Coinbase wallets, the destination is a unique (or recycled) address, which we use to associate your payment with your account.
What if the funding isn't successful?
If we don't reach our fundraising goal, we'll return the amount that you paid to a wallet of your choice. We'll send an email to the address you have registered and will prompt you to enter a wallet address. If you don't respond to our email within 30 days, or you otherwise elect to, we'll donate your payment to a charity of our choice.
I'm a journalist or potential business partner. How do I get in touch?
Please send an email to inquiries@app.net.
Have a question that wasn't answered?
If the information above doesn't answer your question, you can ask us directly by sending an email to support@app.net.
↧
↧
Stripe CTF3: Distributed Systems
Comments:"Stripe CTF3: Distributed Systems"
URL:https://stripe.com/blog/ctf3-launch
 Greg Brockman, January 22, 2014
Greg Brockman, January 22, 2014
We’re proud to launch Capture the Flag 3: Distributed Systems. Without further ado, you can now jump in and start playing. If you complete all the levels, we'll send you a special-edition Stripe CTF3 T-shirt.
For those seeking further ado: we’ve found that the best way to teach people to build good systems is by giving them hands-on experience with problems that even expert developers may only occasionally get the chance to solve. We’ve run twoprevious Capture the Flags, both of which were designed to be an interesting way to get hands-on experience with crafting vulnerabilities.
Problems that follow this pattern—interesting, educational, rarely encountered—occur in many places outside security though, and we've made Capture the Flag 3 focus on distributed systems. There are five levels, each one focused on a different problem in the field. In all cases, the problem is one you’ve likely read about many times but never had a chance to try out in practice.
If you’d like to see how others are doing, we have leaderboards (for those who’ve opted in). You can also create a leaderboard for your group or company if you’d like to compete against your friends. We have CTF community chat on IRC at irc://irc.stripe.com:+6697/#ctf (also available via our web client). If you'd rather use Twitter than IRC,#stripectf is the hashtag for the event.
Above all, we want you to have fun and hopefully learn something in the process. If you get lost, we’ve provided beginners’ guides for each level which should point you in the right direction.
CTF3 will run for a week (so until 11am Pacific on January 29th). Happy hacking!
↧
Connecting to the Internet – Finding My 15-Year-Old Website I Built at 16 | Random Drake
Comments:"Connecting to the Internet – Finding My 15-Year-Old Website I Built at 16 | Random Drake"
I stumbled across a website I created 15 years ago, still online. Clicking through the pages brought me back to a very different and beautiful time of the Internet. 1999 was a time where you connected to the Internet to gain access to other things. These days, the Internet is always available, always on, and always connected.
Read on to learn about a time before “The Internet” was synonymous with Facebook, search engines, web pages, chatting, photos, and the phone in your pocket. A time when you had to connect to the Internet.
Technology of 1999
To give you an idea of how people were connecting to the Internet in 1999, here are the numbers for you from a 2000 FCC report, quoted here:
Dial-up, for those of you not familiar, was a connection through a modem over regular phone lines, popular in 3 speeds at that time. 28.8, 33.6 and 56k. Those are in kbps, so for download speeds you’re talking maximums of: 3.6 KB/s, 4.2KB/s, and 7 KB/s respectively. These speeds were rarely, if ever, achieved. Putting that into into perspective: we used to plan on downloading a single song, that’s 1 MP3, over the course of many hours, if not days. Downloading an entire album, as file-sharing was gaining popularity during these times, meant multiple days worth of connecting, re-downloading, and retrying.
The population of the United States was 272,690,813 in 1999. Having roughly 62,186,000 Internet users in 1999, that means only 22.8% of the United States was using the Internet at the time. Compare that to the latest census report stating that 71% of homes have Internet usage.
Most people still connected to the Internet on a dial-up modem and the connection offerings were becoming dominated by free access providers. We were growing from an AOL-dominated marketplace. NetZero had been released the year before, offering the first nationwide free Internet access. They gained 1,000,000 subscribers in just 6 months. 1999 brought competition like Juno Web and others. Free Internet was available as long as you didn’t mind highly targeted advertising throughout the experience. There were plenty of hacks available to get around the advertisements, but the majority of users dealt with them.
“Don’t pick up the phone!”Lost cry of the earlier generation of Internet users.Deciding on a 56k Standard
The two big sides of the 56k fight had finally come to an agreement and the v.90 standard was born. Previously, you had to pick an Internet Service provider that was compatible with the technology of your modem if you wanted 56k speeds. No more deciding whether you wanted to connect to the Internet as Rockwell / Lucent saw fit with K56flex, or with USRobotics’ X2 technology. Cable Internet was on the rise. RoadRunner was dominating broadband cable access and would be swept up by AT&T the next year in their acquisition of MediaOne. Broadcom, one of the main chipset makers enabling the high speed revolution saw $518,000,000 in revenue for 1999; 12 times what they saw just two years prior.
