Imagine you’re a programmer who is developing a new web browser. There are many malicious sites on the web, and you want your browser to warn users when they attempt to access dangerous sites. For example, suppose the user attempts to access http://domain/etc. You’d like a way of checking whether domain is known to be a malicious site. What’s a good way of doing this?
An obvious naive way is for your browser to maintain a list or set data structure containing all known malicious domains. A problem with this approach is that it may consume a considerable amount of memory. If you know of a million malicious domains, and domains need (say) an average of 20 bytes to store, then you need 20 megabytes of storage. That’s quite an overhead for a single feature in your web browser. Is there a better way?
In this post I’ll describe a data structure which provides an excellent way of solving this kind of problem. The data structure is known as a Bloom filter. Bloom filter are much more memory efficient than the naive “store-everything” approach, while remaining extremely fast. I’ll describe both how Bloom filters work, and also some extensions of Bloom filters to solve more general problems.
Most explanations of Bloom filters cut to the chase, quickly explaining the detailed mechanics of how Bloom filters work. Such explanations are informative, but I must admit that they made me uncomfortable when I was first learning about Bloom filters. In particular, I didn’t feel that they helped me understand why Bloom filters are put together the way they are. I couldn’t fathom the mindset that would lead someone to invent such a data structure. And that left me feeling that all I had was a superficial, surface-level understanding of Bloom filters.
In this post I take an unusual approach to explaining Bloom filters. We won’t begin with a full-blown explanation. Instead, I’ll gradually build up to the full data structure in stages. My goal is to tell a plausible story explaining how one could invent Bloom filters from scratch, with each step along the way more or less “obvious”. Of course, hindsight is 20-20, and such a story shouldn’t be taken too literally. Rather, the benefit of developing Bloom filters in this way is that it will deepen our understanding of why Bloom filters work in just the way they do. We’ll explore some alternative directions that plausibly could have been taken – and see why they don’t work as well as Bloom filters ultimately turn out to work. At the end we’ll understand much better why Bloom filters are constructed the way they are.
Of course, this means that if your goal is just to understand the mechanics of Bloom filters, then this post isn’t for you. Instead, I’d suggest looking at a more conventional introduction – the Wikipedia article, for example, perhaps in conjunction with an interactive demo, like the nice one here. But if your goal is to understand why Bloom filters work the way they do, then you may enjoy the post.
A stylistic note: Most of my posts are code-oriented. This post is much more focused on mathematical analysis and algebraic manipulation: the point isn’t code, but rather how one could come to invent a particular data structure. That is, it’s the story behind the code that implements Bloom filters, and as such it requires rather more attention to mathematical detail.
General description of the problem: Let’s begin by abstracting away from the “safe web browsing” problem that began this post. We want a data structure which represents a set ![]() of objects. That data structure should enable two operations: (1) the ability to add an extra object
of objects. That data structure should enable two operations: (1) the ability to add an extra object ![]() to the set; and (2) a test to determine whether a given object
to the set; and (2) a test to determine whether a given object ![]() is a member of
is a member of ![]() . Of course, there are many other operations we might imagine wanting – for example, maybe we’d also like to be able to delete objects from the set. But we’re going to start with just these two operations of adding and testing. Later we’ll come back and ask whether operations such as deleteing objects are also possible.
. Of course, there are many other operations we might imagine wanting – for example, maybe we’d also like to be able to delete objects from the set. But we’re going to start with just these two operations of adding and testing. Later we’ll come back and ask whether operations such as deleteing objects are also possible.
Idea: store a set of hashed objects: Okay, so how can we solve the problem of representing ![]() in a way that’s more memory efficient than just storing all the objects in
in a way that’s more memory efficient than just storing all the objects in ![]() ? One idea is to store hashed versions of the objects in
? One idea is to store hashed versions of the objects in ![]() , instead of the full objects. If the hash function is well chosen, then the hashed objects will take up much less memory, but there will be little danger of making errors when testing whether an object is an element of the set or not.
, instead of the full objects. If the hash function is well chosen, then the hashed objects will take up much less memory, but there will be little danger of making errors when testing whether an object is an element of the set or not.
Let’s be a little more explicit about how this would work. We have a set ![]() of objects
of objects ![]() , where
, where ![]() denotes the number of objects in
denotes the number of objects in ![]() . For each object we compute an
. For each object we compute an ![]() -bit hash function
-bit hash function ![]() – i.e., a hash function which takes an arbitrary object as input, and outputs
– i.e., a hash function which takes an arbitrary object as input, and outputs ![]() bits – and the set
bits – and the set ![]() is represented by the set
is represented by the set ![]() . We can test whether
. We can test whether ![]() is an element of
is an element of ![]() by checking whether
by checking whether ![]() is in the set of hashes. This basic hashing approach requires roughly
is in the set of hashes. This basic hashing approach requires roughly ![]() bits of memory.
bits of memory.