Instant Messaging
Instant messaging had become an accepted and widespread technology. 1998 saw America Online acquire ICQ‘s user base of 35,000,000 registered users. Microsoft released their own version of instant messaging, MSN Messenger Service, in 1999, attempting to push against America Online’s proprietary technology by touting the IETF standards. This was a massive and odd shift to see from Microsoft who had just a few years prior been in hot water with their Netscape VS Internet Explorer browser wars. During this time, Microsoft refused to let another internet browser interact well with their operating system. Eventually, Microsoft would open an API to allow access to the Netscape folks and Netscape was then picked up by AOL.
Needless to say, drama in and amongst technology companies is not anything new.Gaming in 1999
Gamers on the Internet were classified by the technology and speed they had available to them. You were either a high ping bastard (HPB) or a low ping bastard (LPB). Most folks were still on dial-up connections. They were happy with ping times having latencies in the 2-300 range. Heck, 400 was okay as long it was a stable 400. Meanwhile, the exceedingly lucky users sitting on connections that were incredibly fast for the time getting ping times of 100 or less. These types of connections could only be found in places like: Internet cafes, in colleges on unregulated Internet pipes, or employees in places like ISPs or technological or scientific organizations. There, you would undoubtedly find fellow nerds laughingly scoring a head shot with ease, leaving the HPBs wondering what happened.
The end of 1998 brought about the revolutionary Half-Life video game. Counter-Strike was entering Beta 5 at the end of the year, paving the way for the oft-remembered beta 5.3. Unreal Tournament and Quake III Arena were at the forefront of modern video game technology. Ultima Online had introduced massively multiplayer online RPGs to the world outside of the glorious text-based MUDs in ’97. This allowed EverQuest to be released in March of 1999, combining an FPS-like experience with the massive multiplayer online experience in a way that had never been seen before. QuakeSpy had picked up a couple more titles and was morphed into GameSpy.
Technology was exciting for gamers at the time as well. The Pentium 2 and AMD K6-2 were still trucking along as great processors. For the first time, OpenGL saw a competitor in Microsoft’s DirectX offering. Direct3D 7 offered hardware acceleration for transform and lighting as well as allowing vertex buffers to be stored in the hardware memory. The first card to take advantage of this was the GeForce 256, an incredible card for the time. Some other cards from the time that will surely bring back memories:
- Riva TNT22
- 3dfx Voodoo3
- Matrox G400
- ATI Rage 128
- S3 Savage 4
Who doesn’t remember digging through massiveComputer Shopper magazines looking at those things?
The Landscape of the Internet
Connecting to the Internet in 1999 opened up a world of different services and technologies. Whether you wanted to browse the World Wide Web, chat with friends over IRC, instant message someone over AIM / MSN / ICQ, download files from Usenet and IRC or that new Napster thing, connect to aggregation servers to find a game to play, or enter an online text-based world in a MUD, “the Internet” was not what most people consider it today.
Because of the relatively low average speed of Internet access, it would be unthinkable to have a web page coming in at a full megabyte or two worth of content. It would simply take far too long to load. I was able to find some mentions on the Internet that the average size of a site was around 60,000 bytes in 1999. That is 4% of the average page size of the top 1,000 sites today.
Browser Wars
Internet Explorer was the obvious king during 1999 but it wasn’t always like this.
Prior to Windows 95 and the Internet Explorer 1.0 offering they gave in their add-ons pack, Netscape had completely dominated the browser market on Macintosh and Windows platforms. Connecting to the Internet and browsing the web had become synonymous with the Netscape name and their nautical imagery of lighthouses and ship’s wheels. To get all the professional features, you had to pay money for your browser; a ludicrous idea today. When Microsoft started bundling a browser with their operating system for free, things started to heat up. Netscape realized that they had to be bigger and better since they couldn’t compete with the free price. Attempting to beat out Microsoft led Netscape down the road of developing some terribly buggy and horrendous browsing experiences with some versions of Netscape lasting on the market less than 6 months.
Thanks to the bumbling and fumbling of the Netscape brand and technology, the Mozilla Organization was formed in 1998 and the Netscape Communicator 4 source code was made open source which was a massive shift for the time. 1999 was a time when open source wasn’t as well known, particularly at the consumer level.
By February of 1999, Internet Explorer had taken over the web, accounting for 64.6% of traffic. Over the course of the next few years, their market domination would grow until Internet Explorer owned the browser space in 2004 with 95-96% of all web browsing. And we were all suffering through Internet Explorer 6. And it wasn’t good. I still find it amazing how much has changed in the browser space over the course of 15 years.
Content and the Rise of Web Hosting
Just a few years before 1999, the Internet was delivered in the flavor of the choosing of your provider. AOL had a version of the Internet with their own chat rooms, storefronts, websites, and content. CompuServe and others had theirs. Simply viewing HTML-based pages in a browser over the Internet on the World Wide Web was eventually made available to AOL users. But, as anyone who tried to pull up a website during those times could tell you: it was slow, clunky, and not where AOL et al. was trying to get their users to go. This walled-garden approach to the Internet was extremely popular before privately owned Internet Service Providers started popping up, offering simply a connection to the Internet. What you did once you were connected was up to you. This was a very different idea than the CompuServe and AOL days.