(As an aside, in principle it’s possible to store the set of hashed objects more efficiently, using just ![]() bits, where
bits, where ![]() is to base two. The
is to base two. The ![]() saving is possible because the ordering of the objects in a set is redundant information, and so in principle can be eliminated using a suitable encoding. However, I haven’t thought through what encodings could be used to do this in practice. In any case, the saving is likely to be minimal, since
saving is possible because the ordering of the objects in a set is redundant information, and so in principle can be eliminated using a suitable encoding. However, I haven’t thought through what encodings could be used to do this in practice. In any case, the saving is likely to be minimal, since ![]() and
and ![]() will usually be quite a bit bigger than
will usually be quite a bit bigger than ![]() – if that weren’t the case, then hash collisions would occur all the time. So I’ll ignore the terms
– if that weren’t the case, then hash collisions would occur all the time. So I’ll ignore the terms ![]() for the rest of this post. In fact, in general I’ll be pretty cavalier in later analyses as well, omitting lower order terms without comment.)
for the rest of this post. In fact, in general I’ll be pretty cavalier in later analyses as well, omitting lower order terms without comment.)
A danger with this hash-based approach is that an object ![]() outside the set
outside the set ![]() might have the same hash value as an object inside the set, i.e.,
might have the same hash value as an object inside the set, i.e., ![]() for some
for some ![]() . In this case, test will erroneously report that
. In this case, test will erroneously report that ![]() is in
is in ![]() . That is, this data structure will give us a false positive. Fortunately, by choosing a suitable value for
. That is, this data structure will give us a false positive. Fortunately, by choosing a suitable value for ![]() , the number of bits output by the hash function, we can reduce the probability of a false positive as much as we want. To understand how this works, notice first that the probability of test giving a false positive is 1 minus the probability of test correctly reporting that
, the number of bits output by the hash function, we can reduce the probability of a false positive as much as we want. To understand how this works, notice first that the probability of test giving a false positive is 1 minus the probability of test correctly reporting that ![]() is not in
is not in ![]() . This occurs when
. This occurs when ![]() for all
for all ![]() . If the hash function is well chosen, then the probability that
. If the hash function is well chosen, then the probability that ![]() is
is ![]() for each
for each ![]() , and these are independent events. Thus the probability of test failing is:
, and these are independent events. Thus the probability of test failing is:
![]()
This expression involves three quantities: the probability ![]() of test giving a false positive, the number
of test giving a false positive, the number ![]() of bits output by the hash function, and the number of elements in the set,
of bits output by the hash function, and the number of elements in the set, ![]() . It’s a nice expression, but it’s more enlightening when rewritten in a slightly different form. What we’d really like to understand is how many bits of memory are needed to represent a set of size
. It’s a nice expression, but it’s more enlightening when rewritten in a slightly different form. What we’d really like to understand is how many bits of memory are needed to represent a set of size ![]() , with probability
, with probability ![]() of a test failing. To understand that we let
of a test failing. To understand that we let ![]() be the number of bits of memory used, and aim to express
be the number of bits of memory used, and aim to express ![]() as a function of
as a function of ![]() and
and ![]() . Observe that
. Observe that ![]() , and so we can substitute for
, and so we can substitute for ![]() to obtain
to obtain
![]()
This can be rearranged to express ![]() in term of
in term of ![]() and
and ![]() :
:
![]()
This expression answers the question we really want answered, telling us how many bits are required to store a set of size ![]() with a probability
with a probability ![]() of a test failing. Of course, in practice we’d like
of a test failing. Of course, in practice we’d like ![]() to be small – say
to be small – say ![]() – and when this is the case the expression may be approximated by a more transparent expression:
– and when this is the case the expression may be approximated by a more transparent expression:
![]()
This makes intuitive sense: test failure occurs when ![]() is not in
is not in ![]() , but
, but ![]() is in the hashed version of
is in the hashed version of ![]() . Because this happens with probability
. Because this happens with probability ![]() , it must be that
, it must be that ![]() occupies a fraction
occupies a fraction ![]() of the total space of possible hash outputs. And so the size of the space of all possible hash outputs must be about
of the total space of possible hash outputs. And so the size of the space of all possible hash outputs must be about ![]() . As a consequence we need
. As a consequence we need ![]() bits to represent each hashed object, in agreement with the expression above.
bits to represent each hashed object, in agreement with the expression above.
How memory efficient is this hash-based approach to representing ![]() ? It’s obviously likely to be quite a bit better than storing full representations of the objects in
? It’s obviously likely to be quite a bit better than storing full representations of the objects in ![]() . But we’ll see later that Bloom filters can be far more memory efficient still.
. But we’ll see later that Bloom filters can be far more memory efficient still.
The big drawback of this hash-based approach is the false positives. Still, for many applications it’s fine to have a small probability of a false positive. For example, false positives turn out to be okay for the safe web browsing problem. You might worry that false positives would cause some safe sites to erroneously be reported as unsafe, but the browser can avoid this by maintaining a (small!) list of safe sites which are false positives for test.