Before the popularity of shared hosting or even mentions of anything resembling “the cloud,” users of the Internet could find a spot for themselves on the World Wide Web at a number of free website hosts. Exchanging banner advertising for hosting megabytes, companies like Tripod, GeoCities and Angelfire started popping up. These companies increasingly offered more and more megabytes of content available for hosting as time went on. Eventually, they started offering additional features like email, or dynamic HTML elements and applets that would offer things like a “hit counter.”
Being 16 on the Internet in 1999
Before you turn 16 today, you’ve probably already created a massive online presence. Even younger kids have hundreds if not thousands of pieces of content on the Internet; whether it be photos, chats, messages, or anything else. Being in high school, you probably have a presence on multiple social networks. You’ve probably tried to start a a blog or two. More than likely, you’ve got a couple of AKAs on some forums or websites, multiple instant messaging nicknames and email addresses; a different persona, or 10.
Having a presence on the Internet, whether it be in chat rooms, on the World Wide Web, or in a video game, was definitely not the norm in 1999. Tools were just starting to come available to make this more and more popular, but mention HTML or a building a website to your peers in high school and you’d likely be finding yourself amongst the “geeks and nerds” social group. Keep in mind: being a geek or a nerd was in no way trendy or cool in 1999. Being a nerd then was a far cry from the kids today wearing fake glasses and proudly claiming their geek cred, or whatever the hell they call it.
Creating your own presence or website on the Internet was something you had to want to do on your own because there weren’t a lot of resources to help you along.Web Technologies in 1999
1999 saw the invention of the XMLHTTP ActiveX control in Internet Explorer 5. This new technology allowed for elements of a web page to update dynamically like stock quotes or news stories. This would eventually become the XMLHttpRequest that would power AJAX and the Web 2.0 movement a few years later in 2004. However, 1999 was the first mention of Web 2.0 when Darcy DiNucci laid out what would become the future of the World Wide Web in “Fragmented Future“:
“The first glimmerings of Web 2.0 are beginning to appear…Ironically, the defining trait of Web 2.0 will be that it won’t have any visible characteristics at all. The Web will be identified only by its underlying DNA structure — TCP/IP, HTTP, and URLs. As those technologies define its workings, the Web’s outward form—the hardware and software that we use to view it—will multiple. On the front end, the Web will fragment into countless permutations with different looks, behaviors, uses, and hardware hosts.”While Darcy certainly had a handle on how services would grow and evolve, she went on to say something that is particularly striking and true of today:
“The web will be understood not as screenfuls of text and graphics but as a transport mechanism, the ether through which interactivity happens.”Before Web 2.0
But, we weren’t there quite yet. Dynamic content on the web, so far, meant you needed to know some obscure technologies for some CGI handling (like PHP), or you knew Java and wrote massive and heavy applets that users would download. Learning these technologies generally meant going to a book store, paying a decent chunk of change for a book and set of disks (or CD), and sitting down on your own; just you, the author, and the computer as your resource. You couldn’t Google for the answer or head to Github to download a package to do what you wanted to do.
Because of the high barrier to entry for most dynamic programming tasks on the web, services like Bravenet offered different dynamic content that you could sign up for and include on your website. Some entire businesses and websites were built on the backs of such services like Bravenet forums.
Because the idea of a page ranking wasn’t really available, a counter was placed on most websites to list the number of visitors. This was a defining metric of the day, letting you know the difference between some site that someone just put on the web yesterday, and a bastion of information that had become popular and withstood the test of time, sporting thousands if not hundreds of thousands, or even millions of views. Even owners of websites relied on these counters to know, from day to day, whether people were visiting their websites. Google analytics or popular traffic stats packages simply weren’t readily available.
The Hitchhiker’s Guide to Medievia
Amongst this landscape of the Internet in 1999 is where I brought to life one of my earlier examples of dabbling with technology and programming. Hosted on Tripod, I created The Hitchhiker’s Guide to Medievia. This guide was meant to be a compendium of information for a popular MUD at the time called Medievia. Smattered throughout the pages are my hopes and dreams of content that will eventually appear on the guide, relics of the age of the web before Web 2.0 and many other hilarious things.
Why Did I Create the Page
I’ll let my 16 year old self explain the necessity of the page of the time from the Why page:
“It would contain maps of all the zones, lists of equipment, information about things that you probably don’t even care about, and it would all be created by one man…So, here it is. All of the information. It wasn’t created for me, but created for everyone. Created for all Medievians who ever had troubles finding the answer. I often found myself looking through every single web page in my bookmarks to try and find the thing I was looking for…A place that had all of the information. A place that had everything you needed. In short, a guide to Medievia. Well, welcome to that guide.”Because there was no Google to aggregate and sort through the depths of the World Wide Web, and Wikipedia had not yet popularized the idea of a “Wiki” for different types of information, it was up to individuals or organizations to compile information on their own.
The only good way you could find a website or content was for it to be linked to somewhere you already were.While there were tools available to search the web, they were nothing compared to the aggregation and auto-indexing that we see today. I was a huge fan of this particular game and there wasn’t a great source of information about it at the time for newbies or veterans of the game. So, I took it upon myself to do something about it.