Idea: use a bit array: Suppose we want to represent some subset ![]() of the integers
of the integers ![]() . As an alternative to hashing or to storing
. As an alternative to hashing or to storing ![]() directly, we could represent
directly, we could represent ![]() using an array of
using an array of ![]() bits, numbered
bits, numbered ![]() through
through ![]() . We would set bits in the array to
. We would set bits in the array to ![]() if the corresponding number is in
if the corresponding number is in ![]() , and otherwise set them to
, and otherwise set them to ![]() . It’s obviously trivial to add objects to
. It’s obviously trivial to add objects to ![]() , and to test whether a particular object is in
, and to test whether a particular object is in ![]() or not.
or not.
The memory cost to store ![]() in this bit-array approach is
in this bit-array approach is ![]() bits, regardless of how big or small
bits, regardless of how big or small ![]() is. Suppose, for comparison, that we stored
is. Suppose, for comparison, that we stored ![]() directly as a list of 32-bit integers. Then the cost would be
directly as a list of 32-bit integers. Then the cost would be ![]() bits. When
bits. When ![]() is very small, this approach would be more memory efficient than using a bit array. But as
is very small, this approach would be more memory efficient than using a bit array. But as ![]() gets larger, storing
gets larger, storing ![]() directly becomes much less memory efficient. We could ameliorate this somewhat by storing elements of
directly becomes much less memory efficient. We could ameliorate this somewhat by storing elements of ![]() using only 10 bits, instead of 32 bits. But even if we did this, it would still be more expensive to store the list once
using only 10 bits, instead of 32 bits. But even if we did this, it would still be more expensive to store the list once ![]() got beyond one hundred elements. So a bit array really would be better for modestly large subsets.
got beyond one hundred elements. So a bit array really would be better for modestly large subsets.
Idea: use a bit array where the indices are given by hashes: A problem with the bit array example described above is that we needed a way of numbering the possible elements of ![]() ,
, ![]() . In general the elements of
. In general the elements of ![]() may be complicated objects, not numbers in a small, well-defined range.
may be complicated objects, not numbers in a small, well-defined range.
Fortunately, we can use hashing to number the elements of ![]() . Suppose
. Suppose ![]() is an
is an ![]() -bit hash function. We’re going to represent a set
-bit hash function. We’re going to represent a set ![]() using a bit array containing
using a bit array containing ![]() elements. In particular, for each
elements. In particular, for each ![]() we set the
we set the ![]() th element in the bit array, where we regard
th element in the bit array, where we regard ![]() as a number in the range
as a number in the range ![]() . More explicitly, we can add an element
. More explicitly, we can add an element ![]() to the set by setting bit number
to the set by setting bit number ![]() in the bit array. And we can test whether
in the bit array. And we can test whether ![]() is an element of
is an element of ![]() by checking whether bit number
by checking whether bit number ![]() in the bit array is set.
in the bit array is set.
This is a good scheme, but the test can fail to give the correct result, which occurs whenever ![]() is not an element of
is not an element of ![]() , yet
, yet ![]() for some
for some ![]() . This is exactly the same failure condition as for the basic hashing scheme we described earlier. By exactly the same reasoning as used then, the failure probability is
. This is exactly the same failure condition as for the basic hashing scheme we described earlier. By exactly the same reasoning as used then, the failure probability is
![]()
As we did earlier, we’d like to re-express this in terms of the number of bits of memory used, ![]() . This works differently than for the basic hashing scheme, since the number of bits of memory consumed by the current approach is
. This works differently than for the basic hashing scheme, since the number of bits of memory consumed by the current approach is ![]() , as compared to
, as compared to ![]() for the earlier scheme. Using
for the earlier scheme. Using ![]() and substituting for
and substituting for ![]() in Equation [*], we have:
in Equation [*], we have:
![]()
Rearranging this to express ![]() in term of
in term of ![]() and
and ![]() we obtain:
we obtain:
![]()
When ![]() is small this can be approximated by
is small this can be approximated by
![]()
This isn’t very memory efficient! We’d like the probability of failure ![]() to be small, and that makes the
to be small, and that makes the ![]() dependence bad news when compared to the
dependence bad news when compared to the ![]() dependence of the basic hashing scheme described earlier. The only time the current approach is better is when
dependence of the basic hashing scheme described earlier. The only time the current approach is better is when ![]() is very, very large. To get some idea for just how large, if we want
is very, very large. To get some idea for just how large, if we want ![]() , then
, then ![]() is only better than
is only better than ![]() when
when ![]() gets to be more than about
gets to be more than about ![]() . That’s quite a set! In practice, the basic hashing scheme will be much more memory efficient.
. That’s quite a set! In practice, the basic hashing scheme will be much more memory efficient.
Intuitively, it’s not hard to see why this approach is so memory inefficient compared to the basic hashing scheme. The problem is that with an ![]() -bit hash function, the basic hashing scheme used
-bit hash function, the basic hashing scheme used ![]() bits of memory, while hashing into a bit array uses
bits of memory, while hashing into a bit array uses ![]() bits, but doesn’t change the probability of failure. That’s exponentially more memory!
bits, but doesn’t change the probability of failure. That’s exponentially more memory!
At this point, hashing into bit arrays looks like a bad idea. But it turns out that by tweaking the idea just a little we can improve it a lot. To carry out this tweaking, it helps to name the data structure we’ve just described (where we hash into a bit array). We’ll call it a filter, anticipating the fact that it’s a precursor to the Bloom filter. I don’t know whether “filter” is a standard name, but in any case it’ll be a useful working name.
Idea: use multiple filters: How can we make the basic filter just described more memory efficient? One possibility is to try using multiple filters, based on independent hash functions. More precisely, the idea is to use ![]() filters, each based on an (independent)
filters, each based on an (independent) ![]() -bit hash function,
-bit hash function, ![]() . So our data structure will consist of
. So our data structure will consist of ![]() separate bit arrays, each containing
separate bit arrays, each containing ![]() bits, for a grand total of
bits, for a grand total of ![]() bits. We can add an element
bits. We can add an element ![]() by setting the
by setting the ![]() th bit in the first bit array (i.e., the first filter), the
th bit in the first bit array (i.e., the first filter), the ![]() th bit in the second filter, and so on. We can test whether a candidate element
th bit in the second filter, and so on. We can test whether a candidate element ![]() is in the set by simply checking whether all the appropriate bits are set in each filter. For this to fail, each individual filter must fail. Because the hash functions are independent of one another, the probability of this is the
is in the set by simply checking whether all the appropriate bits are set in each filter. For this to fail, each individual filter must fail. Because the hash functions are independent of one another, the probability of this is the ![]() th power of any single filter failing:
th power of any single filter failing:
![]()
The number of bits of memory used by this data structure is ![]() and so we can substitute
and so we can substitute ![]() and rearrange to get
and rearrange to get
![]()
Provided ![]() is much smaller than
is much smaller than ![]() , this expression can be simplified to give
, this expression can be simplified to give
![]()
Good news! This repetition strategy is much more memory efficient than a single filter, at least for small values of ![]() . For instance, moving from
. For instance, moving from ![]() repetitions to
repetitions to ![]() repititions changes the denominator from
repititions changes the denominator from ![]() to
to ![]() – typically, a huge improvement, since
– typically, a huge improvement, since ![]() is very small. And the only price paid is doubling the numerator. So this is a big win.
is very small. And the only price paid is doubling the numerator. So this is a big win.
Intuitively, and in retrospect, this result is not so surprising. Putting multiple filters in a row, the probability of error drops exponentially with the number of filters. By contrast, in the single filter scheme, the drop in the probability of error is roughly linear with the number of bits. (This follows from considering Equation [*] in the limit where ![]() is small.) So using multiple filters is a good strategy.
is small.) So using multiple filters is a good strategy.
Of course, a caveat to the last paragraph is that this analysis requires that ![]() , which means that
, which means that ![]() can’t be too large before the analysis breaks down. For larger values of
can’t be too large before the analysis breaks down. For larger values of ![]() the analysis is somewhat more complicated. In order to find the optimal value of
the analysis is somewhat more complicated. In order to find the optimal value of ![]() we’d need to figure out what value of
we’d need to figure out what value of ![]() minimizes the exact expression [**] for
minimizes the exact expression [**] for ![]() . We won’t bother – at best it’d be tedious, and, as we’ll see shortly, there is in any case a better approach.
. We won’t bother – at best it’d be tedious, and, as we’ll see shortly, there is in any case a better approach.
Overlapping filters: This is a variation on the idea of repeating filters. Instead of having ![]() separate bit arrays, we use just a single array of
separate bit arrays, we use just a single array of ![]() bits. When adding an object
bits. When adding an object ![]() , we simply set all the bits
, we simply set all the bits ![]() in the same bit array. To test whether an element
in the same bit array. To test whether an element ![]() is in the set, we simply check whether all the bits
is in the set, we simply check whether all the bits ![]() are set or not.
are set or not.
What’s the probability of the test failing? Suppose ![]() . Failure occurs when
. Failure occurs when ![]() for some
for some ![]() and
and ![]() , and also
, and also ![]() for some
for some ![]() and
and ![]() , and so on for all the remaining hash functions,
, and so on for all the remaining hash functions, ![]() . These are independent events, and so the probability they all occur is just the product of the probabilities of the individual events. A little thought should convince you that each individual event will have the same probability, and so we can just focus on computing the probability that
. These are independent events, and so the probability they all occur is just the product of the probabilities of the individual events. A little thought should convince you that each individual event will have the same probability, and so we can just focus on computing the probability that ![]() for some
for some ![]() and
and ![]() . The overall probability
. The overall probability ![]() of failure will then be the
of failure will then be the ![]() th power of that probability, i.e.,
th power of that probability, i.e.,
![]()
The probability that ![]() for some
for some ![]() and
and ![]() is one minus the probability that
is one minus the probability that ![]() for all
for all ![]() and
and ![]() . These are independent events for the different possible values of
. These are independent events for the different possible values of ![]() and
and ![]() , each with probability
, each with probability ![]() , and so
, and so
![]()
since there are ![]() different pairs of possible values
different pairs of possible values ![]() . It follows that
. It follows that
![]()
Substituting ![]() we obtain
we obtain
![]()
which can be rearranged to obtain
![]()
This is remarkably similar to the expression [**] derived above for repeating filters. In fact, provided ![]() is much smaller than
is much smaller than ![]() , we get
, we get
![]()
which is exactly the same as [**] when ![]() is small. So this approach gives quite similar outcomes to the repeating filter strategy.