From Minimal Design to Content Overload and Back Again
Looking back on my old static HTML code, my lack of abilities to use a database to create entries for dynamic pages, and the overall abundance of text with very little imagery, I can laugh at how we’ve come full circle in regards to web design.
When bandwidth started increasing and broadband started becoming more popular, the web became more and more chocked full of images, animated content, and eventually even more sophisticated media like videos and audio. As technologies became popular and available and the idea of using AJAX or similar technologies to move from static sites and page reloads to dynamic content got more adopted, the average website became more and more cluttered. Tons of images, videos, advertisements, animations, sounds, guestbooks, counters, and multiple technologies became the norm. A couple of years ago, people started developing plugins for browsers because the world wide web had simply become unweildy.
Today, we see designers touting that, at its core the Internet (as they call the World Wide Web these days) should go back to the time when text was the main content and an image or two was necessary. Typography has become the king again and we see minimalist blogging platforms with designs focused around the content and text becoming very popular, even trendy. Yet, as we look at a screenshot of the websites we were creating during the early days, we can see that it is at is always has been:
Spreading Open Source Before SourceForge
SourceForge, what would become the popular repository for open source projects to browse and download, had only been created in 1999. Before it was covered with ads and became a graveyard of old projects, SourceForge was an incredible resource. There weren’t any big repositories for open source software that were popular outside of academic or otherwise small circles of developers. Because of this, users who were gracious to software would often host or re-host tools to get them out there. This type of behavior can be seen on my DerekWare HTML Author page. Apparently, the original website for a piece of software had disappeared so I took it upon myself to re-host the application. From the sounds of things, my 16 year old self would have loved to have been introduced to Vim at an earlier age:
“It’s not a big fancy program with a bunch of point and click crap, it’s basically a window with some toolbars to make your life easier. Once you’ve been coding with HTML for a while you start to not really need the point and click stuff anymore and you’d much rather just type out everything. Well, this program allows for both. It’s easy to use, has some point and click stuff, and yet you can be advanced with it as well.”Online Presence Before Social Networks
Before a social network was the place to put all of your information about yourself, “A/S/L” was the common phrase in chat rooms. Age, sex, and language, was the basic information necessary to know the minimal details about someone in order to determine whether you wanted to create an interaction. You didn’t see a photo of the person, or get to read over their personal details prior. There was no place to go and find new friends or explore people in your area. Because of this, users would often create a page on their websites that would explain information about who created the content and offer an opportunity for the website creator to put themselves out there.
Here, I can see my 16 year old self, in a tiny little town in Montana, attempting to reach out to someone, anyone else, who actually had a computer connected to the Internet. There were only a handful of people in my tiny high school who even owned a computer, much less one with a modem, and even more rare: one connected to the Internet. On my Creator page, I list out what I feel is pertinent identifying information for the time. Age, height, weight, eye color. I even lament that doing so seems lame, but there really wasn’t any other avenue available at the time:
“So there you have it. That’s me in a nut shell. Well, actually, that’s more like my driver’s license info, but, it gets the point accross(sic).”Shopping Links that Work 15 Years Later
The name of the website was taken from a popular book called Hitchhiker’s Guide to the Galaxy. Because of this, I created a page dedicated to the inspiration. There, I provided 4 links to purchase the book. One from Amazon, one from Barnes & Noble, one for Borders and one for Buy.com. Surprisingly, two of those links have withstood the test of time, still linking to the correct content! Those links are:
The Internet, Today
What we consider “the Internet” today, the collection of technologies like email alongside the presence of the World Wide Web, has always been about trying to make a connection or create. As we find ourselves in an infinitely more connected world than we were 15 years ago, it’s easy to look around and find all sorts of ways that this philosophy or idea has come to fruition.
Imagine what the world would be like if everyone who wanted to create their place on the web, or connect to someone on the Internet, needed to learn a bit of HTML or borrow a bit of programming to do so. Today, the only requirement for being on the Internet is being born in a place that’s connected. Heck, your parents will probably put you on the Internet before you are even out of the womb.
For now, I’ll leave you with the footer of my old webpage. The contents of which are so indicative of the signs of the time:
Oh the times, how they have changed.
Liked this post? You should follow me on Twitter @randomdrake or subscribe to my feed.
↧
3delement – Lee Vermeulen
Comments:"3delement – Lee Vermeulen"
↧
Discrete States: Response to "Math is Not Necessary for Software Development"
Comments:"Discrete States: Response to "Math is Not Necessary for Software Development""
URL:http://discretestates.blogspot.com/2014/01/response-to-math-is-not-necessary-for.html
Ross Hunter recently wrote a blog entry on Mutually Human arguing that math is not necessary for being a good software developer. I agree with his thesis -- math isn't necessary. However, Ross shouldn't then jump to the conclusion that math isn't useful for software development. Math may not be necessary but it can certainly be useful.