is small. So this approach gives quite similar outcomes to the repeating filter strategy.
Which approach is better, repeating or overlapping filters? In fact, it can be shown that
![]()
and so the overlapping filter strategy is more memory efficient than the repeating filter strategy. I won’t prove the inequality here – it’s a straightforward (albeit tedious) exercise in calculus. The important takeaway is that overlapping filters are the more memory-efficient approach.
How do overlapping filters compare to our first approach, the basic hashing strategy? I’ll defer a full answer until later, but we can get some insight by choosing ![]() and
and ![]() . Then for the overlapping filter we get
. Then for the overlapping filter we get ![]() , while the basic hashing strategy gives
, while the basic hashing strategy gives ![]() . Basic hashing is worse whenever
. Basic hashing is worse whenever ![]() is more than about 100 million – a big number, but also a big improvement over the
is more than about 100 million – a big number, but also a big improvement over the ![]() required by a single filter. Given that we haven’t yet made any attempt to optimize
required by a single filter. Given that we haven’t yet made any attempt to optimize ![]() , this ought to encourage us that we’re onto something.
, this ought to encourage us that we’re onto something.
Problems for the author
- I suspect that there’s a simple intuitive argument that would let us see upfront that overlapping filters will be more memory efficient than repeating filters. Can I find such an argument?
Bloom filters: We’re finally ready for Bloom filters. In fact, Bloom filters involve only a few small changes to overlapping filters. In describing overlapping filters we hashed into a bit array containing ![]() bits. We could, instead, have used hash functions with a range
bits. We could, instead, have used hash functions with a range ![]() and hashed into a bit array of
and hashed into a bit array of ![]() (instead of
(instead of ![]() ) bits. The analysis goes through unchanged if we do this, and we end up with
) bits. The analysis goes through unchanged if we do this, and we end up with
![]()
and
![]()
exactly as before. The only reason I didn’t do this earlier is because in deriving Equation [*] above it was convenient to re-use the reasoning from the basic hashing scheme, where ![]() (not
(not ![]() ) was the convenient parameter to use. But the exact same reasoning works.
) was the convenient parameter to use. But the exact same reasoning works.
What’s the best value of ![]() to choose? Put another way, what value of
to choose? Put another way, what value of ![]() should we choose in order to minimize the number of bits,
should we choose in order to minimize the number of bits, ![]() , given a particular value for the probability of error,
, given a particular value for the probability of error, ![]() , and a particular sizek
, and a particular sizek ![]() ? Equivalently, what value of
? Equivalently, what value of ![]() will minimize
will minimize ![]() , given
, given ![]() and
and ![]() ? I won’t go through the full analysis here, but with calculus and some algebra you can show that choosing
? I won’t go through the full analysis here, but with calculus and some algebra you can show that choosing
![]()
minimizes the probability ![]() . (Note that
. (Note that ![]() denotes the natural logarithm, not logarithms to base 2.) By choosing
denotes the natural logarithm, not logarithms to base 2.) By choosing ![]() in this way we get:
in this way we get:
![]()
This really is good news! Not only is it better than a bit array, it’s actually (usually) much better than the basic hashing scheme we began with. In particular, it will be better whenever
![]()
which is equivalent to requiring
![]()
If we want (say) ![]() this means that Bloom filter will be better whenever
this means that Bloom filter will be better whenever ![]() , which is obviously an extremely modest set size.
, which is obviously an extremely modest set size.
Another way of interpreting [***] is that a Bloom filter requires ![]() bits per element of the set being represented. In fact, it’s possible to prove that any data structure supporting the add and test operations will require at least
bits per element of the set being represented. In fact, it’s possible to prove that any data structure supporting the add and test operations will require at least ![]() bits per element in the set. This means that Bloom filters are near-optimal. Futher work has been done finding even more memory-efficient data structures that actually meet the
bits per element in the set. This means that Bloom filters are near-optimal. Futher work has been done finding even more memory-efficient data structures that actually meet the ![]() bound. See, for example, the paper by Anna Pagh, Rasmus Pagh, and S. Srinivasa Rao.
bound. See, for example, the paper by Anna Pagh, Rasmus Pagh, and S. Srinivasa Rao.
Problems for the author
- Are the more memory-efficient algorithms practical? Should we be using them?
In actual applications of Bloom filters, we won’t know ![]() in advance, nor
in advance, nor ![]() . So the way we usually specify a Bloom filter is to specify the maximum size
. So the way we usually specify a Bloom filter is to specify the maximum size ![]() of set that we’d like to be able to represent, and the maximal probability of error,
of set that we’d like to be able to represent, and the maximal probability of error, ![]() , that we’re willing to tolerate. Then we choose
, that we’re willing to tolerate. Then we choose
![]()
and
![]()
This gives us a Bloom filter capable of representing any set up to size ![]() , with probability of error guaranteed to be at most
, with probability of error guaranteed to be at most ![]() . The size
. The size ![]() is called the capacity of the Bloom filter. Actually, these expressions are slight simplifications, since the terms on the right may not be integers – to be a little more pedantic, we choose
is called the capacity of the Bloom filter. Actually, these expressions are slight simplifications, since the terms on the right may not be integers – to be a little more pedantic, we choose
![]()
and
![]()
One thing that still bugs me about Bloom filters is the expression for the optimal value for ![]() . I don’t have a good intuition for it – why is it logarithmic in
. I don’t have a good intuition for it – why is it logarithmic in ![]() , and why does it not depend on
, and why does it not depend on ![]() ? There’s a tradeoff going on here that’s quite strange when you think about it: bit arrays on their own aren’t very good, but if you repeat or overlap them just the right number of times, then performance improves a lot. And so you can think of Bloom filters as a kind of compromise between an overlap strategy and a bit array strategy. But it’s really not at all obvious (a) why choosing a compromise strategy is the best; or (b) why the right point at which to compromise is where it is, i.e., why
? There’s a tradeoff going on here that’s quite strange when you think about it: bit arrays on their own aren’t very good, but if you repeat or overlap them just the right number of times, then performance improves a lot. And so you can think of Bloom filters as a kind of compromise between an overlap strategy and a bit array strategy. But it’s really not at all obvious (a) why choosing a compromise strategy is the best; or (b) why the right point at which to compromise is where it is, i.e., why ![]() has the form it does. I can’t quite answer these questions at this point – I can’t see that far through Bloom filters. I suspect that understanding the
has the form it does. I can’t quite answer these questions at this point – I can’t see that far through Bloom filters. I suspect that understanding the ![]() case really well would help, but haven’t put in the work. Anyone with more insight is welcome to speak up!
case really well would help, but haven’t put in the work. Anyone with more insight is welcome to speak up!
Summing up Bloom filters: Let’s collect everything together. Suppose we want a Bloom filter with capacity ![]() , i.e., capable of representing any set
, i.e., capable of representing any set ![]() containing up to
containing up to ![]() elements, and such that test produces a false positive with probability at most
elements, and such that test produces a false positive with probability at most ![]() . Then we choose
. Then we choose
![]()
independent hash functions, ![]() . Each hash function has a range
. Each hash function has a range ![]() , where
, where ![]() is the number of bits of memory our Bloom filter requires,
is the number of bits of memory our Bloom filter requires,
![]()
We number the bits in our Bloom filter from ![]() . To add an element
. To add an element ![]() to our set we set the bits
to our set we set the bits ![]() in the filter. And to test whether a given element
in the filter. And to test whether a given element ![]() is in the set we simply check whether bits
is in the set we simply check whether bits ![]() in the bit array are all set.
in the bit array are all set.
That’s all there is to the mechanics of how Bloom filters work! I won’t give any sample code – I usually provide code samples in Python, but the Python standard library lacks bit arrays, so nearly all of the code would be concerned with defining a bit array class. That didn’t seem like it’d be terribly illuminating. Of course, it’s not difficult to find libraries implementing Bloom filters. For example, Jason Davies has written a javascript Bloom filter which has a fun and informative online interactive visualisation. I recommend checking it out. And I’ve personally used Mike Axiak‘s fast C-based Python library pybloomfiltermmap– the documentation is clear, it took just a few minutes to get up and running, and I’ve generally had no problems.
Problems
Applications of Bloom filters: Bloom filters have been used to solve many different problems. Here’s just a few examples to give the flavour of how they can be used. An early idea was Manber and Wu’s 1994 proposal to use Bloom filters to store lists of weak passwords. Google’s BigTable storage system uses Bloom filters to speed up queries, by avoiding disk accesses for rows or columns that don’t exist. Google Chrome uses Bloom filters to do safe web browsing– the opening example in this post was quite real! More generally, it’s useful to consider using Bloom filters whenever a large collection of objects needs to be stored. They’re not appropriate for all purposes, but at the least it’s worth thinking about whether or not a Bloom filter can be applied.
Extensions of Bloom filters: There’s many clever ways of extending Bloom filters. I’ll briefly describe one, just to give you the flavour, and provide links to several more.