(I would also like to correct Ross's description of discrete math. Ross implies that discrete math only consists of logic and boolean algebra. This is, of course, wrong -- discrete math covers a range of topics such as set theory, combinatorics, and graph theory as well.)
Math IS Useful:
Although math education is not necessary for software development, it is useful. I've already described how math teaches good problem solving skills and critical thinking. With the shift towards "internet scale" systems and big data, math is even more important than before.
I'll start by addressing relevant points in his argument and try to clear up perceived misconceptions.
First Argument:
- The skills that make a good mathematician are not the same as the skills that make for a good software developer.
- Math is the process of breaking down complex problems into simpler problems, recognizing patterns, and applying known formulae.
Math is often taught in a way where students learn how to solve problems by identifying patterns. Once the student identifies the pattern, they can solve the problem using the approach they memorized. It's unfortunate that math is taught this way because people like Ross come away with a very incomplete and distorted picture of math. I would call this "computation" rather than math.
The reason we have "known formulae" is precisely because of the practice of actual mathematics. In my mind, mathematics is the process of analyzing a formal system with logic. A mathematician starts by defining the basis of a formal system by specifying an initial set of rules by way of axioms, or statements which are held to be true without proof. Next, the mathematician recursively applies logic to determine what the implications of the axioms are and if any additional rules can be then be defined. As more and more rules are proven, the system becomes more powerful.
Often times, mathematicians will be looking to see if a specific rule can be implied from the initial set of axioms. If they find that this is not the case, the mathematicians may apply creative thinking to look for more specific cases where the rule does hold true or may change the axioms. A good example is the complex number system. When faced with the square roots of negative values, mathematicians had to define a new mathematical object (the imaginary number) to be able to reason about such results. This process can actually be quite creative.
Speaking from personal experience and comments made by others, a good math education can be a significant advantage. Reasoning through complex arguments and formal systems has made me much more detail oriented than I was before. Math has improved my problem solving skills. It's also enabled me to reason formally about software, which can be very important when developing distributed systems, for example.
It's unfortunate that the way math is often taught fails our students. Students are often taught the results found over thousands of years, but not the methodology for discovering the results. Classes like algebra, calculus, and introductory statistics are examples which focus on results rather than methodology. Unfortunately, these are also the most popular math classes since they are required in most high schools and college science majors!
Ross points out that he loved his discrete math class. Discrete math, along with others such as geometry, graph theory, and combinatorics, are much better courses for teaching students the methods rather than results. All of the subject material can be derived from a few simple definitions and axioms, giving students the opportunity to learn the mathematical process. Imagine the benefit for students if they were taught Real Analysis or Modern Algebra instead of calculus? As Ross rightly argues, in many cases, a solid foundation in logical thinking can more broadly applicable than calculus.
(I would also like to correct Ross's description of discrete math. Ross implies that discrete math only consists of logic and boolean algebra. This is, of course, wrong -- discrete math covers a range of topics such as set theory, combinatorics, and graph theory as well.)
Second Argument:
- In Math, there is only one right answer, but in software development, there is rarely a singular right answer.
Ross assumes that if a student is trained in mathematics, they will not be able to deal with grey situations. Maybe Ross assumes that people are only studying math? Or maybe he assumes that people are not capable of learning new ways of thinking or analyzing situations critically? Either way, this argument doesn't hold water.
Like any skill or way of thinking we have developed, learning where and when to apply it is an important part of gaining experience. Ideally, a student would also be exposed to the humanities or cutting edge problems in the sciences where there are not clear answers. (Science education faces a similar problem -- a focus on results, not methods.) Even if the student only studies math, it would be safe to assume that people can learn and adapt as they gain experience. That is fundamentally part of being human.
There are also cases where math rarely involves a single correct answer. A mathematician may have multiple ways of defining the initial axioms, each with their own trade offs. For example, there are variations on Euclidean geometry that change the initial axioms and end up with very different properties.
Math IS Useful:
Although math education is not necessary for software development, it is useful. I've already described how math teaches good problem solving skills and critical thinking. With the shift towards "internet scale" systems and big data, math is even more important than before.
Consider the case of evaluating and tuning a complex software system to squeeze out every last bit of performance. A well-controlled experiment and appropriate use of statistics is necessary to accurately access the response of the system under various conditions. A software developer doesn't want to waste time performance tuning the areas of the system contributing least to the run-time -- they want to know what's eating up all the time so they can use their time efficiently.
A better example would be the rise of machine learning and data mining. Users leak data left and right, which is collected by nearly every internet company. The data is then processed to predict what the user might like to target ads or improve the user experience. Machine learning is also used in the banking apps on our cell phones to read hand-written checks. The popularity of machine learning is exploding as more and more uses are found. I predict that many software developers will need to be proficient in machine learning techniques in the future. Since machine learning is based on math and statistics, there may be a time when most software developers will need to know some linear algebra, statistics, and calculus.
All Knowledge is Useful:
Every subject offers an opportunity to apply our skills in a new way and train our brains to be even better. One of the benefits of a liberal arts education is that students are expected to take a number of courses outside their major. A programmer who decides to study math, literature, history, or art may find that they have developed a number of skills and tools that traditional Computer Scientists lack.
So is Experience:
Experience is a great teacher, especially in software development. Spending hours debugging code is a great way to learn how a project works and to remember what caused the bug in the first case. The next time you see a similar bug, you won't have to spend nearly as much time hunting its source down.
Experience also offers the benefit of knowing what works best in practice. Ross points out that sometimes clever people will write code that is TOO clever. They have sacrificed readability and effort for laziness or intellectual satisfaction. This is not a problem of mathematicians, though. This is a problem that comes from a lack of experience.
In the end, I agree that math is not necessary for software development (yet) . I also think that we could and should change the required math courses for computer science majors to reflect courses that will focus on logic and reasoning. But, we shouldn't be attacking math or implying that it has no value. For some of us, math education has been a valuable part of our training.
↧
↧
KABOOM! Nearby Galaxy M82 Hosts a New Supernova!
Comments:"KABOOM! Nearby Galaxy M82 Hosts a New Supernova!"
The discovery image of the new supernova shows it's already quite bright.Photo by UCL/University of London Observatory/Steve Fossey/Ben Cooke/Guy Pollack/Matthew Wilde/Thomas Wright
I woke up to some great science news: A supernova has gone off in the nearby galaxy M82!
This is terribly exciting for astronomers. M82 is pretty close as galaxies go, less than 12 million light years away. That means we have an excellent view of one of the biggest explosions in the Universe, and we’ll be able to study it in great detail!
The supernova has the preliminary designation of PSN J09554214+6940260. I know, that’s awful—it’s based on the star’s coordinates—but it’ll get a name soon enough that’ll be easier on the eyes and brain.
Phil Plait writes Slate’s Bad Astronomy blog and is an astronomer, public speaker, science evangelizer, and author of Death from the Skies! Follow him on Twitter.
And just to get this out of the way, we’re in no danger from this explosion. It’s far too far away. Also, you won’t be able to just go outside, look up, and see it. Right now it’s too faint to see without a telescope. But the good news is it appears to have been discovered about two weeks before it hits peak brightness. Supernovae get brighter over time before fading away, and this one may get as bright as 8th magnitude, which is within range of binoculars. Right now it’s at about 12th magnitude; the faintest star you can see with your naked eye is about mag 6 (note that the numbers run backwards; a bigger number is a fainter object).
M82 is in Ursa Major, well placed for viewing right now in the Northern Hemisphere. Universe Today has a map to show you how to find it.
Another image of the supernova taken on Jan. 22, 2014Photo by Ernesto Guido, Nick Howes & Martino Nicolini
Here’s a funny thing, too. The supernova itself is what we call a Type Ia, a dwarf explosion. Astronomers are still trying to figure out exactly what happens in a Type Ia explosion, but there are three competing scenarios. Each involves a white dwarf, the small, dense, hot core left over after a star turns into a red giant, blows off its outer layers, and essentially “dies.” One scenario is that the white dwarf is orbiting a second star. It siphons off material from the star and accumulates it on its surface. Eventually this material gets so compressed by the huge gravity of the white dwarf that it fuses, creating a catastrophic explosion that tears the star apart.
Another is that two white dwarfs orbit each other. Eventually they spiral in, merge, and explode. The third, which is a recent idea, is that there are actually three stars in the system, a normal star and two white dwarfs. Due to the complex dance of gravity, the third star warps the orbits of the two dwarfs, and at some point they collide head-on! This too would result in a supernova explosion. All three scenarios involve very old stars, since it can take billions of years for a normal star to turn into a white dwarf.
A deep image of M82 shows gas and dust blasting out due to the fierce energy released when huge numbers of stars are born.Photo by Adam Block/Mount Lemmon SkyCenter/University of Arizona
What’s funny about this is that the galaxy M82 is undergoing a huge burst of star formation right now, and that means lots of massive stars are born. These live short lives and also explode as supernovae (called Type II, or core collapse) though the mechanism is very different from that of the white dwarf explosions. You’d expect M82 to have more core collapse supernovae, but this new one is a Type Ia.
And that’s actually more good news. These supernovae tend to all explode with the same energy, so they behave the same way whether they are near or far. We can see them for billions of light years away, which means they can be used to measure the distances of galaxies that are very far away. It was this kind of exploding star that allowed astronomers to discover dark energy, in fact. This energy is accelerating the expansion of the Universe, making it grow more every day. We don’t know a whole lot about it—it was only announced in 1998—but we’re learning more all the time. A nearby Type Ia means we can learn even more about these explosions, and hopefully calibrate our understanding even better.
During a weekly online virtual star party, an amateur astronomer actually caught the supernova on Jan. 19, 2014, before it was officially discovered! Click to watch the video.Photo by John Kramer c/o Fraser Cain
And that means we need observations! If you are an amateur astronomer, get images! And if you observed M82 recently, you may have “pre-discovery” images of it, taken before it was officially discovered. Those are critical for understanding the behavior of the supernova. If you do, report it to the CBAT (but make sure you read the instructions first; they don’t want images, just reports of magnitudes and so on).