A delete operation: It’s possible to modify Bloom filters so they support a delete operation that lets you remove an element from the set. You can’t do this with a standard Bloom filter: it would require unsetting one or more of the bits ![]() in the bit array. This could easily lead us to accidentally delete other elements in the set as well.
in the bit array. This could easily lead us to accidentally delete other elements in the set as well.
Instead, the delete operation is implemented using an idea known as a counting Bloom filter. The basic idea is to take a standard Bloom filter, and replace each bit in the bit array by a bucket containing several bits (usually 3 or 4 bits). We’re going to treat those buckets as counters, initially set to ![]() . We add an element
. We add an element ![]() to the counting Bloom filter by incrementing each of the buckets numbered
to the counting Bloom filter by incrementing each of the buckets numbered ![]() . We test whether
. We test whether ![]() is in the counting Bloom filter by looking to see whether each of the corresponding buckets are non-zero. And we delete
is in the counting Bloom filter by looking to see whether each of the corresponding buckets are non-zero. And we delete ![]() by decrementing each bucket.
by decrementing each bucket.
This strategy avoids the accidental deletion problem, because when two elements of the set ![]() and
and ![]() hash into the same bucket, the count in that bucket will be at least
hash into the same bucket, the count in that bucket will be at least ![]() . deleteing one of the elements, say
. deleteing one of the elements, say ![]() , will still leave the count for the bucket at least
, will still leave the count for the bucket at least ![]() , so
, so ![]() won’t be accidentally deleted. Of course, you could worry that this will lead us to erroneously conclude that
won’t be accidentally deleted. Of course, you could worry that this will lead us to erroneously conclude that ![]() is still in the set after it’s been deleted. But that can only happen if other elements in the set hash into every single bucket that
is still in the set after it’s been deleted. But that can only happen if other elements in the set hash into every single bucket that ![]() hashes into. That will only happen if
hashes into. That will only happen if ![]() is very large.
is very large.
Of course, that’s just the basic idea behind counting Bloom filters. A full analysis requires us to understand issues such as bucket overflow (when a counter gets incremented too many times), the optimal size for buckets, the probability of errors, and so on. I won’t get into that, but you there’s details in the further reading, below.
Other variations and further reading: There are many more variations on Bloom filters. Just to give you the flavour of a few applications: (1) they can be modified to be used as lookup dictionaries, associating a value with each element added to the filter; (2) they can be modified so that the capacity scales up dynamically; and (3) they can be used to quickly approximate the number of elements in a set. There are many more variations as well: Bloom filters have turned out to be a very generative idea! This is part of why it’s useful to understand them deeply, since even if a standard Bloom filter can’t solve the particular problem you’re considering, it may be possible to come up with a variation which does. You can get some idea of the scope of the known variations by looking at the Wikipedia article. I also like the survey article by Andrei Broder and Michael Mitzenmacher. It’s a little more dated (2004) than the Wikipedia article, but nicely written and a good introduction. For a shorter introduction to some variations, there’s also a recent blog post by Matthias Vallentin. You can get the flavour of current research by looking at some of the papers citing Bloom filters here. Finally, you may enjoy reading the original paper on Bloom filters, as well as the original paper on counting Bloom filters.
Understanding data structures: I wrote this post because I recently realized that I didn’t understand any complex data structure in any sort of depth. There are, of course, a huge number of striking data structures in computer science – just look at Wikipedia’s amazing list! And while I’m familiar with many of the simpler data structures, I’m ignorant of most complex data structures. There’s nothing wrong with that – unless one is a specialist in data structures there’s no need to master a long laundry list. But what bothered me is that I hadn’t thoroughly mastered even a single complex data structure. In some sense, I didn’t know what it means to understand a complex data structure, at least beyond surface mechanics. By trying to reinvent Bloom filters, I’ve found that I’ve deepened my own understanding and, I hope, written something of interest to others.
Interested in more? Please subscribe to this blog, or follow me on Twitter. You may also enjoy reading my new book about open science, Reinventing Discovery.



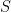 of objects. That data structure should enable two operations: (1) the ability to add an extra object
of objects. That data structure should enable two operations: (1) the ability to add an extra object  to the set; and (2) a test to determine whether a given object
to the set; and (2) a test to determine whether a given object  , where
, where  denotes the number of objects in
denotes the number of objects in  -bit hash function
-bit hash function  – i.e., a hash function which takes an arbitrary object as input, and outputs
– i.e., a hash function which takes an arbitrary object as input, and outputs  . We can test whether
. We can test whether  is in the set of hashes. This basic hashing approach requires roughly
is in the set of hashes. This basic hashing approach requires roughly  bits of memory.