Given the fact that it’s nearby, up high for so many observers, and caught so early, this may become one of the best-observed supernovae in modern times. I’m very excited this happened, and I hope to share more images and information with you soon!
Lots of sites have more info. Here are a few:
↧
DogecoinAverage - the price of Doge
↧
4k, HDMI, and Deep Color « tooNormal
Comments:"4k, HDMI, and Deep Color « tooNormal"
URL:http://www.toonormal.com/2014/01/10/4k-hdmi-and-deep-color/
As of this writing (January 2014), there are 2 HDMI specifications that support 4k Video (3840×2160 16:9). HDMI 1.4 and HDMI 2.0. As far as I know, there are currently no HDMI 2.0 capable TVs available in the market (though many were announced at CES this week).

Comparing HDMI 1.4 (Black text) and 2.0 (Orange). Source: HDMI 2.0 FAQ
A detail that’s tends to be neglected in all this 4k buzz is the Chroma Subsampling. If you’ve ever compared an HDMI signal against something else (DVI, VGA), and the quality looked worse, one of the reasons is because of Chroma Subsampling (for the other reason, see xvYCC at the bottom of this post).
Chroma Subsampling is extremely common. Practically every video you’ve ever watched on a computer or other digital video player uses it. As does the JPEG file format. That’s why we GameDevs prefer formats like PNG that don’t subsample. We like our source data raw and pristine. We can ruin it later with subsampling or other forms of texture compression (DXT/S3TC).
In the land of Subsampling, a descriptor like 4:4:4 or 4:2:2 is used. Images are broken up in to 4×2 pixel cells. The descriptor says how much color (chroma) data is lost. 4:4:4 is the perfect form of Chroma Subsampling. Chroma Subsampling uses the YCbCr color space (sometimes called YCC) as opposed to the standard RGB color space.

Great subsampling diagram from Wikipedia, showing the different encodings mean
Occasionally the term “4:4:4 RGB” or just “RGB” is used to describe the standard RGB color space. Also note, Component Video cables, though they are colored red, green, and blue, are actually YPbPr encoded (the Analog version of YCbCr).
Looking at the first diagram again, we can make a little more sense of it.
In other words:
- HDMI 1.4 supports 8bit RGB, 8bit 4:4:4 YCbCr, and 12bit 4:2:2 YCbCr, all at 24-30 FPS
- HDMI 2.0 supports RGB and 4:4:4 in all color depths (8bit-16bit) at 24-30 FPS
- HDMI 2.0 only supports 8bit RGB and 8bit 4:4:4 at 60 FPS
- All other color depths require Chroma Subsampling at 60 FPS in HDMI 2.0
- Peter Jackson’s 48 FPS (The Hobbit’s “High Frame Rate” HFR) is notably absent from the spec
Also worth noting, the most well supported color depths are 8bit and 12bit. The 12 bit over HDMI is referred to as Deep Color (as opposed to High Color).
The HDMI spec has supported only 4:4:4 and 4:2:2 since HDMI 1.0. As of HDMI 2.0, it also supports 4:2:0, which is available in HDMI 2.0′s 60 FPS framerates. Blu-ray movies are encoded in 4:2:0, so I’d assume this is why they added this.
All this video signal butchering does beg the question: Which is the better trade off? More color range per pixel, or more pixels with color channels?
I have no idea.
If I was to guess though, because TV’s aren’t right in front of your face like a Computer Monitor, I’d expect 4k 4:2:2 might actually be better. Greater luminance precision, with a bit of chroma fringing.
Some Plasma and LCD screens use something called Pentile Matrix arrangement of their red, green, and blue pixels.

The AMOLED screen of the Nexus One. A green for every pixel, but every other pixel is a blue, switching red/blue order every line. Not all AMOLED screens are Pentile. The Super AMOLED Plus screen found in the PS Vita uses a standard RGB layout
So even if we wanted more color fidelity per individual pixel, it may not be physically there.
Deep Color
Me, my latest graphics fascination is Deep Color. Deep Color is the marketing name for more than 8 bits per pixel of a color. It isn’t necessarily something we need in asset creation (not me, but some do want full 16bit color channels). But as we start running filters/shaders on our assets, stuff like HDR (but more than that), we end up losing the quality of the original assets as they are re-sampled to fit in to an 8bit RGB color space.
This can result in banding, especially in near flat color gradients.

From Wikipedia, though it’s possible the banding shown may be exaggerated
Photographers have RAW and HDR file formats for dealing with this stuff. We have Deep Color, in all its 30bit (10bpp), 36bit (12bpp) and 48bit (16bpp) glory. Or really, just 36bit (12bpp), but 48bit can be used as a RAW format if we wanted.
So the point of this nerding: An ideal display would be 4k, support 12bit RGB or 12bit YCbCr, at 60 FPS.
The thing is, HDMI 2.0 doesn’t support it!
Perhaps that’s fine though. Again, HDMI is a television spec. Most television viewers are watching video, and practically all video is 4:2:2 encoded anyway (which is supported by the HDMI 2.0 spec). The problem is gaming, where our framerates can reach 60FPS.
The HDMI 2.0 spec isn’t up to spec.![]()
Again this is probably fine. The now-current generation of consoles, nobody is really pushing them as 4k machines anyway. Sony may have 4k video playback support, but most high end games are still targeting 1080p and even 720p. 4k is 4x the pixels of 1080p. I suppose it’s an advantage that 4k only supports 30FPS right now, meaning you only need to push 2x the data to be a “4k game”, but still.
HDMI Bandwidth is rated in Gigabits per second.
- HDMI 1.0->1.2: ~4 Gb
- HDMI 1.3->1.4: ~8 Gb
- HDMI 2.0: ~14 Gb (NEW)
Not surprisingly, 4k 8bit 60FPS is ~12 Gb of data, and 30FPS is ~6 Gb of data. Our good friend 4k 12bit 60FPS though is ~18 Gb of data, well above the limits of HDMI 2.0.
To compare, Display Port.
- DisplayPort 1.0 and 1.1: ~8 Gb
- DisplayPort 1.2: ~17 Gb
- DisplayPort 1.3: ~32 Gb (NEW)
They’re claiming 8k and 4k@120Hz (FPS) support with the latest standard, but 18 doesn’t divide that well in to 32, so somebody has to have their numbers wrong (admittedly I did not divide mine by 1024, but 1000). Also since 8k is 4x the resolution of 4k, and the bandwidth only roughly doubled, practically speaking DisplayPort 1.3 can only support 8k 8bit 30FPS. Also that 4k@120Hz is 4k 8bit 120FPS. Still, if you don’t want 120FPS, that leaves room for 4k 16bit 60FPS, which should be more than needed (12bit). I wonder if anybody will support 4k 12bit 90FPS over DisplayPort?
And that’s 4k.
1080p and 2k Deep Color
Today 1080p is the dominant high resolution: 1920×1080. To the film guys, true 2k is 2048×1080, but there are a wide variety of devices in the same range, such as 2560×1600 and 2560×1440 (4x 720p). These, including 1080p, are often grouped under the label 2k.
A second of 1080p 8bit 60FPS data requires ~3 Gb of bandwidth, well within the range supported by the original HDMI 1.0 spec (though why we even had to deal with 1080i is a good question, probably due to the inability to even meet the HDMI spec).
To compare, a second of 1080p 12bit 60FPS data requires ~4.5 Gb of bandwidth. Even 1080p 16bit 60FPS needed only ~6 Gb, well within the range supported by HDMI 1.3 (where Deep Color was introduced). Plenty of headroom still. Only when we push 2560×1440 12bit 60FPS (~8 Gb) do we hit the limits of HDMI 1.3.
So from a specs perspective, I just wanted to note this because Deep Color and 1080p are reasonable to support on now-current generation game consoles. Even the PlayStation 3, by specs, supported this. High end games probably didn’t have enough processing to spare for this, but it’s something to definitely consider supporting on PlayStation 4 and Xbox One. As for PC, many current GPUs support Deep Color in full-screen resolutions. From what I briefly read, Deep Color is only supported on the Desktop with specialty cards (FirePro, etc).
One more thing: YCrCb (YCC) and xvYCC
You make have noticed watching a video file that the blacks don’t look very black.
Due to a horrible legacy thing (CRT displays), data encoded as YCrCb use values from 16->240 (15-235?) instead of 0->255. Thats quite the loss, nearly 12% of the available data range, effectively lowering the precision below 8bit. The only reason it’s still done is because of old CRT televisions, which can be really tough to find these days. Regrettably, that does mean both of the original DVD and Bluray movies standards were forced to comply to this.
Sony proposed x.v.Color (xvYCC) as a way of finally forgetting this stupid limitation of old CRT displays, and using the full 0->255 range. As of HDMI 1.3 (June 2006), xvYCC and Deep Color are part of the HDMI spec.
Several months later (November 2006), The PlayStation 3 was launched. So as a rule of thumb, only HDMI devices newer than the PlayStation 3 will could potentially support xvYCC. This means televisions, audio receivers, other set top boxes, etc. It’s worth noting that some audio receivers may actually clip video signals to the 16-240 range, thus ruining picture quality of an xvYCC source. Also the PS3 was eventually updated to HDMI 1.4 via a software update, but the only 1.4 feature supported is Stereoscopic 3D.
The point of bringing this up is to further emphasize the potential for color banding and terrible color reproduction over HDMI. An 8bit RGB framebuffer is potentially being compressed to fit within the YCbCr 16-240 range before it gets sent over HDMI. The PlayStation 3 has a setting for enabling the full color range (I forget the name used), and other new devices probably do to (unlikely named xvYCC).
According to Wikipedia, all of the Deep Color modes supported by HDMI 1.3 are xvYCC, as they should be.
This entry was posted on Friday, January 10th, 2014 at 5:16 PM and is filed under Technobabble. You can follow any responses to this entry through the RSS 2.0 feed. You can leave a response, or trackback from your own site.
↧