bits of memory. bits, where
bits, where  is to base two. The
is to base two. The  saving is possible because the ordering of the objects in a set is redundant information, and so in principle can be eliminated using a suitable encoding. However, I haven’t thought through what encodings could be used to do this in practice. In any case, the saving is likely to be minimal, since
saving is possible because the ordering of the objects in a set is redundant information, and so in principle can be eliminated using a suitable encoding. However, I haven’t thought through what encodings could be used to do this in practice. In any case, the saving is likely to be minimal, since  and
and  – if that weren’t the case, then hash collisions would occur all the time. So I’ll ignore the terms
– if that weren’t the case, then hash collisions would occur all the time. So I’ll ignore the terms  for some
for some 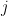 . In this case, test will erroneously report that
. In this case, test will erroneously report that  for all
for all  for each
for each 
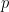 of test giving a false positive, the number
of test giving a false positive, the number  be the number of bits of memory used, and aim to express
be the number of bits of memory used, and aim to express  , and so we can substitute for
, and so we can substitute for  to obtain
to obtain

 – and when this is the case the expression may be approximated by a more transparent expression:
– and when this is the case the expression may be approximated by a more transparent expression:
 . As a consequence we need
. As a consequence we need  bits to represent each hashed object, in agreement with the expression above.
bits to represent each hashed object, in agreement with the expression above.  . As an alternative to hashing or to storing
. As an alternative to hashing or to storing  bits, numbered
bits, numbered 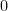 through
through  . We would set bits in the array to
. We would set bits in the array to  if the corresponding number is in
if the corresponding number is in  bits. When
bits. When  . In general the elements of
. In general the elements of  is an
is an  using a bit array containing
using a bit array containing  elements. In particular, for each
elements. In particular, for each  we set the
we set the  . More explicitly, we can add an element
. More explicitly, we can add an element 
 , as compared to
, as compared to 


 dependence bad news when compared to the
dependence bad news when compared to the  . That’s quite a set! In practice, the basic hashing scheme will be much more memory efficient.
. That’s quite a set! In practice, the basic hashing scheme will be much more memory efficient. bits of memory, while hashing into a bit array uses
bits of memory, while hashing into a bit array uses 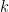 filters, each based on an (independent)
filters, each based on an (independent)  . So our data structure will consist of
. So our data structure will consist of  bits. We can add an element
bits. We can add an element  th bit in the first bit array (i.e., the first filter), the
th bit in the first bit array (i.e., the first filter), the  th bit in the second filter, and so on. We can test whether a candidate element
th bit in the second filter, and so on. We can test whether a candidate element 
 and rearrange to get
and rearrange to get
 is much smaller than
is much smaller than 
 repetitions to
repetitions to  repititions changes the denominator from
repititions changes the denominator from  – typically, a huge improvement, since
– typically, a huge improvement, since  is small.) So using multiple filters is a good strategy.
is small.) So using multiple filters is a good strategy. , which means that
, which means that  in the same bit array. To test whether an element
in the same bit array. To test whether an element  . Failure occurs when
. Failure occurs when  for some
for some  and
and  , and also
, and also  for some
for some  and
and  , and so on for all the remaining hash functions,
, and so on for all the remaining hash functions,  . These are independent events, and so the probability they all occur is just the product of the probabilities of the individual events. A little thought should convince you that each individual event will have the same probability, and so we can just focus on computing the probability that
. These are independent events, and so the probability they all occur is just the product of the probabilities of the individual events. A little thought should convince you that each individual event will have the same probability, and so we can just focus on computing the probability that 
 for all
for all  , and so
, and so
 different pairs of possible values
different pairs of possible values  . It follows that
. It follows that
 we obtain
we obtain



 and
and  . Then for the overlapping filter we get
. Then for the overlapping filter we get  , while the basic hashing strategy gives
, while the basic hashing strategy gives  . Basic hashing is worse whenever
. Basic hashing is worse whenever  and hashed into a bit array of
and hashed into a bit array of  (instead of
(instead of 

 denotes the natural logarithm, not logarithms to base 2.) By choosing
denotes the natural logarithm, not logarithms to base 2.) By choosing 


 this means that Bloom filter will be better whenever
this means that Bloom filter will be better whenever  , which is obviously an extremely modest set size.
, which is obviously an extremely modest set size. bits per element of the set being represented. In fact, it’s possible to prove that any data structure supporting the add and test operations will require at least
bits per element of the set being represented. In fact, it’s possible to prove that any data structure supporting the add and test operations will require at least  bits per element in the set. This means that Bloom filters are near-optimal. Futher work has been done finding even more memory-efficient data structures that actually meet the
bits per element in the set. This means that Bloom filters are near-optimal. Futher work has been done finding even more memory-efficient data structures that actually meet the  of set that we’d like to be able to represent, and the maximal probability of error,
of set that we’d like to be able to represent, and the maximal probability of error, 




 , where
, where 
 in the filter. And to test whether a given element
in the filter. And to test whether a given element  in the bit array. This could easily lead us to accidentally delete other elements in the set as well.
in the bit array. This could easily lead us to accidentally delete other elements in the set as well. hash into the same bucket, the count in that bucket will be at least
hash into the same bucket, the count in that bucket will be at least  . deleteing one of the elements, say
. deleteing one of the elements, say 









